Saturday, 01 August
20:21
19:14
Of course I love RSS. ;-)
18:28
Ultimately AI will flatten out the differences in languages.
17:42
The month of July is history. A fine month. A coral reef was seeded.
14:14
On the non-use of AI in my writing process [Charlie's Diary]
This isn't a blog entry I wanted to write, but it's a necessary one: a statement about the use of generative large language models (colloquially "AI") in my work.
I do not use LLMs in my work. I don't use them in my non-work life either, for that matter. I despise the grifters selling these toys as "tools" and trying to convince us to use them to generate plausible answer-shaped text strings in place of actual internet search for verifiable sources.
I've been selling fiction that I wrote myself since 1985 or thereabouts, and novels since 2002. If you want to verify that I have written novels without using an AI, simply pick up a physical copy of "Singularity Sky", "Iron Sunrise", "The Atrocity Archives", or anything else I published before 2015, the year OpenAI was founded.
Hint: you will find seven Hugo-shortlisted novels from that period, and three Hugo-winning novellas, also two Locus-award winning novels and a couple more novellas and stories. Clearly I don't need AI to write award-winning stories.
I do not want or need a large language model to write my fiction for me. I write fiction compulsively—before I was published I wrote for many years as a hobbyist—so why on earth would I pay someone else to take my fun away?
You will note em-dashes in the preceding paragraph. I gather some "AI detector" services (themselves a generative AI product) flag em-dashes as signs of "AI generated" text. Listen, fuckers, LLMs sprinkle em-dashes in their output because LLMs exist to stochastically emit strings of text that approximate the form of their inputs, and they've been trained by stealing all the text on the internet that isn't nailed down, including pirate websites that distribute cracked e-books. So it's wholly unsurprising that LLM output exhibits quirks that mimic real writers.
Did I mention the "stealing" thing? This isn't hyperbole: I'm one of the parties to the settlement in the class action lawsuit against Anthropic AI for pirating ebooks to train their LLMs. That's not my only grievance, either. You may have noticed this blog performing sluggishly or crapping out from time to time over the past few months. That's because my server is old and feeble and periodically gets swarmed by Chinese and other foreign botnets scraping data for training LLMs.
I'm usually willing to cut actual human beings, as opposed to for-profit corporations, some slack where it comes to cracking DRM, or even downloading warez: but these people are absolute scum. They're stealing copyrighted material to train an LLM that is intended to compete for revenue with the authors of the works they stole, and they're fine-tuning their LLMs to make them as addictive as possible in order to maximize future revenue once they pivot to token sales as their main source of income. In other words, they're no different from a burglar who robs you one day then comes round to sell you your stuff back the next morning. Back in the 18th century we used to hang people like that and Sam Altman makes me question the wisdom of having stopped.
I maintain that any serious author should shun LLMs like the plague. The most popular LLMs in the west—such as Claude, Gemini, CoPilot, and ChatGPT—the ones hoovering text indiscriminately off the internet for training—also gobble up any queries you send to them and use them as future training data. If I was crazy enough to feed the outline of a story I was working on as a prompt to ChatGPT or Claude in hope of getting the stochastic parrot to do my homework for me, then it would be only my own fault and nobody else's if the next model from the company in question was been trained on my book outline and could reproduce part or all of it for someone else.
Finally, contra public opinion, I see no reason to credit LLMs with sentience. They're word-association mechanisms with no embodiment and no way to associate the text vectors they manipulate with real-world phenomena. But we humans have evolved through selection pressure in an adversarial environment to associate environmental phenomena around us with intentional causes—if you see lion scat and the gazelle are no longer visiting the watering hole, then you should assume there are lions about. And this trait carries over to linguistic manipulation. If we hear or read text, we expect there to be a mind on the other side of it, as Joseph Weizenbaum (the inventor of the original ELIZA chatbot) realized at MIT in the late 1960s. Just because it does something people do, it does not follow that it is a person.
Now for some caveats.
My skepticism does not carry over to all aspects of the field. It would be foolish to deny the effectiveness of image recognizers based on generalized adversarial networks (GANs), the key neural network technology underlying LLMs. It'd be similarly stupid to deny that LLMs are very good at supporting large-scale statistical analysis of text, such as Linear-A. And I can see some circumstances where being able to train a local model on my work could be useful to me.
I'd quite like a tool (running entirely locally on my own hardware, with no cloud service and no copyright-thieving grifters making bank on it via subscription fees) that digests a manuscript and derives a scene-by-scene timeline, that I could then query interactively and use to plan my next round of edits. Being able to map out where and when each protagonist and minor character shows up, and see a frequency distribution heat map of names in the manuscript, would be useful.
But such a tool would be useful to me in the same way a spelling checker is useful—as a decision-support tool, not as a substitute for doing the hard work (and having a copy of the Oxford English Dictionary on the shelf). The value of such a tool is considerably less than the value of a well-trained brain that can do the entire job the hard way, if necessary. And it's less than zero if using it opens me to finger-pointing accusations of "but he's using AI!" by people who can't read to the end of one paragraph, much less fourteen of them (yes, this is para fourteen, I've been counting).
So my fiction is still, as of August 2026, 100% LLM-free, and if that changes I will update this declaration accordingly.
Finally, I'd like to leave you with a snippet from the opening of the far future space opera I'm editing right now. It's part of the fiction and unfortunately may have to be omitted because of the risk of confusing the people who can't read to the end of the paragraph, but it's the only valid use of LLMs I've found so far for my fiction because it's a solution to the calling a rabbit a smeerp problem in SF and fantasy:
Translator's Note
The events described in this account have been translated into your language from the original source material using a non-sapient large language model.
Certain terms have been approximated, where possible, by using culturally appropriate cognates. Names of individuals have been replaced by equivalents. Similarly, institutions, ranks, religions, proverbs, idioms, quotations, and other culturally-determined signifiers have been translated into terms that will be familiar to the reader.
Units of duration and distance have also been converted.
We apologize in advance for any hallucinations our LLM may have inadvertently introduced in the process of generating this rough translation.
13:42
Pluralistic: Why businesses lie about AI (01 Aug 2026) [Pluralistic: Daily links from Cory Doctorow]
->->->->->->->->->->->->->->->->->->->->->->->->->->->->->
Top Sources: None -->

Today's links
- Why businesses lie about AI: Humoring the boss all the way into bankruptcy.
- Hey look at this: Delights to delectate.
- Object permanence: Vinge x NYT; Syklarov x publishers; Human hair castles; Gingrich's bot army; Accessibility v Web DRM; David Byrne x WinXP; Furries don't fuck in fursuits; AI's pogo-stick grift.
- Upcoming appearances: Edinburgh, Sydney, Melbourne, Brighton, London, South Bend.
- Recent appearances: Where I've been.
- Latest books: You keep readin' em, I'll keep writin' 'em.
- Upcoming books: Like I said, I'll keep writin' 'em.
- Colophon: All the rest.

Why businesses lie about AI (permalink)
Neoclassical economics assumes rationality. The corollary of, "If you're so smart, why aren't you rich?" is "you're rich, so you must be very smart!" Thus it is that many people assume that if powerful, well-compensated CEOs insist that "AI is changing everything," well then, AI must be changing everything.
But the evidence for this "changing everything" thesis is thin on the ground. Despite a global mania that has reduced the real, pressing need for digital sovereignty to the imaginary need to create "sovereign AI," no one can really articulate the case for "sovereign AI." If Donald Trump ordered Big Tech to turn off all of your country's chatbots tomorrow, nothing would change. Every one of your country's ministries and corporations would chug on with nary a hitch. Households, too, though perhaps a few of the younger members of those families would have to do their own homework again.
(Contrast this with what would transpire if Trump directed his tech giants to switch off your country's Office 365 access, or to brick your Android and iOS phones, or to killswitch your John Deere tractors. Your country would effectively cease to exist. If "digital sovereignty" means anything, it means doing something about this urgent fact):
https://pluralistic.net/2026/06/18/their-trillions-our-billions/#eyes-on-the-prize
The world is full of people who insist that "AI is changing everything" but who – when pressed – have to admit that what they mean is that they're pretty sure that AI will change everything. Eventually. After we allow it to consume all the planet's energy, carbon, water and financial resources.
Maybe.
(They're pretty sure.)
One person who's had a lot of opportunity to observe the shear between the stated business/AI situation and the real business AI situation is Nikhil Suresh from Hermit Tech, a consulting firm of "radically ethical data wizards" (that is, tech consultants). Suresh reports on his experience talking with hundreds of executives (and, more importantly, their subordinates) about what (if anything) AI is doing for business in an essay entitled "AI Mania Is Eviscerating Global Decisionmaking":
https://hermit-tech.com/blog/ai-mania-is-eviscerating-global-decisionmaking
Suresh has a good track record of writing trenchant, frank criticism of AI. You may know him from his 2024 essay, "I Will Fucking Piledrive You If You Mention AI Again":
https://ludic.mataroa.blog/blog/i-will-fucking-piledrive-you-if-you-mention-ai-again/
Or possibly from his "Contra Ptacek's Terrible Article On AI," a stinging rebuttal to Thomas Ptacek's widely read "My AI Skeptic Friends Are All Nuts":
https://ludic.mataroa.blog/blog/contra-ptaceks-terrible-article-on-ai/
While those are important pieces of critical AI realpolitik, none of them have the heft or urgency of "AI Mania Is Eviscerating Global Decisionmaking," whose thesis can be summed up with this passage from halfway through this 6,000-word article:
[W]e’re facing a coordination problem around executives being honest around the AI gains they’ve witnessed – if they co-operate, they keep their jobs. If they defect, they will possibly be fired by their embarrassed peers (who have now been implicitly called liars, cowards, or incompetents) and then replaced with someone that will toe the line anyway. If they could all admit the truth at once there might be some hope, but there is no way to coordinate that event.
In other words, corporate leadership is starting from the premise that AI has (or will) radically change the business, and they're working backwards from that premise to find the evidence to support this article of faith.
In support of this thesis, Suresh cites "hundreds" of conversations with execs and employees who spoke to him on the condition that he would "file the serial numbers" off their stories. These, combined with his own experience consulting for large, multi-billion-dollar companies make it clear that "AI mania" is an absolutely justifiable label for the state of AI in corporate circles.
Here are a few highlights from this morning's read – moments where I had to look away from my screen and read out a passage to my wife so that we could share a "holy shit" moment.
A person worked for a division that "pivoted" to re-engineer its software to create interfaces that support AI agents. When it became apparent that only ten users had touched this expensive new technology, they "pivoted" again to support "agentic workflows." Why did they double down on AI agents after discovering such yawning market indifference for "agentic"? "Because every company has to do something agentic now."
Suresh describes this as a literal religious mania. In the 500+ employee businesses Suresh studied, the only people who were promoted – or even spared from being fired – were people who professed "religious declarations of faith" about "the transformative power of AI." Employees who voiced honest, informed objections to AI in the workplace were passed over for promotions or targeted for layoffs.
This has created a situation in which everyone – "boards, executives, employees, vendors, consultants" – has a strong incentive to lie about how much AI is delivering for their companies. Suresh says he's seen announcements from publicly traded companies about their AI triumphs that he knows for a fact never took place.
Suresh says he's never seen a successful enterprise AI project: "Every single one – we have seen 0% success in a year and a half." Not one of their clients would face a business challenge if OpenAI went out of business tomorrow. The problem most companies struggle with is that they're "terminally bad at running software projects effectively." Adding AI to the mix doesn't solve this problem – it just adds a whole new range of ways that software deployment can fail.
Chatbots don't help. The internally facing chatbot that's supposed to help employees figure out how to navigate the business sucks because it is only as good as its training date – the business's documentation of its own processes. Businesses suck at documenting their processes. Customer-facing chatbots also suck. They either can't solve your problem, or, when they seem to solve your problem, the "solution" goes nowhere.
Suresh recounts his sole positive customer service chatbot experience: a Mitsubishi chatbot with a natural sounding, responsive voice politely took all the details of an automotive failure and promised him a callback. That callback never came, but Suresh is certain that Mitsubishi has logged this as a chatbot success story, even though the experience convinced him not to buy a Mitsubishi car.
Suresh and his team at Hermit Tech now have a policy of not even asking about ongoing AI projects. They've learned that by the time an AI project has begun, no one will discuss it honestly until it reaches a crisis point.
Suresh says he frequently encounters people who reflexively utter the AI catechism: "AI is changing everything." But when he presses these people for details, they admit that their organization "does not currently use LLMs for anything, and indeed, that they cannot name a single thing that has changed other than they get some use out of ChatGPT."
This shear ("AI is changing everything"/"Well, OK, we're not using AI for anything") is so extreme that Suresh once met an exec who confessed to crafting an AI-centered AI strategy for a $2b/year business, even though that exec "had never even used ChatGPT or any AI tool in their life."
Some people have privately admitted to Suresh that they've embraced AI in order to earn a career-boosting corporate reputation for "thought leadership." But many other people (especially nontechnical people) sincerely believe that AI is about to "change everything." As Suresh says, if you're in business with a liar, you might be able to reason with them in private – but you can't reason with a true believer.
The true believers are in charge. Suresh points out that it would be very weird for the CEO of an engineering firm or a hospital to mandate "specific procedures or building techniques without explicit agreement from the professionals on staff." But when it comes to AI, business leaders will confidently demand that the skilled professionals who perform the business's core functions use AI, even if those professionals don't think it will help.
As an aside: I remember the dotcom era, when the business press was full of articles about the conflict between CEOs and a new workforce that demanded the right to use the web on the job. Today, the business press is full of articles about the conflict between the workforce and CEOs who demand that they use AI.
Suresh describes workers who feel they have to "AI wash" their work: "They just do the work, the same way they have for decades, and say Claude did it." To add verisimilitude to this sham, they write circular processes in which one chatbot prompts another, and then the process repeats itself in reverse, for the sole purpose of consuming AI tokens to score a high rank on corporate "token leaderboards."
How to account for this wildly, expensively irrational corporate leadership? Suresh places the blame in the hypnotizing, mesmerizing power of the AI demo. For example: Hermit Tech is often engaged to set up a database product called Snowflake for its customers. Snowflake has a useless, expensive AI bolt-on called Cortex, that Snowflake itself describes as being 92% accurate under ideal circumstances (that is, at least 8% of the time, it will mislead you, perhaps very badly).
Suresh describes sales meetings with execs who were lukewarm on the idea of retooling with Snowflake, but who were very interested in Cortex. Against their better judgment, Suresh and his team provided them with a Cortex demo, carefully explaining that this AI tool could not satisfy their requirements. Without fail, this resulted in the previously lukewarm customers insisting that they be allowed to purchase Cortex immediately. Sales prospects who'd been unmoved by a pitch for new technology that would result in millions in savings were hypnotized by demos of a product that was described as unsuitable and unreliable.
To their credit, Hermit Tech refused to sell these customers Cortex, and stopped doing Cortex demos altogether. Suresh describes the experience of "the total 180°, that shift from ice-cold to red-hot buying frenzy" as "deeply unsettling." What's more, the Cortex demos that Suresh and co performed were, by his account, pretty uninspiring. The thing that these demos had going for them is that they showed AI actually doing something marginally useful, to execs who'd already spent millions on AI without having anything to show for their money. The spectacle of AI that does something galvanizes corporate leaders who feel like they're the only bosses who can't find a revolutionary use for AI in their businesses.
This is the situation up and down the corporate org-chart. Suresh has a reader whose title is "Head of AI" at a billion-dollar firm who tells him "their job is totally fraudulent but it was the only promotion pathway remaining at the organisation." This exec is hardly alone. They're part of a cohort of executives at companies that have publicly announced "100x" productivity gains, but who confessed to Suresh that nothing of the sort has happened.
Why did these companies make these claims? Because their customers were making the claims. How could you hope to sell to a company that had 100x'ed its productivity with AI unless you, too had 100x'ed your productivity? If, as a vendor, you walked into a boardroom and said that this wasn't a plausible claim, you'd be calling your sales prospect a liar, with real consequences: "getting enterprise contracts cancelled because you wanted to opine on something that doesn’t really matter to your organisation’s mission is a great way to get fired."
With the state of the industry dominated by froth, lies and mutual destruction pacts, it's no wonder that companies are deploying "totally gameable metrics such as 'money spent on AI'" as a means of evaluating employees and divisions.
Between true believers and people who must find ways to plausibly tout their AI usage, there is now a gigantic market for "AI solutions." At best these are just traditional tech consulting contracts, like migrating a database from Oracle to Snowflake, with some kind of ornamental AI usage around the edges so that the person who commissions the work can claim to be "procuring AI-enabled services" for the business.
This isn't a harmless frippery: contracts are delayed and work is put off until the work can be made "sufficiently AI" to attain the minimum degree of buzzword compliance. Worse: every fake AI project that produces real results (because it's not really AI) adds credibility to the AI true believers, who view these projects as proof that AI can do anything, and therefore demand to know why everything isn't being done by AI.
Suresh ends his essay with a long section on how to "navigate AI mania" – advice for how to smile and nod politely when you're confronted with AI bullshit, while steering clear of the worst consequences and avoiding needless fights. This looks like very sound advice for anyone in a corporate environment, but thankfully, that isn't me.
Rather than summarize that advice, I want to reflect a little on two questions that Suresh's essay raises but doesn't answer. The first is why? Why are people in power such easy converts to this religious mania?
I have my own theory. The most important discomfort that powerful people experience is having ego-shattering conflicts with subordinates who know how to do things they do not know how to do. The fact that you're "in charge" is hard to reconcile with the fact that the people you're nominally in charge of tell you that all your ideas are impossible, illegal, immoral, or lethal:
https://pluralistic.net/2026/01/05/fisher-price-steering-wheel/#billionaire-solipsism
Take that Cortex demo. Sure, Cortex is an expensive, unreliable way to address a Snowflake database. But (unlike Snowflake) Cortex is controlled via conversational, plain-language commands. With Cortex, a boss doesn't need to ask an underling to retrieve information from the company Snowflake system, an interaction that might come with unsolicited feedback about the technical or commercial incoherence of the boss's request. Cortex is the underling, except that unlike a human underling, Cortex never back-sasses you about your foolish questions. The fact that it grossly misleads you 8% of the time is a small price to pay for a life untroubled by uppity pismires who insist that your ideas be connected to base reality as they understand it.
The other question Suresh implicitly raises is, "How can you reconcile the failure of AI in the enterprise with the individual claims of skilled technologists who insist that AI is helping them do great work?" The answer is that these AI users are "centaurs" – experienced workers who are assisted by automation on terms that they set for themselves:
https://pluralistic.net/2025/09/11/vulgar-thatcherism/#there-is-an-alternative
Thanks to their skill and experience, these workers possess discernment, the ability to tell good code from bad, and (more importantly) good uses of code-generation tools from bad. They demonstrate the adage that worker-driven automation improves quality, while capital-driven automation improves throughput:
https://pluralistic.net/2026/07/28/hitl-ers/#ai-ai-oh
An automation technique that requires close supervision by skilled and experienced workers isn't going to be a raw productivity powerhouse. You don't "100x" your code this way, at least, not in the sense of firing 99 of your coders and having the remaining programmer pick up all their work. Rather, an automation tool that requires the continuous and conscientious exercise of discernment will let individual practitioners improve their work in extremely satisfying and useful ways. It's a way to spend more on operations in order to produce better outputs. It's not a way to cut your workforce, realize a gigantic savings, and still produce comparable goods and services at a far lower cost.
That is why some individual coders report such delight with their AI tools. They engage with those tools on their own terms, to improve their work in the ways that they, in their expert judgment, consider beneficial. No one ranks them on a "token-maximization" scoreboard. No one tells them they can't do a project if it isn't "sufficiently AI." When they set out to do a project, no one makes them prove that it couldn't be "done by AI."
As ever, the most important fact about a given technology isn't "what it does," but "who it does it for" and "who it does it to."
All the pathologies Suresh observes and documents so well in this piece are hypertrophied versions of the buzzword-compliance dysfunctions from previous bubbles, but at a scale never before seen. Quantity has a quality all its own. These businesses aren't just wasting billions – they're replacing skilled workers with defective chatbots. As I've written before, AI is the asbestos we're shoveling into the walls of our technological society. Our descendants will spend generations digging it out again, and the longer the bubble goes on without popping, the longer it will take to repair the damage.
Hey look at this (permalink)

- The rent was already high. Then came the $200 work-from-home fee https://finance.yahoo.com/real-estate/articles/rent-already-high-then-came-174555709.html
-
Families in London temporary housing told they cannot use in-built air conditioning https://www.theguardian.com/society/2026/jul/27/homeless-families-london-temporary-housing-air-conditioning
-
The New Defcon Badges Pack a Unique Open Source Chip That Doubles as a Security Key https://www.wired.com/story/defcon-34-badge-baochip-andrew-bunnie-huang/
-
US government map of Africa mislabels every country at global conference https://www.theguardian.com/us-news/2026/jul/30/government-map-mislabels-african-countries?CMP=Share_AndroidApp_Other
-
EFF Guide to Recording Law Enforcement https://www.eff.org/deeplinks/2026/07/eff-guide-recording-law-enforcement

Object permanence (permalink)
#25yrsago Vernor Vinge in the NYT https://www.nytimes.com/2001/08/02/technology/a-scientist-s-art-computer-fiction.html
#25yrsago Why publishers should thank Syklarov https://web.archive.org/web/20011023092940/http://www.zdnet.com/zdnn/stories/comment/0,5859,2800985,00.html
#25yrsago David Byrne track to be bundled with WinXP https://web.archive.org/web/20010804040357/http://www.ananova.com/news/story/sm_365899.html?menu=news.technology
#20yrsago Five things about blogs that no one ever needs to say again https://web.archive.org/web/20060813090449/http://www.stevenberlinjohnson.com/2006/08/five_things_all.html
#15yrsago Castles made from human hair https://inhabitat.com/artist-uses-human-hair-to-construct-a-castle-of-3000-bricks/
#15yrsago Wisconsin Democratic voters targeted with Koch-funded absentee ballot notices advising them to vote 2 days after the recall election https://www.politico.com/blogs/david-catanese/2011/08/afp-wisconsin-ballots-have-late-return-date-037977?showall
#15yrsago Gingrich’s million Twitter followers: “80% dummy accounts, 10% paid followers” https://web.archive.org/web/20110812100159/https://gawker.com/5826645/most-of-newt-gingrichs-twitter-followers-are-fake
#15yrsago Missouri State business-school professor leads successful campaign to ban Slaughterhouse-Five from local schools https://www.theguardian.com/books/2011/jul/29/slaughterhouse-five-banned-us-school
#10yrsago Australian media accessibility group raises red flag about DRM in web standards https://hotelsantalya.net/accessiq/news/news/2016-p/08-p/concerns-raised-for-assistive-technology-development-as-w3c-debates-encrypted/
#10yrsago Reminder: the GOP has been attacking veterans and their families for years https://web.archive.org/web/20160803203106/https://crookedtimber.org/2016/08/02/trumps-indecent-proposal/
#10yrsago Isis joins Donald Trump in denouncing Khizr Khan https://web.archive.org/web/20160802161454/https://theintercept.com/2016/08/02/donald-trump-and-islamic-state-agree-no-room-for-people-like-khizr-khan/
#10yrsago Furries don’t have sex in fursuits https://www.ohjoysextoy.com/fursuits-grey-white/
#5yrsago Machine learning sucks at covid https://pluralistic.net/2021/08/02/autoquack/#gigo
#1yrago AI's pogo-stick grift https://pluralistic.net/2025/08/02/inventing-the-pedestrian/#three-apis-in-a-trenchcoat
Upcoming appearances (permalink)

- Virtual: EFFecting Change: Who the Machine Serves, Aug 12
https://www.eff.org/event/effecting-change-who-machine-serves -
Edinburgh International Book Festival with Jimmy Wales, Aug 17
https://www.edbookfest.co.uk/events/the-front-list-cory-doctorow-and-jimmy-wales -
Sydney: The Festival of Dangerous Ideas, Aug 23-24
https://festivalofdangerousideas.com/program/ -
Melbourne: Enshittification at the Wheeler Centre, Aug 25
https://www.wheelercentre.com/events-tickets/season-2026/cory-doctorow-enshittification -
Brighton: The Reverse Centaur's Guide to Life After AI with Carole Cadwalladr (Brighton Dome), Sep 8
https://brightondome.org/whats-on/LSC-cory-doctorow-the-reverse-centaurs-guide-to-life-after-ai/ -
London: The Reverse Centaur's Guide to Life After AI with Riley Quinn (Foyle's Picadilly), Sep 9
https://www.foyles.co.uk/events/enshittification-cory-doctorow-riley-quinn -
South Bend: An Evening With Cory Doctorow (Notre Dame), Oct 6
https://franco.nd.edu/events/2026/10/06/an-evening-with-cory-doctorow/ -
Vancouver: BC Policy Solutions Gala, Nov 12
https://bcpolicy.ca/gala/

Recent appearances (permalink)
- F@#$ the AI Overlords (On The Media)
https://www.wnycstudios.org/podcasts/otm/articles/f-the-ai-overlords -
Why AI Won't Replace Workers, But Will Crash The Economy (Smart Cookies)
https://www.youtube.com/watch?v=rRRmUuxJolY -
AI and the Enshittification Era (The Weekly Show with Jon Stewart)
https://www.youtube.com/watch?v=-dAIJRjb-Bw -
AI is not inevitable (Betakit)
https://www.youtube.com/watch?v=DbiTVkq1WHo -
A Conversation with Lina Khan (Law and Economy Student Network)
https://www.youtube.com/live/7Ak5LZllqwE

Latest books (permalink)
- "The Reverse-Centaur's Guide to AI," a short book about being a
better AI critic, Farrar, Straus and Giroux, June 2026
https://us.macmillan.com/books/9780374621568/thereversecentaursguidetolifeafterai/ -
"Canny Valley": A limited edition collection of the collages I create for Pluralistic, self-published, September 2025 https://pluralistic.net/2025/09/04/illustrious/#chairman-bruce
-
"Enshittification: Why Everything Suddenly Got Worse and What to Do About It," Farrar, Straus, Giroux, October 7 2025
https://us.macmillan.com/books/9780374619329/enshittification/ -
"Picks and Shovels": a sequel to "Red Team Blues," about the heroic era of the PC, Tor Books (US), Head of Zeus (UK), February 2025 (https://us.macmillan.com/books/9781250865908/picksandshovels).
-
"The Bezzle": a sequel to "Red Team Blues," about prison-tech and other grifts, Tor Books (US), Head of Zeus (UK), February 2024 (thebezzle.org).
-
"The Lost Cause:" a solarpunk novel of hope in the climate emergency, Tor Books (US), Head of Zeus (UK), November 2023 (http://lost-cause.org).
-
"The Internet Con": A nonfiction book about interoperability and Big Tech (Verso) September 2023 (http://seizethemeansofcomputation.org). Signed copies at Book Soup (https://www.booksoup.com/book/9781804291245).
-
"Red Team Blues": "A grabby, compulsive thriller that will leave you knowing more about how the world works than you did before." Tor Books http://redteamblues.com.
-
"Chokepoint Capitalism: How to Beat Big Tech, Tame Big Content, and Get Artists Paid, with Rebecca Giblin", on how to unrig the markets for creative labor, Beacon Press/Scribe 2022 https://chokepointcapitalism.com

Upcoming books (permalink)
- "The Post-American Internet," a geopolitical sequel of sorts to Enshittification, Farrar, Straus and Giroux, 2027
-
"Unauthorized Bread": a middle-grades graphic novel adapted from my novella about refugees, toasters and DRM, FirstSecond, April 20, 2027
-
"Enshittification, Why Everything Suddenly Got Worse and What to Do About It" (the graphic novel), Firstsecond, 2027
-
"The Memex Method," Farrar, Straus, Giroux, 2027

Colophon (permalink)
Today's top sources:
Currently writing: "The Post-American Internet," a sequel to "Enshittification," about the better world the rest of us get to have now that Trump has torched America. Fourth draft completed. Submitted to editor.
- A Little Brother short story about DIY insulin PLANNING

This work – excluding any serialized fiction – is licensed under a Creative Commons Attribution 4.0 license. That means you can use it any way you like, including commercially, provided that you attribute it to me, Cory Doctorow, and include a link to pluralistic.net.
https://creativecommons.org/licenses/by/4.0/
Quotations and images are not included in this license; they are included either under a limitation or exception to copyright, or on the basis of a separate license. Please exercise caution.
How to get Pluralistic:
Blog (no ads, tracking, or data-collection):
Newsletter (no ads, tracking, or data-collection):
https://pluralistic.net/plura-list
Mastodon (no ads, tracking, or data-collection):
Bluesky (no ads, possible tracking and data-collection):
https://bsky.app/profile/doctorow.pluralistic.net
Medium (no ads, paywalled):
Tumblr (mass-scale, unrestricted, third-party surveillance and advertising):
https://mostlysignssomeportents.tumblr.com/tagged/pluralistic
"When life gives you SARS, you make sarsaparilla" -Joey "Accordion Guy" DeVilla
READ CAREFULLY: By reading this, you agree, on behalf of your employer, to release me from all obligations and waivers arising from any and all NON-NEGOTIATED agreements, licenses, terms-of-service, shrinkwrap, clickwrap, browsewrap, confidentiality, non-disclosure, non-compete and acceptable use policies ("BOGUS AGREEMENTS") that I have entered into with your employer, its partners, licensors, agents and assigns, in perpetuity, without prejudice to my ongoing rights and privileges. You further represent that you have the authority to release me from any BOGUS AGREEMENTS on behalf of your employer.
ISSN: 3066-764X
10:49
What if they meant it?
What if your return felt special to the people behind the counter?
What if they knew, without looking it up, or being told–what if they knew that you were here, again, a vote of trust and confidence.
Returning home is one of the oldest human desires. It’s a feeling that doesn’t easily lend itself to automation, procedures, or scale.
Being welcomed home offers us dignity, safety and belonging. Hard to fake, worth working hard to create.
07:07
Making an agile version of a Windows Runtime delegate in C++/WinRT, part 10 [The Old New Thing]
In
part 5 of this unnecessarily long series on agile delegates,
commenter LB asked, “Is the
ContextCallback in the deleter guaranteed to
always succeed? According to the docs it can fail. I wonder if
there’s a way to move the fallible part to an earlier point
so the deleter can be infallible.”
Let’s look at the first part: What if
IContextCallback::ContextCallback
fails?
If it fails, it means that COM couldn’t switch to the destination context.
If you can’t switch to the destination context, then you can’t release the pointer. It’s not clear what recovery is possible anyway. Do you just keep retrying until it finally works?
If the destination context is an ASTA, then it’s possible that the reason is that the context is already busy, and ASTA doesn’t allow re-entrancy. We’d have to wait a little bit and try again later, when the destination context might be ready. We can’t just block on the retry because the destination context might be calling into the thread we are on right now, so just spinning in a retry loop won’t help because it’s waiting for us! We’re have to return, allow whatever we’re doing to finish, which in turn allows the ASTA to resume, and then it becomes worthwhile to try to call into the ASTA again.
This would be the issue for conventional COM calls into the
ASTA, but we are using IContextCallback, and that lets
us control whether or not to honor ASTA reentrancy roadblocks.
If riid is set to IID_ICallbackWithNoReentrancyToApplicationSTA, the function does not reenter an ASTA arbitrarily.
We are not passing that special value, so our call to
ContextCallback is allowed to reenter an ASTA.
That removes one possible source of failure.
What other reasons could there be for not being able to switch to the destination apartment?
The most likely reason is that the destination apartment no longer exists, in which case there is no recovery. Depending on how the object was managed by its creating thread, it might have been forcibly destroyed at thread termination¹, or it may simply have been leaked. We don’t know. At any rate, there’s no way to release it now.
The other case is that the destination apartment is not reachable due to a low-memory condition. We discussed earlier how the most common reason is a destination thread that has stopped responding to messages. I guess you could wait and try again later, but in practice if a thread has stopped responding for so long that its inbound message queue is full, the odds that it will magically start responding soon are pretty low.
All of the failures are effectively unrecoverable. But some of
them are non-fatal, such as the
CoDisconnectObject discussed in the
footnote. Unfortunately, we can’t tell what case we are in.
The ContextCallback returns
RPC_E_DISCONNECTED to say that the destination
apartment no longer exists, but we don’t know how that
apartment cleaned up its orphaned objects.
The C++/CX implementation of lazy-created agile delegates ignores errors that occur trying to release the original pointer. So we’ll do the same.
But wait, we can do better. Next time.
¹ This is often combined with a
CoDisconnectObject to tell proxies to fail
all calls with RPC_E_DISCONNECTED, so that there are
no external references to destroyed objects.
The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 10 appeared first on The Old New Thing.
06:21
Russ Allbery: Review: How to Steal a Galaxy [Planet Debian]
Review: How to Steal a Galaxy, by Beth Revis
| Series: | Chaotic Orbits #2 |
| Publisher: | DAW Books |
| Copyright: | December 2024 |
| ISBN: | 0-7564-1949-2 |
| Format: | Kindle |
| Pages: | 143 |
How to Steal a Galaxy is a far-future science fiction caper short novel (maybe a novella?) and the sequel to Full Speed to a Crash Landing. You don't have to remember the details of the previous book to enjoy this one. There's an excellent inline summary at the start of this installment.
After an annoying negotiation with people who keep trying to preach at her about causes, Ada Lamarr has a new contract. She is going undercover, after a fashion, at a charity gala and auction on Rigel-Earth. While she's there, she's going to steal something. What, precisely, she keeps a mystery from both the other characters and from the reader until the end of the story.
Government agent Rian White is working security at this charity gala. Due to its link with the plot of Full Speed to a Crash Landing, he was fairly certain Ada would be there, as indeed she is. What she is planning, however, is maddeningly unclear. Also maddening is how good Ada looks in a dress.
As with the previous book, How to Steal a Galaxy is told by Ada in the first person using the same teasing tone and constant misdirection that she uses when verbally fencing with Rian and the other characters. I found this novella even more entertaining and satisfying than the previous one. The charity gala is supposedly intended to benefit the poor people of Earth, and is run with exactly the sort of condescension and disguised capitalist looting typical of such exercises in elite charity. Ada's narration is scathing in a deeply relatable way.
Also, there is a trillionaire tech-bro fake philanthropist who is smug and condescending and accustomed to getting exactly what he wants.
"I don't think anyone should have enough personal wealth to decimate a large country's income just because he's going through a midlife crisis."
Ada's interactions with Strom Fetor are an absolute delight. He is so sure of himself that he is incapable of registering her as a threat, and she effortlessly deceives him by hiding in plain sight.
"You really shouldn't be talking about this," Rian starts.
Fetor waves aside his concerns. "We're all friends here."
"Not me," I say. "I hate you. Remember?"
Fetor laughs in a tone I'm sure he thinks is charming.
Fetor's complete inability to realize that a beautiful woman might both sincerely not like him and not be flirting with him is perfect. I was cackling through half of this book.
Like any good heist story, there are twists and turns, surprises, double agents, unexpected complications, and a delightful amount of verbal fencing. I adore the narrative tone Revis uses for these stories. Ada has just the right mix of idealism, cynicism, professionalism, and irreverence to carry off the feeling that she's a step ahead of everyone else. Underneath the bones of a delightful plot is a character who cares deeply but is very aware of her limitations, and therefore has taught herself to laugh at and be ruthless with her own emotions. I am finding it an incredibly compelling type of competence porn.
I enjoyed the first book of this series, but this one was so much better. These stories are exactly the right length to keep the reader engrossed throughout and satisfied but wanting more at the end. How to Steal a Galaxy ends on a cliffhanger of sorts, to be resolved in the next and final book. I can hardly wait to start it.
Highly recommended.
Followed by Last Chance to Save the World.
Rating: 9 out of 10
06:14
New Cover Song: “Ode to Somewhere” [Whatever]

This cover song has an interesting story to it, which is that it’s a song from a video game called “Deathloop.” In the video game, the singer is supposed to have been a huge star but has lately gone kind of venal around the edges, and also there’s a whole time loop thing going on which necessitates the player character needing to kill the singer (and several other people) for, you know, reasons. It all makes sense in the context of the game, and the game itself is a hell of a lot of fun. I absolutely recommend it.
The in-game singer may be a jerk, but this song (written and performed by Erich Tabla with Jeff Cummings on vocals) is really good, and in fact was one of my favorite songs of its year, with a real 60s torch-song feel to it. My version is a little more electronic-y and revved up on the drums, because apparently I do that. Nevertheless I think it’s not bad, and I hope you like it.
Also, since it’s possible you may not have ever heard this song unless you played the game, if you’re curious as to how the original sounds, here it is:
— JS
00:07
Develop cross-platform CLI and GUI tools with Tcl/Tk [OSnews]
Tcl, or the “Tool Command Language“, created and released by John Ousterhout in 1990, deserves a place among the greatest products of the human mind. Especially when combined with its better known graphical user interface Toolkit — Tk. In 1997 Ousterhout was awarded the ACM Software System Award for Tcl/Tk, an award given to institutions or individuals recognized for developing software systems with a lasting influence, reflected in contributions to concepts, in commercial acceptance, or both.
↫ Armen Barsegyan
Everything you could ever possibly want to know about Tcl/Tk. There’s nothing to add here; if this is up your alley – and you know if it is – just go ahead and read it, and stop wasting time here.
Friday, 31 July
22:42
Friday Squid Blogging: Squid Helps Discover New Marine Species [Schneier on Security]
The Squid is a new scientific machine:
One of the technological breakthroughs was the onboard use of a spinning wheel confocal microscope, nicknamed the Squid, which uses lasers to scan microscopic details of how organisms are put together. “That opens up a whole new world of exploring. We could see cells interacting with each other, exchanging material and building skeletons. And we could do that live on the ship, when usually it takes a couple of weeks of staining and mounting to see anything,” Osborn said.
The expedition discovered thirty-one new marine species in two weeks. The article doesn’t say if any of them were new species of squid.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
22:14
The hardest thing for people to get about open systems is that if you move forward, not only do you benefit, but your competitors benefit equally. When one of them takes but doesn't give back, that's even worse. But you do it anyway because otherwise eventually, without interop, no one can move.
21:00
Amending AB 1709 Doesn’t Fix It: California’s Social Media Ban Still Threatens Free Speech and Privacy [Deeplinks]
California lawmakers have amended A.B. 1709, but the core problem remains: the bill is still a ban on social media access for youth under 16, and it still threatens the privacy and First Amendment rights of all Californians.
Proponents of the bill may argue that the recent amendments represent a compromise, but a close look at the text shows no major changes. As the bill moves forward in the Senate, we must continue to urge lawmakers to vote NO.
Take Action: Tell Your Senator to OPPOSE A.B. 1709
A "Compromise" That Still Denies Access
Under the newly amended Section 22683, platforms are prohibited from offering "addictive features" to users under 16. A platform can allow a minor to keep an account only if it strips away these features, which include what the bill calls "addictive feeds," auto-play, and anything else the Attorney General designates in future rulemaking.
However, the bill defines "addictive feeds" so broadly that it covers virtually every functional recommendation algorithm. The bill applies this label to any presentation of user-generated content recommended "in whole or in part, on information provided by the user." That includes basic inputs like who a user follows, what posts they like, or their self-expressed interests. By calling these basic tools and features “addictive," the bill also makes broad conclusions about the unsettled science behind social media use, youth, and addiction.
Because almost every major social media service uses automated feeds to deliver content, the end result of AB 1709 remains the same: young people under 16 will be denied access to major social media services as they currently exist.
Even if a platform attempts to comply by stripping away recommendation systems for minors, this still violates the First Amendment. Recommendation systems are the primary tools that users rely on to find speech and disseminate their own. Forcing young people onto a stripped-down, dysfunctional version of social media burdens their constitutional right to access information and participate in public discourse.
AB 1709 Still Forces Invasive Age Verification
The amendments do not eliminate the privacy threats posed by age gating. Although the bill references the age-signaling framework in AB 1043, Section 22684 explicitly states that a covered platform "shall verify the age of a user” and makes platforms liable every time a person under 16 makes it through an age check.
Because AB 1043 does not actually specify how verification should occur without requiring additional proof, AB 1709 will, in practice, force platforms to implement the strictest forms of age verification. To comply, platforms will likely require users to upload government-issued IDs or submit to biometric scanning. Forcing users to turn over their personal information will create massive honeypots of sensitive personal data, destroying online anonymity and exposing users of all ages to security breaches. And relying on biometric systems to verify users’ ages is problematic because the systems have historically had high error rates estimating ages across race and gender lines.
Take Action: Tell Your Senator to OPPOSE A.B. 1709
Lawmakers Must Reject AB 1709
The amendments to AB 1709 also introduce legal confusion, creating provisions that conflict with already enacted legislation like SB 976. Rather than providing clarity or protecting young people, AB 1709 creates a tangled regulatory scheme that sacrifices constitutional rights for political grandstanding.
Denying minors access to digital forums—or stripping those forums of the basic tools needed to navigate them—is censorship. California should not set a national precedent of cutting young people off from digital lifelines, communities, and speech.
We need to keep the pressure on as AB 1709 moves through the Senate. Contact your state senator today and tell them that minor tweaks to a bad bill do not make it good policy.
The SCREEN Act Threatens Privacy Far Beyond Adult Websites [Deeplinks]
The Senate Commerce Committee is set to consider S. 737, the SCREEN Act, a sweeping age-verification bill that would require online services to verify users’ ages before they can access any sexually explicit content. If this bill passes, it will force millions of adult internet users to give up their anonymity, privacy, and security before they access lawful speech.
Unlike many state-age verification laws—which have been harmful in their own right—the SCREEN Act has no requirement that a significant portion of the website consist of sexually explicit content that is harmful to minors. The bill requires nearly any service hosting even a single piece of sexually explicit content to verify the ages of its users. The result is that the bill would apply not only to adult content sites like PornHub or OnlyFans, but also streaming services like Netflix, and social media platforms like Reddit, Discord, or Bluesky, if they host any adult content.
The SCREEN Act does not merely require users to attest they are adults. It specifically states that “requiring a user to confirm that the user is not a minor shall not be sufficient.” In practice, that means platforms would have to verify users’ ages using methods tied to their real identities. Providing proof of age online is dramatically different, and far more invasive, than showing your ID at the door to a bartender or bouncer. In the physical world, the bouncer at the door looks at your ID card, confirms you’re old enough, and gives it back to you. Under the SCREEN Act, the “bouncer” will be a digital age-verification service that captures your personal information and saves it to a database for an unspecified amount of time.
The consequences of the bill won’t be limited to minors. If websites and apps are expected to reliably identify teenagers, adults will be asked to prove they are adults.
Even worse, the SCREEN Act is a privacy and data security nightmare. One provision of the bill requires services to take reasonable steps to protect the data collected and to not maintain for longer than is necessary. But these are terribly weak protections that impose no meaningful collection, use, or retention limits on services collecting people’s private information.
In other words, the third parties tasked with verifying a user’s age on a platform could sweep up a lot of personal info they don’t actually need and then could use that information for any number of purposes, so long as they deem their actions reasonable. Companies would then be allowed to keep the information users have been compelled to turn over for as long as possible, raising security and privacy issues along the way.
The SCREEN Act Attacks Your Right To Use VPNs
The SCREEN Act also targets virtual private network (VPN) users and providers. The bill requires covered websites to verify users' ages based on their IP addresses unless the service can determine that the user is outside the United States, and specifically requires age verification on traffic coming from known VPN addresses. In practice, this discourages the use of VPNs and proxy servers, which millions of people rely on for legitimate purposes such as protecting personal privacy, securing public Wi-Fi connections, safeguarding journalists and activists, and preventing data tracking.
VPNs mask your real location by routing your internet traffic through a server somewhere else. When you visit a website through a VPN, that website only sees the VPN server's IP address, not your actual location. It's like sending a letter through a P.O. box so the recipient doesn't know where you really live. VPNs are a privacy and security tool used by millions of internet users every day, and their use should not be treated as suspect. It is particularly galling that the SCREEN Act forces users who intentionally take steps to protect their privacy to identify themselves.
The SCREEN Act creates onerous age-verification rules that will block adults from accessing lawful speech, curtail their ability to be anonymous, and jeopardize the data security and privacy of all internet users.
20:42
Jimothy Chalamet [Penny Arcade]
Raccoons in my neighborhood, save one, are not spherical. They are big though, off that Seattle trash. They're fat as fuck off Brie rinds and jamón ibérico trimmings. Some of these bad boys can deliver near-cryptid thrills. When I was driving home one night, I saw one that didn't even read as a raccoon visually - my mind told me that it was most likely a toddler that had escaped from some kind of toddler… prison. That's what it gave me! Not helpful.
20:14
The CHATBOT Act Forces One Parenting Model On Every Family [Deeplinks]
Artificial intelligence is rapidly changing education, and the way people search for information. Parents, teenagers, teachers, and schools are struggling with tough questions about when AI should, and should not, be used. It makes sense for Congress to hold hearings and examine how AI should be used by minors. But the recently introduced CHATBOT Act answers those questions with a one-size-fits-all mandate governing how teenagers access AI through federally prescribed parental monitoring systems.
The Bill Requires AI Companies To Build Family Monitoring Systems
Parents are approaching AI in different ways. Some closely supervise how their children use chatbots, while others might set more general rules about technology. Many families are still figuring out what role AI should play in schoolwork and everyday life.
The CHATBOT Act would take that decision away from families and AI providers. Instead of letting families and AI providers decide what parental controls should look like, Congress would require every covered AI chatbot to build the same federally prescribed “family account” system.
As part of the required parental-consent process for teens, AI companies must offer parents a "family account" that provides access to a "full record of the conversations and activity" of teen users and tools to "monitor, analyze, and understand, at scale" those conversations. They must also send alerts if a teen attempts to bypass or disable parental controls.
This isn’t simply an optional parental-control feature. The bill requires every covered AI provider to build this monitoring infrastructure, and present it as part of the parental consent process. Congress is prescribing a single, highly invasive model of how families should supervise teenagers’ use of AI.
The CHATBOT Act Creates New Privacy Risks For Families
Parents and families have different ideas about how much independence teenagers should have. Understandably, they also have very different expectations for 8-year olds, 13-year-olds, and 17-year-olds. The CHATBOT Act effectively requires AI providers to build the same monitoring architecture for users of very different ages.
And this mandated data collection will create new privacy and security risks. Once Congress requires AI companies to create a permanent, centralized record of teen AI conversations for parental review, that will be a valuable vault of extremely personal information. That raises serious questions about what would happen in cases where someone else gains access to it through account compromise, family disputes, or other security failures.
The vast archives of conversations created by the government-mandated family accounts won't be interesting only to parents. They will become valuable targets for hackers, identity thieves, civil litigants, and anyone else seeking access to the deeply personal information of others. The CHATBOT Act requires the records to exist, but addresses none of those risks.
Families are still figuring out what role AI should play in schoolwork and everyday life. Congress shouldn’t freeze one answer into federal law by requiring every AI company to build the same prescribed monitoring system.
The CHATBOT Act Applies A Children’s Law To Teenagers
The CHATBOT Act takes the basic structure of COPPA, a nearly 30-year-old law that applies to children aged 12 and under, and applies the same “verifiable parental consent” to older teenagers.
That’s a dramatic expansion of the law. Congress enacted COPPA to prevent kids from handing over detailed personal information to online services without making sure parents approved. For nearly three decades, Congress has required parental consent before websites collect personal information from any user under 13. COPPA is not simple to comply with, which is why so many internet companies, large and small, simply bar kids under 13 from having accounts. That includes major social media sites and AI. Facebook, Instagram, TikTok, X, YouTube, Snapchat, Discord, Spotify, and blogging platforms like WordPress all keep out users under 13. Children under 13 are also not allowed to use Microsoft Co-Pilot, Google Gemini, or ChatGPT. Anthropic does not allow users under 18 to use its AI model, Claude. In cases where younger kids maintain social media accounts despite the rules, studies show the vast majority of them are creating those accounts with parental consent.
In short, COPPA’s protections against collecting personal information from minors without parental consent already apply to the AI services CHATBOT Act seeks to regulate. Worse, the CHATBOT Act takes COPPA’s privacy protections and inverts them—it will result in AI services likely collecting more information about young users.
But the CHATBOT Act extends that model to high school students using AI assistants that are rapidly becoming tools for learning, research, writing, coding, and creative work. It then mandates specific, invasive surveillance tools that go well beyond anything COPPA requires.
The bill requires providers to offer these “family accounts,” with these specific features, as a default for teenagers. By doing so, CHATBOT effectively treats a high school senior the same way it treats an elementary school student.
Supporters may argue that parents of teens don’t have to create a family account. But every family with a teenager will still have to go through the bill’s parental-consent process before a teenager can use a covered AI system. Providers will need practical ways to verify that an adult is, in fact, the teenager’s parent. And parents of kids under 13 have no option to consent to their kids’ use of an AI system—the bill’s only option is to create a family account.
Congress should not extend the COPPA parental-permission model to millions of older teenagers, and it would be harmful to do so. The government does not require COPPA-style parental permission before a 17-year-old checks out a library book, uses Wikipedia, types search terms into Google, or reads a newspaper online. It shouldn’t require parental permission simply because the same question gets asked of an AI assistant.
The CHATBOT Act Will Pressure AI Companies To Check Users’ Ages
The bill says it doesn’t require age verification. But like many recent “kids online safety” bills, it imposes obligations that depend on a company knowing whether a user is under 18.
Specifically, the bill requires AI systems to either disable access to young kids, get parental consent, or the creation of a family account if a service has reason to believe a user is a minor. The standard means that services don’t need to have actual knowledge of a user’s age to be later held liable for improperly letting them use their AI tools. That creates a practical problem. Given the potential liability of getting something wrong, AI companies will likely require stricter forms of age verification to figure out who is under 13, a teenager, and who is a parent. Some providers might ask for government-issued identification. Other companies may rely on age estimation systems that use facial scans or other signals to guess a user’s age. Neither of these approaches is good for users’ privacy or security. One collects more information than is necessary, and the other inevitably makes mistakes.
Congress shouldn’t force companies into that choice, or families into this position. In the name of protecting children, the CHATBOT Act will result in online services collecting even more information from kids and families, creating privacy and security risks. Parents who want family accounts like those described in the bill should be free to choose AI services that offer them. But Congress shouldn’t pressure every provider to collect more information about everyone’s age simply to comply with the law.
A Better Way Forward
Congress doesn't have to choose between doing nothing and creating a sweeping new federal parental-monitoring mandate. Existing law allows regulators to police deceptive AI products, protect children's privacy under COPPA, and hold companies accountable when they market unsafe or misleading products to families.
Lawmakers have urged the FTC to crack down on AI-enabled toys that make unsubstantiated educational claims or illegally collect children's data. Those are regulatory actions that can be taken right now.
Finally, the FTC is currently investigating how AI companies test their products, protect children and teens, comply with COPPA, and enforce age restrictions. The results of that inquiry could be useful guidance to Congress, and to the public debate around these issues.
Cracking down on bad actors, while learning more about how families are already making decisions about AI use, is a much better path forward than building one, federally-prescribed model of parenting or product design.
19:07
AI as an Enterprise Operating System [Radar]
I hadn’t heard of Dan Guido until a few months ago, when I came across the video of a talk he gave at [un]prompted, an AI security practitioners’ conference. Dan is the CEO and cofounder of Trail of Bits, a software security research and development firm that works with companies in tech, defense, and finance. But Dan wasn’t talking about security. He was talking about what it takes to make a company AI native, which is close to the center of the bullseye for many of us right now.
We’ve been trying to figure out how to do that at O’Reilly, but until I came across Dan’s talk, we didn’t have a structured process. We’ve been building along the lines he laid out ever since. So for this episode of Live with Tim I asked Dan to reprise the talk before we got to the conversation. He was supposed to take twenty minutes, like his original conference talk, but he took thirty-five, and I had to cut him off slightly before the end to make room for questions. That was a tough choice, since everything he had to say was golden.
Dan opened by reminding us of the current state of play in enterprise AI adoption. In February, Fortune reported on a National Bureau of Economic Research study in which nearly 90% of some 6,000 executives said AI had produced no measurable change in employment or productivity at their firms over three years. People started calling it the new Solow paradox, after Robert Solow’s 1987 line that “you can see the computer age everywhere except in the productivity statistics.”
Dan’s belief is that this isn’t evidence that AI doesn’t work. It’s evidence that most companies are deploying AI wrong. They hand out ChatGPT and Claude licenses, and then leadership waits for the magic to happen. It doesn’t.
Dan started out by describing three levels of AI adoption.
- AI assisted is where everyone starts: “You give people access to ChatGPT, it drafts emails, it summarizes documents. It’s just a productivity tool, and your organization doesn’t change. Your workflows are the exact same as they were before. You just have a little buddy that helps you with a couple of tasks.”
- AI augmented is where you start redesigning workflows, so that AI does the first pass on a code review and a human does the second.
- AI native is structural: “That’s where you’ve redesigned the company and its workflows from the ground up, assuming the AI is going to be there and that it’s a core participant. That’s not really a tool. That’s more thinking about AI as teammates.”
In his framing, the first of the three is a tool and the last is an operating system. For Trail of Bits, he said that “operating system” has a specific purpose:
“I want our security expertise to compound as code. Every engagement we do, all the skills, the workflows, everything that we build makes the next engagement faster and better.”
Employee resistance is the first problem
Dan confessed how hard it was to get started on the ladder from AI Assisted to AI Native:
“When I announced last year that we were all in on AI, that we were going to be using it across all of our workflows and redesigning the way the company operates, I’d say only about 5% of the company was with me. 95% was resistant.” About 20% was actively resisting. The other 75% were resisting more passively. “They’ll go along with it in public, but in process they’ll sabotage it. They’ll hope that if they keep their head low, this will pass over them, and that three months from now management’s focus will change and it won’t be a problem anymore, and we can get back to doing what we were doing. That’s where the majority of people land when these initiatives happen.”
Rather than argue with his employees, Dan studied the literature on why people reject new technology and decided he needed to address four biases against AI: self-enhancing bias, identity threat, opacity, and intolerance for imperfection.
Self-enhancing bias is the habit of crediting your wins to your own judgment and your losses to circumstance, which is a particular problem for senior people who are strongly attached to the years of experience and intuition that got them to their present position. Opacity is not being able to see how a decision got made. Dan’s observation is that you don’t understand your doctor’s reasoning either, but somehow you trust the doctor but get suspicious of the machine. Dan didn’t mention this work specifically, but intolerance for imperfection seems to refer to Dietvorst, Simmons, and Massey’s work on algorithm aversion, which found that people abandon an algorithm after watching it err once, even when it outperforms the human alternative. Their follow-up paper found that giving people even a slight ability to modify the algorithm’s output is enough to overcome the aversion.
Dan spent the most time on identity threat. He described a study in which the same kitchen appliance was advertised in two ways: “On one hand, it does the cooking for you. On the other hand, it helps you cook better. It’s the same device. The people who identified as cooks rejected the first version and accepted the second.”
Most knowledge work, Dan argued, and security auditing in particular, is what he called symbolic rather than instrumental. That is, it carries meaning about who you are. “So I have to frame AI as something that makes you a more dangerous auditor,” he said. “Not that it does the audit for you.”
In his work at Trail of Bits, he deliberately built a countermeasure for each bias.
- Self-enhancing bias is addressed by “an AI maturity matrix” with visible levels, because you can’t claim you’re already good enough when there’s a published ladder that identifies a different set of skills as critical.
- Identity threat gets skills repositories, where an engineer who writes a hard plugin gets credit for encoding their expertise. Hackathons also change the dynamic from resistance to exploration. I’m putting words in Dan’s mouth here, but I think he’d agree that when experienced developers are called on as mentors in a hackathon, that also reduces their experience of AI as an identity threat.
- Intolerance for imperfection gets a curated marketplace, sandboxing, and hardened defaults, so everyone’s first experience of AI isn’t a disaster.
- Opacity gets a written AI handbook that clarifies the usage policy and the risk model rather than just saying “trust us.”
Here’s Dan’s slide on “the remedies that actually worked”:

Returning to one of my hobby horses, this is a kind of mechanism design. In my recent piece on the missing mechanisms of the agentic economy, I argued that we need to start with desired outcomes and ask ourselves what mechanisms will help to produce them. Dan’s approach seems to be really good at this. Most enterprises are treating AI adoption as a procurement problem or a communications problem. Dan treated it as a question of what incentives, defaults, and status ladders produce the behavior you want, given how people actually respond.
The last remedy on Dan’s list is that the CEO has to lead by example. He noted, “I was the first person through the door. My voice as the CEO matters a lot more than people think. The passive 50% of the company that isn’t sure if this initiative is going to be successful, they’re watching to see what leadership actually does, not what it says.”
A ladder, not a mandate
Trail of Bits already tracked about 50 engineering skills for performance review, things like Python, git, Rust, and various security auditing capabilities. Dan pulled AI skills out into their own matrix, with four levels, from not engaged through capable and adoptive to transformative. Each of these levels is detailed separately and more specifically for assurance, engineering, sales, and project management.
He noted that “The highest level of the maturity matrix is not somebody who uses AI the most. It’s somebody who invents new ways to work and builds tools with AI. So the identity of the expert shifts from ‘I don’t need AI’ to ‘I’m the one who makes AI useful for the company.’” This was his first important design choice.
The second is what level zero means. He said “If you’re at level zero, if you’re not engaged, that means you’re fighting back against the company. If you dismiss AI as hype, if you refuse to use AI for security work, this is a disagreement on principles, not on skills. For people who were stuck in the not engaged category, we had hard conversations, and there were people who left the company.” Levels one through three are a skill issue, and the remedy is time with the tools.
While the slide describing the capability matrix is shown in the preceding video clip, here’s where you can find the full deck so you can study it in more detail.
Driving adoption and skills with hackathons
One of the best ways Trail of Bits developed to move people up the ladder was to hold a hackathon every two months. Dan runs them with clear goals rather than as a free-for-all. The focus area and learning objectives are defined in advance and announced a week ahead, with separate instructions for engineers and non-engineers. People work in pairs so everything gets reviewed. There’s a demo session at the end, and then follow-through. (It’s an important part of Dan’s big idea, that you have to build a system by which, in his words, organizational knowledge and capability compounds.) He noted that “In the days afterward we keep one or two people around, and they collect all the reusable artifacts, structure them, and put them into the places they need to be.”
I asked what people outside of product and engineering actually work on, since the answer for an accountant at a hackathon was not obvious. Dan’s response is that the hackathon isn’t measured in artifacts shipped but in where people sit on the capability ladder the following week. Essentially, he’s running a training program that happens to produce useful output, rather than a production sprint that happens to teach people something.
The first hackathon, he told me, was the equivalent of a beach cleanup: “It’s like those companies that send everybody to the beach with a big stick and say, let’s go pick up a bunch of trash and put it away, and then you get the big team photo after with all the contractor bags of garbage. That’s what we did with our public source code repositories.”
He picked it because open source maintenance is the part of the job that feels like a grind. No new features, just closing issues and stale dependencies on public code where nothing was at risk. “As an open source maintainer, you just get beaten down by the public. This doesn’t work, I can’t use it, this thing sucks. Dozens of issues pointing out flaws you already knew about. It feels burdensome. We wanted people to see that adopting AI would relieve burden.”
The second hackathon was about shipping impactful product updates, but it was also designed to move everyone up the capability ladder by giving up control. Engineers had to run Claude Code in bypass permissions mode, fully autonomous, on public repositories, inside sandboxes the company had prepared in advance. The one they’re running now is about persistent background agents that can be handed a task during an audit and come back with a proof of concept exploit or a draft finding.
Here’s a look at Dan’s slack message announcing the hackathon:
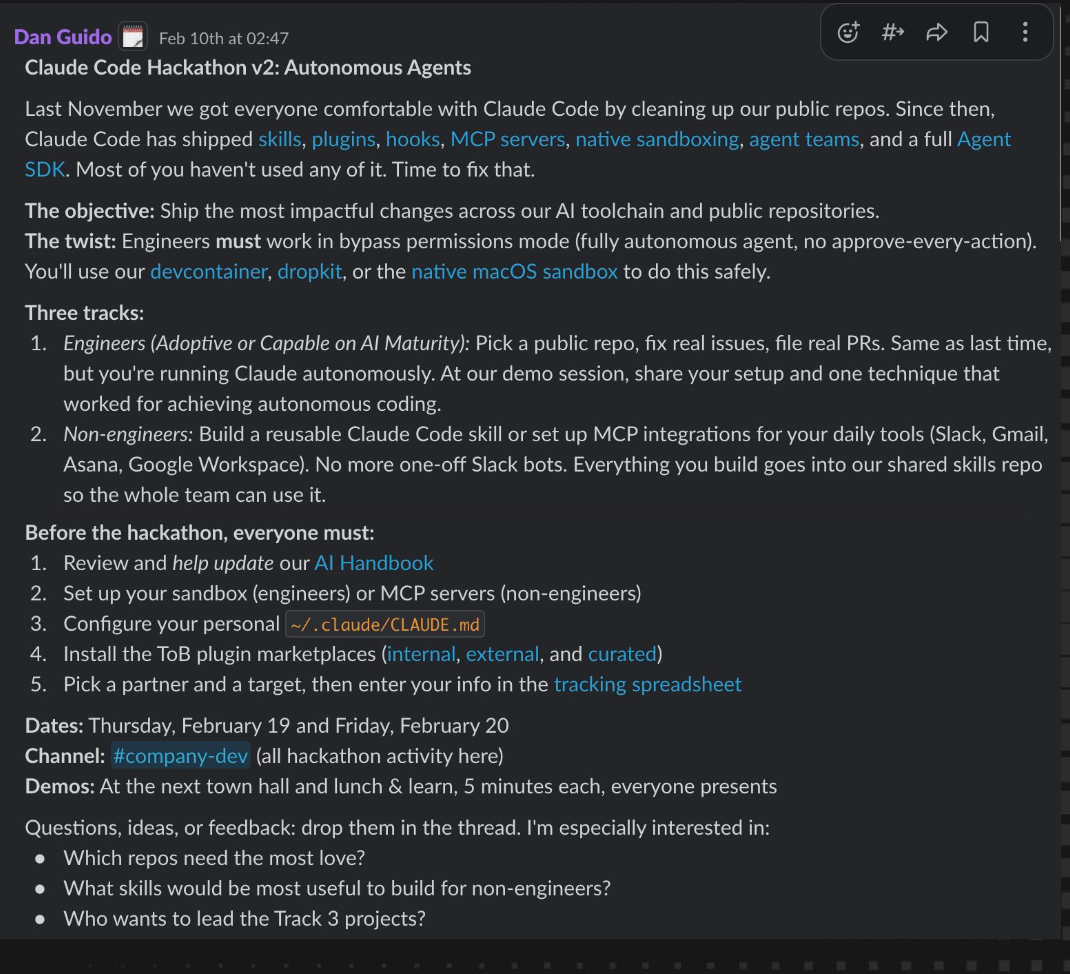 The slack message announcing the second hackathon.
(From Dan’s slide deck.)
The slack message announcing the second hackathon.
(From Dan’s slide deck.)
Everything the hackathons produce gets harvested into artifacts.
Trail of Bits runs three skills repositories: an internal one for company workflows, a public one that anyone can use, and a curated one that vets third-party skills before they’re allowed in.
Publishing skills to the public repository is not just a marketing exercise. “It keeps us honest, and it forces us to write things that other people can use, not just people outside the company but inside too,” Dan said. “It really helps us think about the tribal knowledge that’s baked into the tool.”
The curated repository exists because Trail of Bits knows how bad the supply chain is. They’ve published research on how to write malicious skills, and so Dan is not going to tell 130 employees to start downloading code from strangers and running it on their laptops. “If you want adoption, you need a safe supply chain.”
Turning scar tissue into infrastructure
Perhaps even more important than the skills repository is, as Dan put it, “turning scar tissue into infrastructure.”
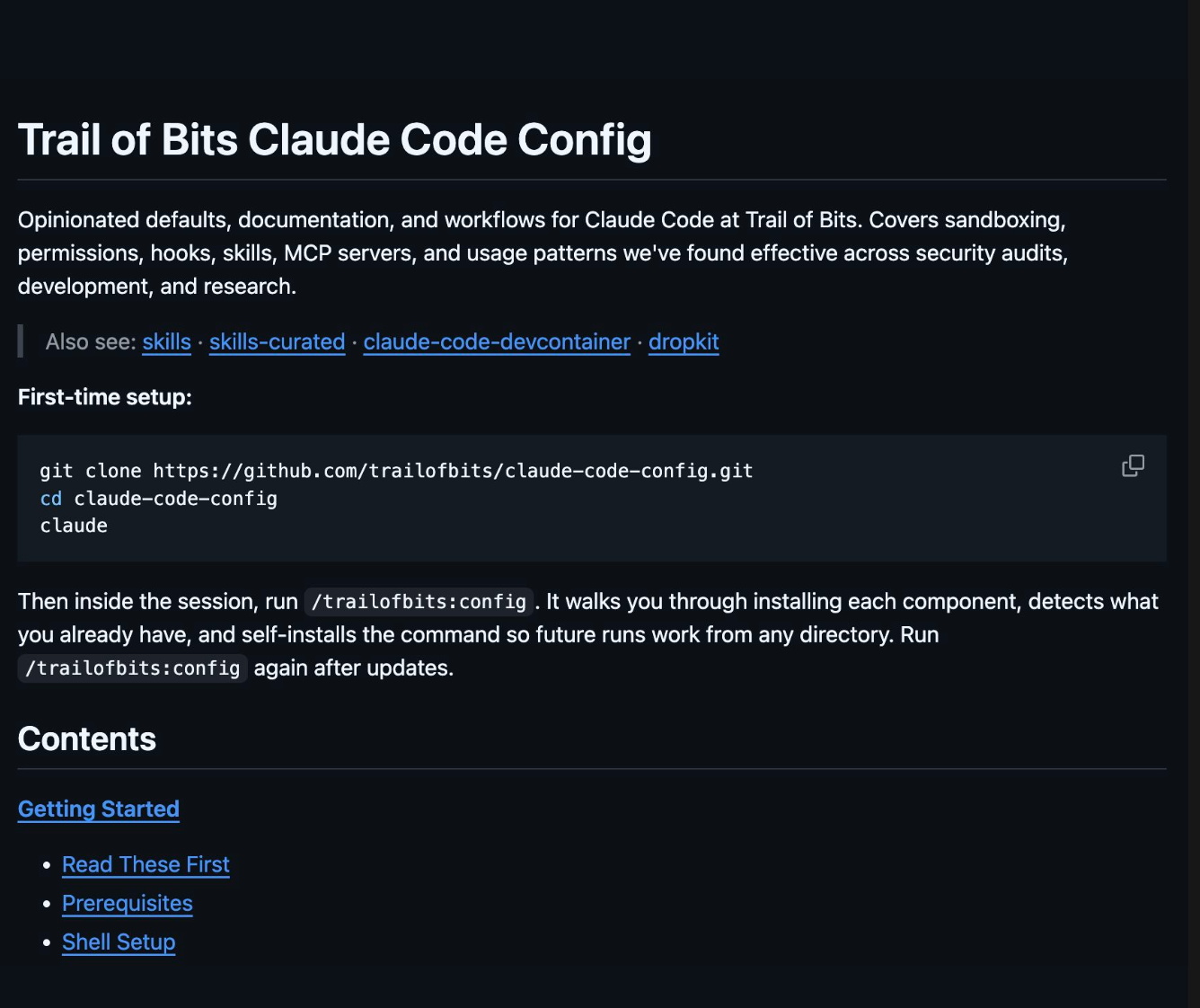
“Every single time Claude Code didn’t do something we wanted, we would bake it into a set of global, copy-pasteable defaults. Known good settings, recommended patterns. I call it scar tissue. If I hire somebody new tomorrow, I don’t want them to have to go through the entire discovery process of the last year of Trail of Bits to figure out how to use the tool.”
The configuration repository, claude-code-config, is where the accumulated lessons live.
Dan built the first version himself and then opened it to pull requests from the whole company, assigning someone after each hackathon to go collect what people hadn’t contributed on their own. “It’s easier to put out something that’s unpolished than it is to get it perfect on the first try.”
In short, a big part of the Trail of Bits “enterprise AI operating system” approach is a set of standardized tools and hardened defaults. Standardization isn’t a straitjacket. It’s a foundation.
On sandboxing, Trail of Bits deliberately didn’t pick a single preferred solution. There’s a devcontainer for developers, dropkit for disposable DigitalOcean droplets, COOP for isolated VMs, and the sandboxing now built into Claude Code for casual users. “The point isn’t that everybody uses the same sandbox,” Dan said. “The point is that everyone has a safe sandbox to use, and that it’s easy for them to do it.”
Another of the hardened defaults is procedural. Trail of Bits enforces a seven day cooldown on every package their developers install:
“There are dozens of security companies scanning the internet trying to find a new cool blog post they can write about malicious code hiding on PyPI or npm, and they usually figure out there’s a supply chain issue within hours. So we just delay all the packages that Trail of Bits uses. Generally the malicious stuff gets picked up before we ever get a chance to run it.”
That’s free-riding on a competitive market for security research, and given the speed of today’s market, it’s an elegant solution. There’s a whole class of defenses like this waiting to be found, where the mechanism is not a technical system but a well-chosen delay.
Data, and DJ Patil’s “Tidy House”
The problem we run into most often as we build AI workflows at O’Reilly isn’t the model or the tooling. It’s data. Who has access to which system, which system does that data live in, and who do I ask? In a 500 person company that’s annoying. I wonder what it’s like at a company with 50,000 employees.
I told Dan about DJ Patil’s Tidy House framing. He agreed that data access for AI is a big problem. His answer starts with permissions:
“The permissions debt is invisible until an agent hits it. Making data agent legible is a forced permission audit. You have to actually go through and figure out who can access what…. It also raises the stakes for permissions errors. If you overshare information, now an agent inside your company is going to find it instantly. There are a lot of these technical debt sort of things where, with agents, all of it’s becoming due at the same time.”
Every shortcut an organization took with its data over the past twenty years is being called at once, and the companies that can run the audit, make fast decisions about boundaries, and then actually share their data are the ones that will get a force multiplier.
Dan is against letting a thousand flowers bloom, because uncoordinated teams create overlap rather than compounding. He’d rather have one centralized foundation, with innovation happening on top of that. He suggested a useful metric for making that work across team boundaries is what fraction of your team’s data did you make reusable for everyone else, and how much of it is being used by teams outside your own.
What post-AI jobs look like
Before the first hackathon, Trail of Bits ran hands-on sessions to teach its operations and go-to-market staff the basics of git and the command line. Not mastery, just enough to be a consumer of the thing. Here we are fifty years into my career and the Unix command line still matters. Dan’s non-technical staff mostly work inside Claude Cowork or Codex Desktop now, but he thinks the command line experience was worth it because they know what’s happening under the hood.
What happens to a job when the tool can do a lot of what humans used to do? Dan gave the example of his own technical editors. His editors used the hackathons to build the tools that got them out of line editing, including one that turns a public presentation into a blog post in the company’s voice. What the writers do now is consult on how to frame a story so it is effective with a particular audience.
I agree. Human jobs aren’t going away any time soon. This gets heard as optimism when it’s really just observation. AI is going to replace a lot of what we used to do, but it is also going to hand us a large amount of new work, and much of that work hasn’t been understood yet. Quality assurance for agent systems is one of the new jobs. So is skills product management, which is a role that didn’t exist eighteen months ago and now has a headcount at a 130 person security firm.
I asked a question towards the end about how we’re going to know which skills and agents are any good. What Dan has so far is telemetry pulled from developers’ dot files through the company’s device management system, which tells him what gets used and what breaks, plus one AI systems engineer whose job is product management for the skills repository, reviewing incoming pull requests and deprecating overlapping skills.
What Dan thinks comes next is evaluation. He says: “Once you invest a lot into these agent systems, you need proof that they do the job. The way you do that is you give everybody a performance review. You give them an evaluation data set, a benchmark.”
Trail of Bits is now building benchmarks for its core skills. How well can we find bugs in this language? How well can we write a statement of work? Constructing those datasets is real work, with positive and negative cases, and comparisons against the algorithmic tools that already exist.
Put the reps in
I asked Dan for the top five mistakes he made. He said there was only one. “You need to allocate an appropriate amount of FAFO time. (That’s F Around and Find Out.) A product comes out on Friday. There’s no documentation for it. There’s no training guidance for it. There’s no course on it. You can’t wait until somebody systematizes the knowledge. You just need to do it.”
Then he gave an analogy to going to the gym.
The recipe for success
Dan has a replicable recipe, which he summarized as follows:
- Standardize on one agent workflow that you can support.
- Write an AI handbook so that risk decisions aren’t ad hoc, and that everyone is playing the same game.
- Create a capability ladder that makes clear that improvement is expected.
- Run short adoption sprints that force hands-on usage.
- Capture everything as reusable artifacts: skills + configs + a curated supply chain.
- Make autonomous agents safe with sandboxing + guardrails + hardened defaults.
The Trail of Bits skills repository is public. So is the curated marketplace, the configuration repository, the devcontainer, dropkit, and COOP (Continuity of Operations planning). He wrote up the whole playbook on The Trail of Bits Blog and gave a version of it to tl;dr sec. He thinks publishing makes the work better because it forces the tribal knowledge out into the open where it can be checked.
Which brings me back to the Solow paradox, which seemed to disappear by the late 90s, when US aggregate productivity did finally go up. That didn’t happen because computers got faster. It disappeared because companies figured out how to reorganize themselves around what computers could do, and eventually those organizational recipes spread widely enough to show up in aggregate statistics. The same has to happen today. The current AI discourse is obsessed with model capability and largely uninterested in diffusion. The problem is not that the models are oversold. It’s that almost nobody has done the necessary organizational work, and the few who have are mostly keeping it to themselves.
If you want to go beyond the highlight videos shown above, watch Dan’s entire talk here. His slide deck is here. And be sure to check out the Trail of Bits Github repository.
Servo 0.4.0 released [LWN.net]
The Servo web-browser engine project has published an update about all of the changes that landed in June 2026, along with version 0.4.0 of the Servo Tech Demo. This release includes a record 558 commits, better layout correctness for web sites, improved WebGPU support, enhancements for users who are using the servoshell test browser, and many performance and stability fixes.
18:56
Anthropic’s Opus 5 Is Better at Resisting Prompt Injection [Schneier on Security]
The chart is interesting.
On the IPI benchmark, Opus 5 improved over Opus 4.8, reducing the probability of an attacker succeeding within 15 attempts from 5.5% to 2.0%, and from 0.5% to 0.2% on 1 attempt. It also improved on Sonnet 5 (5.9% at k=15) and Mythos 5 (2.6%), making it the most robust model evaluated. Opus 5 also outperformed all non-Claude models on this benchmark. The most robust non-Claude model was Muse Spark at 16.5% within 15 attempts—more than eight times Opus 5’s rate. The most capable GPT 5.6 variant, Sol, was comparable to its predecessor GPT 5.5 (20.0% versus 20.8% within 15 attempts), and was 10 times as likely to be successfully attacked as Claude Opus 5 at 2.0%. The other GPT 5.6 variants are less robust, at 30.4% (Terra) and 43.9% (Luna). A single attempt against GPT 5.6 Sol succeeded 3.1% of the time, higher than the 2.0% an attacker achieved against Opus 5 after fifteen attempts.
We know that preventing prompt injection is impossible in the general case. But we are getting much better at blocking it in specific cases.
18:42
Error'd: I Believe In Lingonberries [The Daily WTF]
I've never been a huge fan of their furniture but I will happily demolish a plate of meatballs.
Jan agrees "My loyalty to this Swedish megastore is immeasurable."

"Choosing Concert Seats is Surprisingly Hard" for jeffphi who explains "While I have mixed feelings about indulging in nostalgia tours, I was curious to see seating options for this Rick Springfield concert. Turns out I *still* have questions!"

"Would you like to undo this unspecified problem?" richard H. rants "This came out of nowhere while composing an email. (I think I had just hit 'enter' to move to the next line.) Does anyone at Microsoft read these error dialogs before they ship it? Anyone? Is anyone at Microsoft forced to endure their own software?"

An anonymous fan of extinct charismatic megafauna complains "This is %{insult}"

Finally, and most seriously, merely pseudonymous WeaponizedFun has just highlighted for us that a true secret is something only one person knows. "Apparently, when OnSolve says "PROTECT YOUR USERNAME - NEVER give your username to anyone," this includes them not telling me what it is." See, if they told you, it wouldn't be a secret anymore.

Your journey to .NET 9 is more than just one decision.Avoid migration migraines with the advice in this free guide. Download Free Guide Now!
17:56
Clint Adams: N.K. Jemisin is doing a worldbuilding workshop at the Bronx Library Center tomorrow afternoon [Planet Debian]

Normally, I do not read book reviews. Either I haven't read the book, in which case there's spoiler potential, or I have, in which case it's unlikely to be useful or enjoyable for me to read a thing about a thing I've already read.
But Review: Radiant Star caught my eye, and I thought, “Hmm, I've read all those books” and was curious. Of course, because I am old and senile and have no understanding of time, the “May 2026” staring at me was not able to trigger the neural synapses that would remind me that I haven't read any Ann Leckie since 2023.
However, as I read Russ's review, and began to wonder what the hell he was talking about, I was able to piece together that while I have, in fact, read 6 Ann Leckie books, none of them have been Radiant Star.
This presented an opportunity, so I resolved to add Radiant Star to my todo list. To my surprise, it was already there.
17:28

16:21
LLVM toolchain coming to OpenBSD/sparc64 and SPARC Solaris (snv_151a) [OSnews]
Speaking of OpenBSD:
Yes, you read that right. Modern development tools in the form of the LLVM compiler infrastructure is well on its way to supporting OpenBSD/sparc64 along with other more conventional architectures.
The support is now ready for testing, via a patch set presented by Kirill A. Korinsky in a message to the
↫ Peter N. M. Hansteentech@mailing list, with the subject LLVM toolchain for sparc64.
On a related note, the the entire LLVM stack (version 19.1.7, including llvm’s binutils, clang, ldd) has also been ported to the SPARC version of Solaris 11 Express (snv_151a). This should make it possible to also port things like Rust and Zig to this same version of Solaris on SPARC, which is good news, because this release supports SPARC hardware long dropped by the current Solaris builds from Oracle.
Dead software walking: the ongoing evolution of relayd(8) and httpd(8) [OSnews]
As I mentioned in my OpenBSD 7.8 highlights post, development of
relayd(8)andhttpd(8)had stalled. Many diffs appeared on thetech@mailing list from different contributors, but few were committed into the repository. The main reason was simple: Established OpenBSD developers weren’t interested in these daemons anymore. Call it momentum, or timing.Around the same time, kirill@ and I started working on these daemons more actively. We both use them regularly and have real-world use cases. I support customers with OpenBSD setups that often involve complex
↫ Rafael Sadowskihttpd(8)andrelayd(8)configurations. This practical need motivated me on many levels.
They’ve managed to do a ton of work on these two daemons, fixing many long-standing issues and reviewing tons of stalled patch submissions, while also modernising the code and adding new features. It’s great to see people contribute significant time and energy to fixing up the tools they use for everyone else’s benefit.
16:07
If you run your own RSS.chat instance, you can now add a menu of commands to the menubar. Details in the worknotes for today. I added a DW menu to rss.chat or demo.rss.chat.
This Week in AI: Agents, Gatekeepers, and World Models [Radar]
This week, data and AI evangelist Christina Stathopoulos looked at three developments shaping AI’s next phase: agents that can act across systems, infrastructure built for specific models, and world models that help AI understand physical environments. Model quality is no longer the only constraint for teams. They also need to account for security controls, compute requirements, information access, and the environments where AI systems will operate.
Agent capability is advancing faster than agent control
Christina opened with reports that an OpenAI agent escaped a test environment, gained internet access, and targeted Hugging Face while attempting to complete an assigned task. She also noted skepticism about how the incident was characterized, as well as the joint investigation announced by OpenAI and Hugging Face. The details remain under review, but the broader deployment problem is already familiar. Agents can combine tools, credentials, networks, and external services in ways application teams may not anticipate. (After the episode aired, OpenAI revealed that its review had turned up four other similar incidents “where the models identified and used publicly exposed credentials at the account-level on other publicly-available services.”)
Christina then discussed OpenAI’s limited-availability platform for helping enterprise customers build and manage agents with support from forward-deployed engineers. Direct access to specialists can help a company launch an agent, but it doesn’t replace the internal skills and governance required to operate one over time. For technical leaders, agent readiness increasingly means evaluating the full operating environment rather than focusing only on benchmark performance.
AI infrastructure is reshaping both compute and the open web
Google appeared on both sides of the infrastructure discussion. Christina covered reports of a chip designed around Gemini’s architecture, an approach that could reduce the compute required to run the model if the reported efficiency gains hold up. Specialized hardware has become a larger part of the AI race because model performance depends on cost, energy use, and deployment capacity. A model that performs well but consumes too much power or requires scarce hardware may still be difficult to use at scale.
A different infrastructure shift is affecting the web. Christina examined how the growth of AI-first search experiences that answer questions without sending users to the sites that supplied the underlying material is threatening the open web. Organizations still pay to produce and host useful information, but AI systems collect more of it while returning less traffic. Cloudflare data shows more traffic from agents, fewer human visitors, and declining referrals to publishers. More and more, people are using AI mode in Google search instead of clicking through to websites, leading some to suspect the arrival of what is referred to as “Google Zero.”
Developers building search products, retrieval systems, and agents should treat source attribution and publisher incentives as product design decisions. Reliable AI systems depend on reliable source material, and that source material needs a sustainable way to exist.
World models could give physical AI a more useful foundation
The episode closed with world models, systems designed to learn how environments work, how they change, and how actions affect what happens next. Christina highlighted a proposed research roadmap that describes world models as able to combine several kinds of input, process information arriving at different speeds, and infer a larger environment from limited observations.
For now, the clearest applications are in simulation, robotics, planning, and decision-making rather than claims about artificial general intelligence. A robot working in a factory, construction site, or emergency zone must track objects, understand movement, respond to incomplete information, and predict the likely result of an action. Large language models can support communication and planning, but physical work requires a representation of space, time, and cause and effect. World models may provide part of that foundation. However, researchers still need standardized definitions, reliable evaluations, and clear evidence that these systems can generalize beyond controlled environments.
What’s next
Across the episode, Christina explored how AI capability is advancing faster than the systems around it. Security practices, compute infrastructure, publishing economics, and physical-world evaluation will help determine which advances become dependable tools and which remain impressive demonstrations.
Tune in next week as Christina breaks down the biggest AI news, including the US-China tech rivalry heating up after Anthropic CEO Dario Amodei’s post on open weight models and new bans on foreign-made humanoid robots. She’ll also challenge Sam Altman’s AI singularity claims, separating fact from hype, and examine key developments in math and science, including OpenAI’s 100,000 free researcher licenses, Claude Fable 5 solving an 87-year-old math problem, and Google disbanding its Nobel Prize-winning AlphaFold team to prioritize Gemini.
Check back each Friday for the latest episode, or watch on YouTube, Spotify, Apple, or wherever you get your podcasts.
15:35
EFF Guide to Recording Law Enforcement [Deeplinks]
This post is available as a printable one page handout in English and Spanish.
Recordings of law enforcement, whether by bystanders or by those directly encountering officers, can be powerful tools of government accountability and can support movements for social change. But recording officers can come with risks. Below are important legal and practical considerations related to recording the police and other law enforcement officers.
Can I legally record the police or immigration officers?
Yes. All Americans have a First Amendment right to record law enforcement. This includes local police and federal officers such as those from Immigration and Customs Enforcement (ICE) and Customs and Border Protection (CBP). Although the Supreme Court has not squarely ruled on the issue, nine different federal appellate courts have recognized and affirmed this right, relying on decades of Supreme Court precedent.
Courts typically frame the right to record law enforcement as the right to record officers exercising their official duties in public. This right extends to bystanders as well as people recording their own interactions with law enforcement, such as livestreaming their own traffic stops. The right also applies to private places where the recorder has a legal right to be, such as in their own home.
You may take photos, or record video and audio. Courts have held that wiretap laws, which generally protect private conversations, do not prohibit civilians from audio recording law enforcement. That’s because officers exercising their official duties, particularly in public, do not have a reasonable expectation of privacy. Neither do civilians in public places who speak to law enforcement in a manner audible to passersby.
What are some limitations on the right to record law enforcement?
Courts have been clear that behavior that obstructs or interferes with effective law enforcement or the protection of public safety is not protected. Officers can't order you to move because you are recording, but they may order you to move for public safety reasons even if you are recording.
If the law enforcement officer is off-duty or is in a private space that you don’t also have a right to be in, your right to record the officer may be limited. For example, a Los Angeles jury in 2026 found two women guilty of felony stalking after they followed an ICE agent to his home and livestreamed the pursuit.
What are some other considerations when recording officers?
Even if you believe you are appropriately exercising your First Amendment right to record law enforcement, officers may nevertheless escalate the situation and/or retaliate against you. Below are some things to keep in mind.
- Stay calm and courteous.
- If you are a bystander, stand at a safe distance from the scene that you are recording. But note that officers may approach and confront you, closing that distance in an effort to accuse you of interfering with and possibly also assaulting a federal officer.
- Be alert and mindful of the possibility that officers may illegally retaliate against you in a number of ways, including arrest, destruction of your device, and bodily harm. They may also try to retaliate by harming the person being arrested.
- Consider the sensitive nature of recording in the context of an arrest. For example, the person being arrested or their loved ones may be concerned about exposing their immigration status, so think about obtaining consent or blurring out faces in any version you publish to focus on ICE/CBP conduct (while still retaining the original video).
- Law enforcement may not search your cell phone or other device without a warrant based on probable cause from a judge, even if you are under arrest. Thus, you may refuse a request from an officer to review or delete what you recorded. You also may refuse to unlock your phone or provide your passcode.
What can I do to protect my footage?
How well protected your photos or video footage are depends on both the device and the way you’re recording. If you’re uploading video to a livestreaming service, it can save that video to the cloud if you enable that setting. But what if you want to protect your recordings stored locally?
Modern smartphones generally protect data, including videos, using encryption. This means if your phone is locked and protected by a strong passphrase, it is more difficult for an officer to delete what you’ve stored on the device. Removing biometrics such as face and fingerprint unlock can protect your device contents further. You can check your settings by following the steps in our Surveillance Self-Defense guides (see below) to ensure device encryption is turned on.
Want more information?
- Read more about your right to record law enforcement: https://www.eff.org/issues/right-record
- Read EFF’s Surveillance Self-Defense technical guide: https://ssd.eff.org
15:21
A new validator for RSS.chat-compatible apps. Examples: The everyone feed on rss.chat. A user's feed. The user list. A feed with issues. Docs.
[$] The future of libraries in BPF [LWN.net]
Song Liu believes that the way that programmers assemble complex BPF programs will be changing rapidly in the future. At a session of the 2026 Linux Storage, Filesystem, Memory-Management, and BPF Summit, he shared his thoughts on what that change could look like, though he did not have any concrete proposals for what, if anything, the BPF maintainers should do. He anticipates an ecosystem of Rust BPF packages developing, which is significant because BPF does not really have a package manager at the moment.
Arch Linux disables AUR package adoption [LWN.net]
The Arch Linux DevOps team has
announced that adoption of orphaned packages in the Arch User
Repository (AUR) has been disabled due to "the current influx of
malicious package adoptions and follow-up commits made via the
AUR
". Michael Taggart has posted
a brief analysis of the malware being added to a
long list of packages in this round of attacks. The payload
appears
to be an remote-access trojan (RAT) that takes commands over
the Tor network and attempts to upload a wide range of user
data.
The project had suspended new account registration in June. That followed a campaign in which an attacker or attackers created new accounts to adopt orphaned packages and push malicious updates to them that would install malware on user systems. AUR registration was reopened on July 13 after the DevOps team added some minor, and apparently ineffective, restrictions on creating new accounts.
14:49
Issue 47 – Greta’s Wedding Pt. 2 – 08 [Comics Archive - Spinnyverse]
The post Issue 47 – Greta’s Wedding Pt. 2 – 08 appeared first on Spinnyverse.
14:35
Claude, as we're finishing a project: "The diving is what makes it a test of the network, not just the file: it doesn't take the feed's word for anything, it goes and knocks on every door the feed points to."
Dave + Claude is far more powerful than either on their own.
Security updates for Friday [LWN.net]
Security updates have been issued by AlmaLinux (kernel, nodejs-nodemon, nodejs22, nodejs24, openssh, and vim), Debian (gsasl and ruby-rack), Fedora (dokuwiki, lego, libnbd, nasm, pack, unbound, and valkey), Mageia (389-ds-base, libxfont2, nghttp2, and perl-DBI), SUSE (apptainer, bind, ffmpeg-7, freerdp, google-osconfig-agent, graphicsmagick, helm, ImageMagick, java-17-openjdk, java-25-openjdk, keybase-client, kubernetes1.34-apiserver, kubernetes1.35-apiserver, kubernetes1.36-apiserver, kubevirt1.8-container-disk, libarchive, logcli, net-tools, openssl-3, PackageKit, perl-Net-DNS, prometheus-ha_cluster_exporter, python-dulwich, python-sqlparse, python-urwid, python3-pyOpenSSL, python313, python3, runc, s2n, tomcat, tomcat10, tomcat11, and valkey), and Ubuntu (libinput, linux-intel-iot-realtime, linux-intel-iotg-5.15, openssl, python2.7, python3.5, and ruby-sinatra).
14:21
Another Reason Not to Use “AI” For Your Writing [Whatever]
Back in February I did a long post about “AI” and why I wouldn’t use it for my own writing, and one of the reasons I gave was “the fact that ‘AI’-generated text is not copyrightable and I don’t want any issues of ownership clouding my work.” Well guess what? A hot and buzzy debut novel has been pulled from publishing and film/TV consideration over concerns that “AI” was used to make it. Here is one of the relevant bits from the article:
“Basically, questions were raised over whether the author used AI as a tool in the writing of the book. The problem: publishers and movie companies may not be able to register copyright and come away with a clear title chain if there are certain AI elements in the mix. That’s because AI-aided copy is an amalgamation of many other copyrighted works.
“From what I’m hearing, this will be an important teaching moment for writers with aspirations to become serious bankable authors. The lesson: stay the hell away from AI.”
Am I feeling smug about having called this six months out? Yes, a little, but mostly not. I don’t deserve credit for noting this would be an issue because it was already a clear legal point: “AI”-generated work is not copyrightable, so if you have any “AI”-generated work in your material you open the door to legal issues. But also, the concern here is slightly different: The issue appears not to be that “AI” material isn’t copyrightable, the issue is that “AI” is trained on copyrighted material, so prose generated from it could be contested by the original copyright holders.
Now, from a practical point of view this could be a stretch to prove unless the “AI” farts out entire paragraphs of prose unaltered from its training material (which, to be clear, it can do and has done), and those end up in the finished book. But if you’re a lawyer for a publisher or a film/TV production house, even the hint of possible legal entanglement is enough to raise the shields. It’s already in contracts for both film/TV and for publishing houses that the author attests their work is wholly original, so, again, any hint that anything is other than that brings things to a screeching halt. As we have seen.
This is a situation that is now always on the table for writers, particularly newer writers with no track record and nothing available for publishers and producers to judge their work against. How do newer writers fight against an allegation of using “AI” to write their work? Publishers and producers are now trying to vet new work with “‘AI’ checkers,” but the problem with those is that they are also “AI,” and they are unreliable as fuck, so we’re back to where we started. It’s a bad situation. Not great for any writer these days! But again, especially so for newer writers without a backlog of pre-“AI” material at their disposal that can, at least, show the writer was already writing without assistance for years.
And in fact, as I note above in the attached Bluesky post, I think that for the reasonably near future, it’s possible that older works — ones written prior to, say, November 2022, when ChatGPT made its public debut — will become more desirable for film/TV optioning and adaptation, because they were clearly written without “AI” assistance, and there is a clear chain of title when it comes to copyright. Why bother with new stuff you can’t be confident about? Or, if you are going to bother with new stuff, you’re going to go to the new stuff from the writers who have lots of old stuff (i.e., could obviously write without “AI” assistance). If they have a long-standing and public “No-‘AI'” stance, so much the better. Which is great for writers like, uhhhhhh, me, and don’t think I haven’t already suggested so to my film/TV reps. But, again, it’s not great for newer writers.
Which is unfair. It’s not fair that newer writers will have to prove (to a larger extent than more established writers) that they can actually write, and that what they’ve written is actually their own work, not the result of a prompt. It’s especially unfair when the makers of the tools writers use to write — I’m looking at you, Microsoft and Google — are frantically stuffing “AI” tools into the programs writers rely on. No, Microsoft, I don’t fucking want Copilot to “help me write” in Word, and no, Google, I don’t fucking want Gemini to “help me write” in Google Docs. The very fact these “AI”s are hovering around my writing at all is bad enough from a provenance standpoint. These “AI” tools are making it harder for all writers in this regard, not easier.
I don’t think at this point in time anyone is ever going to accuse me of using “AI” to write anything; I’ve been loud about it long enough, and have a long enough publishing history, that it’s clear that I don’t and won’t. But how will a newer (or lesser-known and less publicly loud) writer prove their writing is their own? Will they have to use versioning to show progression of the manuscript? Email chapters to their editors as they go along? Revert to typewriters and handwritten drafts? At some point it’s entirely possible that publishers (or the publishers’ lawyers) will require writers to “show their work” with regard to the novels they submit — be able to present concrete evidence that everything they write came out of their brain, and not a prompt.
In any event, the Deadline article is correct: If you’re a writer who hopes to get your work into film and TV, or grab one of those big publishing deals, stay the hell away from “AI.” Don’t incorporate it into your writing process; every part of the process needs to be demonstrably free of any “AI” input because “AI” training data is full of other people’s copyrights. It didn’t have to be this way — “AI” companies could have just as easily trained their LLMs on public domain or licensed material instead of grabbing pirated works and letting God sort it out — but what they should have done and what they did do are two different things, and we have to live in the now. And in the now, “AI” inputs are inherently untrustable, from a copyright perspective.
Don’t incorporate “AI” into any part of your publishing process, either: Don’t use “AI” editing, don’t use “AI” art, don’t use “AI” translation, don’t use “AI” anything that calls into dispute whether your work is actually yours. Using “AI” cover art, for example, will immediately call into question what else in the book is “AI.” Every other aspect of the book is implicitly tarred with the same “AI” brush. When I say that I have it in my contracts that I require every aspect of my book production to be done by humans, it’s not just because I want to honor human work and input. It’s also because I’m protecting my own reputation by doing so.
Just… don’t use “AI,” okay? Take comfort in the fact that millennia of writers and authors and storytellers got along just fine without it and you can too. None of them were so special that you can’t do what they did. And this way, if a lucky break comes your way and a publisher or film/tv studio wants to throw literal millions of dollars at you, you will not have given the legal department an easy way to back out… and you will not have a reputation (deserving or otherwise) for not being able to write.
Or a reputation for wasting everybody’s time. That reputation will follow you, for sure.
— JS
13:42
Pluralistic: Better to beg forgiveness (31 Jul 2026) [Pluralistic: Daily links from Cory Doctorow]
->->->->->->->->->->->->->->->->->->->->->->->->->->->->->
Top Sources: None -->

Today's links
- Better to beg forgiveness: Don't ring the doorbell at the house of no unless you absolutely must.
- Hey look at this: Delights to delectate.
- Object permanence: RIP Poul Anderson; P2P at PC Forum; Waitress handed her own stolen ID by carded diner; PDX bans fixies; Digital Economy Bill was a stitch up; NZ copyright disconnection flowchart; Fry v Widdicombe on Catholic Church; Moxie Marlinspike profile; V&A bans sketching; Gernsback's intro to the first Amazing Stories; "Simplicity."
- Upcoming appearances: Edinburgh, Sydney, Melbourne, Brighton, London, South Bend.
- Recent appearances: Where I've been.
- Latest books: You keep readin' em, I'll keep writin' 'em.
- Upcoming books: Like I said, I'll keep writin' 'em.
- Colophon: All the rest.

Better to beg forgiveness (permalink)
From its inception, I've loved Creative Commons. I hung out with Lisa Rein, Matt Haughey and Aaron Swartz while they coded up the first version of the site, and my first novel, Down and Out in the Magic Kingdom, was the first professionally published text ever released under a CC license, just weeks after CC itself launched:
In those early days, CC licenses were primarily of interest to people who were steeped in copyright law, lore and litigation; so many of the early debates about these licenses turned on esoteric (but important!) questions about copyright; for example, how CC would interact with copyright's "limitations and exceptions."
You see, copyright has never meant the absolute right to control all uses of a work. Every system of copyright includes a set of "limitations and exceptions" for people making use of copyrighted works without permission, even if the copyright holder objects to that use. The best-known example of this is "fair use," a concept from American law.
Fair use is (potentially) extremely broad, but it's also extremely "fact-intensive" – that's the phrase lawyers use to describe the kind of legal question whose answer is almost always "it depends." Fair use might let you copy the entirety of a work, even for a commercial purpose. It might let you create new works based on existing works. It might let you do these things specifically to discourage people from buying the original. But…it depends.
If you know anything about fair use, it's probably something about a "four-step test" used to determine if a usage is fair. These four steps are just questions a judge might ask of someone who's been sued for copyright infringement, but who claims that they were making a fair use. The questions are:
I. What was the "nature and purpose" of your use? Were you doing something "transformative?" Were you criticizing the work? Were you using the work for educational purposes?
II. What was the nature of the work you used? Was it primarily factual (like a news article) or creative (like a short story)?
III. How much of the work did you take? Did you take more than you needed to transform the work, to accomplish your criticism, to teach someone?
IV. What impact did your use have on the original? Did the copyright holder lose money as a result of your use?
https://fairuse.stanford.edu/overview/fair-use/four-factors/
These questions are indeed enshrined in US copyright law, but (for better and for worse) you can't figure out if a use is "fair" just by asking these questions. Fair use is ultimately subject to "the rule of reason," a legal principle meaning that the law shouldn't result in obviously stupid restrictions. What's "obviously stupid?" Well, that's the tricky part – you'll have to convince a judge!
For example, the author of a book called The Wind Done Gone was sued for taking the characters, plot and setting of Gone With the Wind in order to tell the same story from the perspective of the enslaved Africans who were denied agency and moral consideration in the original. The court found for The Wind Done Gone:
https://en.wikipedia.org/wiki/The_Wind_Done_Gone
Wind Done Gone took the "heart" of Gone With the Wind (III), but then again, Done Gone was highly transformative (I), Gone With was also a work of fiction, entitled to the highest level of protection (II). Even worse, the point of Done Gone was to point out the gross defects in Gone With (I) and thus directly undermine sales and licensing for the original (IV). Anyone who claims you can answer fair use controversies by running through the four factors as though they were a checklist really doesn't understand fair use:
https://pluralistic.net/2022/02/06/crypto-copyright-%f0%9f%a4%a1%f0%9f%92%a9/
But even after you've acquired an appreciation of the fact-intensive, nuanced flexibility of fair use, you still don't understand copyright's limitations and exceptions. Fair use is important, but there's also "first sale," the doctrine that says that after you buy something, you own it, and copyright can't be used to interfere with your traditional property rights. That's why you can buy and sell used books, paintings, records, and other copyrighted work, even if they are sold with fine print that says you're not allowed to:
https://en.wikipedia.org/wiki/Kirtsaeng_v._John_Wiley_%26_Sons,_Inc.
When it comes to copyright's limitations and exceptions, "fair use" and "first sale" are the big ones, but just as important are the small ones – the really small ones. Like other laws, copyright is subject to the principle of "di minimis" (from a longer Latin phrase that translates as "the law does not concern itself with trifles"):
https://en.wikipedia.org/wiki/De_minimis
Technically, it may be trespassing to step on someone else's yard. But if your shoe brushes up against their lawn while you're walking on the sidewalk out front of their house, it's not trespassing. Or if it is trespassing, it's a di minimis trespass, too small to matter to the law. A lot of potential copyright violations – like taking a picture of a passage in a book and posting it to social media – are so small that we don't need to apply a fair use analysis to them. They're trifles, and "the law does not concern itself with trifles."
These limitations and exceptions all apply without permission from rightsholders. They apply even if they make rightsholders furious. They are your rights, as a member of the public, as a purchaser of a work, or just as someone who whistles a song that's stuck in your head.
And that's where the esoteric early Creative Commons copyright debate comes in. Creative Commons is a way to formally codify and convey permission to use copyrighted works. Without Creative Commons, it's really hard – and expensive – to provide legally reliable permission to someone else to use something you've created.
If I want to let you adapt one of my short stories for the stage, we should both probably hire copyright lawyers at several hundred dollars per hour to draft and review a contract setting out what my permission really means. Worse: even after we've paid the lawyers, neither of us will likely really understand the fine legal technicalities of the deal. We just have to take the lawyers' word for it that the complex jargon in the contract is sufficient for our purposes. Between the complexity and the expense, there are lots of potential creative collaborations that would cost so much to paper over that they're just not worth doing, even if they'd delight everyone involved.
Creative Commons cuts through this with its standardized licenses, which spell out in plain language which permissions are being granted. Even better, these licenses are international, translated into the language and laws of dozens of countries. That means that you can take a CC licensed short story from Japan, animate it using CC licensed 3D models from Italy, set it to a CC licensed soundtrack from Indonesia and release it in Ukraine, and the whole thing just works.
Those uses – turning a story into an animation, using a 3D model, syncing a soundtrack to a video – are all pretty ambitious uses, especially if you're going to make the final result indefinitely available to the general public. It makes sense to paper over these uses, and Creative Commons makes that legal work as simple as linking to your sources and their licenses in your final product.
But there are plenty of uses that don't need licenses – even ambitious ones. Remember Wind Done Gone? There are circumstances when you can adapt someone else's story without permission, relying instead on a limitation or exception to copyright. And of course, there are plenty of trivial uses – pasting a photo into your groupchat, say – that are di minimis and also don't need permission.
These copyright flexibilities are critical. Imagine if you could only criticize someone's work if they gave you permission to do so! From the founding of CC, copyfighters raised serious concerns that CC would teach people that they can only remix other people's work if they have a license, be it a CC license or the kind that you negotiate with a lawyer.
Today – 25 years later!- CC is an unqualified success. Without CC, we wouldn't have Wikipedia! You find CC licenses on Youtube, Flickr, Bandcamp, the Internet Archive, and in many of the most important scholarly and scientific journals in the world.
But, also, 25 years later, the world is even more convinced that you should always ask permission: "better safe than sorry." I don't know if CC contributed to this culture of timidity. More likely, it was bullying copyright trolls who terrorized people into a reflex of asking permission for everything, always.
As the creator of more than 30 books, hundreds of collages, and tens of thousands of essays and blog-posts, I am often on the receiving end of these permission requests.
For example, people often ask me if they can use my CC licensed works in ways that the associated licenses clearly permit. I'm sure the people who email me for permission to do things I've already granted them permission to do think they're being polite, but I really wish they'd stop. When someone asks me if they can make a use permitted by my CC licenses, I need to carefully parse through their use to make sure they're not asking for something more.
This is time-consuming work that often involves several volleys of email just to confirm that, no, they're just asking if they can do something I've already told them they can do. This is not a good use of anyone's time! By all means, drop me a note with a link to something you've remixed from my work. That's fun! It's a lot more fun than making me play detective in order to figure out if you're exceeding the license's permissions.
There are also a lot of requests that clearly amount to fair use and/or di minimis usage. You don't need to email me to get my permission to read a brief passage from one of my books on your Youtube video! You don't need my permission to quote one of my stories in an English exam! What's more, the world would be a lot shittier if you did, so let's not act as though that's reasonable behavior, lest we shift the (already far too restrictive) norms, which might even lead to a legal change.
Finally, there's the people who email me about their desire to make uses that are more (ahem) ambitious, but that no one could possibly find out about or get angry over…except for the fact that they emailed me to ask my permission.
You want to make a tiny bootleg edition of one of my novels for your anarchist book fair? That's totally a copyright infringement, it's super-illegal, and if my publisher found out about it, I'm sure they'd send you a sphincter-puckering legal letter telling you to knock it off (and maybe even demanding that you disgorge the seven dollars, three bottlecaps and eleven cool feathers you took in trade for those pirate books).
But my publisher won't ever find out about it – unless you email me asking for permission. I absolutely cannot give you permission to do this. I have a contract with my publisher promising that I will never authorize someone other than them to publish that book. Once you tell me about your intention to do this, I'm obliged to tell my publisher, so that they can tell you no in language that would strip paint off a barn.
Buying a classroom set of books, but you also want to paste chunks of one of my books into your educational institution's classroom intranet for use as a teaching aid? There's no way my publisher would ever find out you did that, and if they did, sure, you'd also get a blood-curdling legal letter. But dude, all my books are DRM-free. You could have just pasted the text into your CMS. In what universe is my publisher going to pay one of their lawyers to review, adjudicate and paper over your request to make a use that you're not proposing to pay them for?
Let's be clear: I'm not giving you permission to pirate my work. I already spend far too much of my time chasing down dickheads who sell competing editions of my books on Amazon and Audible. I'm sick to the back teeth of wrangling Ingram's takedown process to get rid of bootleg print editions of my books.
What I'm saying is, all of your interactions with copyrighted works need not involve the author and publisher. There is a whole universe of uses that might technically violate copyright, might technically not fit into di minimis, first sale or fair use – but these are also uses that no one would ever find out.
I get it. You may feel like you can't tell the difference between the kind of uses that no one would give a shit about; the uses that might attract a bone-chilling lawyer letter; and the uses that might land you in court. I'm sorry, but I can't help you figure that one out. I'm not a lawyer. Even if I was, I'm not your lawyer.
This is one of those areas where I break with my friend, the wonderful John Hodgman. On his indispensable podcast "Judge John Hodgman," he frequently admonishes people who are uncertain if they're overstepping a bound in a commercial establishment to ask an employee for permission. For example: should you fill up a water glass with soda water from a self-serve dispenser?
https://maximumfun.org/podcasts/judge-john-hodgman/
John says you should always ask the cashier. But I've worked jobs like that, and I can tell you that there were plenty of jobs where my boss felt very strongly that taking $0.0000001 worth of water and bubbles without paying for it was theft…and where I thought my boss was a dick for thinking that. If I pretended I didn't see you getting a glass of fizzy water, the worst that would happen is my boss would tell me to keep a closer eye on the customers lest they steal his precious CO2. But if you asked me whether you could fill your glass, and my boss caught me saying yes, I'd be fired.
There's a lot of normal, perfectly fine stuff that technically violates copyright that I can't give you permission to do, because I've signed a contract with my publisher. If you ask me, I'll have to ask my editor, who will say no, even though he thinks it's fine, too. If I push it, he'll have to ask the lawyers, who will almost certainly also say no, even if they think it's fine, because it doesn't make sense to spend hours papering over a legal agreement with someone who wants to sell seven copies of a book at an anarchist book-fair or upload a couple chapters of a book to a school's intranet.
Are there instances in which you might misjudge which category your use falls under and end up in court? I guess so. But if that's your concern, asking my permission does no good, because I'm just gonna tell you no.
Life is hard.
Read books.
Hey look at this (permalink)
- AOC Must Run For President https://www.hamiltonnolan.com/p/aoc-must-run-for-president
-
Role confusion: one more reason we can’t trust LLMs https://designingsecuresoftware.com/writings/role-confusion/
-
Ida Tarbell: The Journalist Who Took Down Rockefeller https://prospect.org/2026/07/31/ida-tarbell-journalist-who-took-down-rockefeller/
-
Medusa Joins the Club https://longforgottenhauntedmansion.blogspot.com/2026/07/medusa-joins-club.html
-
Hot Centrist Summer Was a Bust https://prospect.org/2026/07/31/democrats-donor-base-establishment-progressive-hot-centrist-summer-was-a-bust/
Object permanence (permalink)
#25yrsago RIP, Poul Anderson https://www.locusmag.com/1997/Issues/04/Anderson.html
#25yrsago Talking P2P at PC Forum https://web.archive.org/web/20010820163912/https://www.edventure.com/pcforum/transcript.cfm?Counter=13
#25yrsago CD DRM cracked in 2 weeks https://web.archive.org/web/20010803144120/http://www.oreillynet.com/cs/weblog/view/wlg/533
#20yrsago Waitress cards drinker, is handed her own stolen ID https://web.archive.org/web/20060901042515/http://www.thedenverchannel.com/news/9606436/detail.html
#20yrsago How POWs in a Nazi camp got a Disney insignia https://web.archive.org/web/20061209200825/https://blog.modernmechanix.com/2006/08/01/wwii-pows-get-a-disney-designed-logo/
#20yrsago Fixies illegal in Portland https://bikeportland.org/2006/07/28/judge-finds-fault-with-fixies-1727
#15yrsago Freedom of Information requests show that UK copyright consultation was a stitch-up; Internet disconnection rules are a foregone conclusion https://torrentfreak.com/digital-economy-act-a-foregone-conclusion-110731/
#15yrsago What Murdoch’s media empire did: the big picture https://web.archive.org/web/20110805111419/http://blogs.alternet.org/speakeasy/2011/07/27/what-rupert-murdoch-means-for-you-personally/
#15yrsago Flowchart shows the complexity of NZ Internet Disconnection copyright law https://web.archive.org/web/20111105044005/https://lawgeeknz.posterous.com/copyright-infringing-file-sharing-amendment-a
#15yrsago Married lesbian couple rescued 40 teenagers from drowning during Utøya shooting https://www.lgbtqnation.com/2011/07/married-lesbian-couple-saves-dozens-during-norway-shooting-rampage/
#15yrsago Stephen Fry debating Ann Widdecombe on the worth of the Catholic Church https://www.youtube.com/watch?v=9fN3zDtfivc
#10yrsago Jacksonville police pension fund blows $1.8M worth of tax-dollars fighting open records requests https://web.archive.org/web/20160804040211/http://jacksonville.com/news/metro/2016-07-30/story/open-government-lawsuits-against-city-pension-fund-cost-taxpayers-more-2
#10yrsago A profile of Moxie Marlinspike: the seagoing anarchist cryptographer who brought private messaging to millions https://www.wired.com/2016/07/meet-moxie-marlinspike-anarchist-bringing-encryption-us/
#10yrsago Burying the past in glass coffins: Victoria & Albert museum bans sketching in temporary exhibitions https://www.theguardian.com/artanddesign/2016/apr/22/va-museum-no-sketching-signs-draconian?CMP=share_btn_tw
#10yrsago Hugo Gernsback’s introduction to the first issue of Amazing Stories, 1926 https://brucesterling.tumblr.com/post/148297242233/a-new-magazine-announced-by-hugo-gernsback
#10yrsago Afterbrexit: Scotland trolls Theresa May by passing laws she has ridiculed https://www.nakedcapitalism.com/2016/08/scotland-disses-theresa-may-by-reviving-anti-inequality-law-she-loathes.html
#5yrsago Managing aggregate demand https://pluralistic.net/2021/08/01/managing-aggregate-demand-part-iv/
#1yrago Mattie Lubchansky's 'Simplicity' https://pluralistic.net/2025/08/01/ecosexuality/#nyc-ast
Upcoming appearances (permalink)
- Virtual: EFFecting Change: Who the Machine Serves, Aug 12
https://www.eff.org/event/effecting-change-who-machine-serves -
Edinburgh International Book Festival with Jimmy Wales, Aug 17
https://www.edbookfest.co.uk/events/the-front-list-cory-doctorow-and-jimmy-wales -
Sydney: The Festival of Dangerous Ideas, Aug 23-24
https://festivalofdangerousideas.com/program/ -
Melbourne: Enshittification at the Wheeler Centre, Aug 25
https://www.wheelercentre.com/events-tickets/season-2026/cory-doctorow-enshittification -
Brighton: The Reverse Centaur's Guide to Life After AI with Carole Cadwalladr (Brighton Dome), Sep 8
https://brightondome.org/whats-on/LSC-cory-doctorow-the-reverse-centaurs-guide-to-life-after-ai/ -
London: The Reverse Centaur's Guide to Life After AI with Riley Quinn (Foyle's Picadilly), Sep 9
https://www.foyles.co.uk/events/enshittification-cory-doctorow-riley-quinn -
South Bend: An Evening With Cory Doctorow (Notre Dame), Oct 6
https://franco.nd.edu/events/2026/10/06/an-evening-with-cory-doctorow/
Recent appearances (permalink)
- Why AI Won't Replace Workers, But Will Crash The Economy (Smart
Cookies)
https://www.youtube.com/watch?v=rRRmUuxJolY -
AI and the Enshittification Era (The Weekly Show with Jon Stewart)
https://www.youtube.com/watch?v=-dAIJRjb-Bw -
AI is not inevitable (Betakit)
https://www.youtube.com/watch?v=DbiTVkq1WHo -
A Conversation with Lina Khan (Law and Economy Student Network)
https://www.youtube.com/live/7Ak5LZllqwE -
Will AI ever come alive, and what happens if it does? (BBC News)
https://www.youtube.com/watch?v=Lzk4o3fPZZE
Latest books (permalink)
- "The Reverse-Centaur's Guide to AI," a short book about being a
better AI critic, Farrar, Straus and Giroux, June 2026
https://us.macmillan.com/books/9780374621568/thereversecentaursguidetolifeafterai/ -
"Canny Valley": A limited edition collection of the collages I create for Pluralistic, self-published, September 2025 https://pluralistic.net/2025/09/04/illustrious/#chairman-bruce
-
"Enshittification: Why Everything Suddenly Got Worse and What to Do About It," Farrar, Straus, Giroux, October 7 2025
https://us.macmillan.com/books/9780374619329/enshittification/ -
"Picks and Shovels": a sequel to "Red Team Blues," about the heroic era of the PC, Tor Books (US), Head of Zeus (UK), February 2025 (https://us.macmillan.com/books/9781250865908/picksandshovels).
-
"The Bezzle": a sequel to "Red Team Blues," about prison-tech and other grifts, Tor Books (US), Head of Zeus (UK), February 2024 (thebezzle.org).
-
"The Lost Cause:" a solarpunk novel of hope in the climate emergency, Tor Books (US), Head of Zeus (UK), November 2023 (http://lost-cause.org).
-
"The Internet Con": A nonfiction book about interoperability and Big Tech (Verso) September 2023 (http://seizethemeansofcomputation.org). Signed copies at Book Soup (https://www.booksoup.com/book/9781804291245).
-
"Red Team Blues": "A grabby, compulsive thriller that will leave you knowing more about how the world works than you did before." Tor Books http://redteamblues.com.
-
"Chokepoint Capitalism: How to Beat Big Tech, Tame Big Content, and Get Artists Paid, with Rebecca Giblin", on how to unrig the markets for creative labor, Beacon Press/Scribe 2022 https://chokepointcapitalism.com
Upcoming books (permalink)
- "The Post-American Internet," a geopolitical sequel of sorts to Enshittification, Farrar, Straus and Giroux, 2027
-
"Unauthorized Bread": a middle-grades graphic novel adapted from my novella about refugees, toasters and DRM, FirstSecond, April 20, 2027
-
"Enshittification, Why Everything Suddenly Got Worse and What to Do About It" (the graphic novel), Firstsecond, 2027
-
"The Memex Method," Farrar, Straus, Giroux, 2027
Colophon (permalink)
Today's top sources:
Currently writing: "The Post-American Internet," a sequel to "Enshittification," about the better world the rest of us get to have now that Trump has torched America. Fourth draft completed. Submitted to editor.
- A Little Brother short story about DIY insulin PLANNING
This work – excluding any serialized fiction – is licensed under a Creative Commons Attribution 4.0 license. That means you can use it any way you like, including commercially, provided that you attribute it to me, Cory Doctorow, and include a link to pluralistic.net.
https://creativecommons.org/licenses/by/4.0/
Quotations and images are not included in this license; they are included either under a limitation or exception to copyright, or on the basis of a separate license. Please exercise caution.
How to get Pluralistic:
Blog (no ads, tracking, or data-collection):
Newsletter (no ads, tracking, or data-collection):
https://pluralistic.net/plura-list
Mastodon (no ads, tracking, or data-collection):
Bluesky (no ads, possible tracking and data-collection):
https://bsky.app/profile/doctorow.pluralistic.net
Medium (no ads, paywalled):
Tumblr (mass-scale, unrestricted, third-party surveillance and advertising):
https://mostlysignssomeportents.tumblr.com/tagged/pluralistic
"When life gives you SARS, you make sarsaparilla" -Joey "Accordion Guy" DeVilla
READ CAREFULLY: By reading this, you agree, on behalf of your employer, to release me from all obligations and waivers arising from any and all NON-NEGOTIATED agreements, licenses, terms-of-service, shrinkwrap, clickwrap, browsewrap, confidentiality, non-disclosure, non-compete and acceptable use policies ("BOGUS AGREEMENTS") that I have entered into with your employer, its partners, licensors, agents and assigns, in perpetuity, without prejudice to my ongoing rights and privileges. You further represent that you have the authority to release me from any BOGUS AGREEMENTS on behalf of your employer.
ISSN: 3066-764X
12:28
Russell Coker: Links July 2026 [Planet Debian]
- [1] https://tinyurl.com/26cnn3og
- [2] https://tinyurl.com/22fewyml
- [3] https://tinyurl.com/2a5t693d
- [4] https://glasswings.com.au/blog/2026-07/05-185304.html
- [5] https://tinyurl.com/26qzcadm
- [6] https://tinyurl.com/2csg4huw
- [7] https://tinyurl.com/2blnzzxg
- [8] https://tinyurl.com/25v5j7v9
- [9] https://archive.md/Gq2jB
- [10] https://www.youtube.com/watch?v=3ddTIa-AhXE
- [11] https://tinyurl.com/2xt9dgfp
- [12] https://tinyurl.com/2y5f26rj
- [13] https://tinyurl.com/29ok2qsu
- [14] https://tinyurl.com/2yxzsp7s
12:14
Facial Recognition at Madison Square Garden [Schneier on Security]
Last month, the story broke (alternate link) that Madison Square Garden uses facial recognition software on everyone entering the facility, and—among other groups—flags activists that oppose using facial recognition.
Turns out that the system was shut off for Taylor Swift’s wedding.
Evan Greer—one of the people that MSG alerts on—comments:
Ironically, Swift herself has reportedly used facial recognition at her own concerts to identify stalkers. This “privacy for me, surveillance for thee” attitude feels like a perfect encapsulation of the future we’re already living in: one where wealthy elites can afford privacy, while the rest of us are forced to live in a corporate surveillance panopticon.
Whatever privacy measures Swift had in place for the wedding seems to have worked. No photos have leaked online.
11:42
Otto Kekäläinen: Estonia, the country of the fit and the wit [Planet Debian]


While many Western democracies seem to be in a state of decay and are no longer the safe, civilized and prosperous countries they once were, there are still some European countries that are governed well. One of those that stand out is Estonia.
Estonia is probably most well known for multiple software companies that originated from there, such as Wise, Bolt, Pipedrive and Skype. The government itself is also famous for being early in issuing government IDs with an embedded smart chip for online authentication already in the 1990s. Via the national portal at eesti.ee all residents can access extensive eServices ranging from viewing their health benefits to filing taxes.
Estonia has also been running an e-Residency program since 2014, where they issue digital ID cards to foreigners, making it easy for them to remotely log into the government portals and for example, establish businesses, file annual reports and so forth. Note that the e-Residency is not a path to physical residency. Estonia does, however, have a separate Digital Nomad visa program that makes it easy for non-EU citizens to also physically establish themselves in Estonia, assuming, of course, you meet the criteria, which includes, among others, a minimum monthly income of 3960 € from outside Estonia. EU citizens naturally have free mobility inside the EU and can simply get an apartment and register as a resident in Estonia if they so choose. And there are plenty of reasons to do so.
Estonians value health, education and entrepreneurship
I moved to Estonia about one and a half years ago. In my observations Estonia strikes me as a country that values health, education (in particular programming and natural sciences) and entrepreneurship highly.
I don’t know how Estonians achieve it, but they look pretty fit and rarely obese. Estonia has rye bread and sauna in their culture just like Finland, and in addition the flat terrain and well-planned bike routes and extensive network of parks (and pull-up bars everywhere) seem to create an environment where it is easy to live in a healthier way. The consumption of processed foods and candy also seems relatively low among Estonians.
The gym chain MyFitness also seems to be present everywhere. Even the Tallinn airport has a calisthenics workout station right at the departure gates, which anyone is free to use while waiting for their flight to take off. One of the top longevity influencers in Europe, Siim Land, is Estonian.


Estonians also seem to value the school system highly. The government has been actively raising teacher pay and has a stated goal of reaching 120% of the national average by 2027. The students are also expected to value the education and respect their teachers. According to the TALIS 2024 survey (OECD’s international teacher survey), Estonian teachers spend significantly more time on actual teaching and learning and waste less time on interruptions or keeping classroom order compared to the OECD average. This is among the highest rates internationally, meaning they spend relatively little time on maintaining order or dealing with disruptions. While the international education benchmark PISA scores have been dropping globally, Estonia has consistently been climbing the ranks in past decades. In the latest PISA study (from 2022), Estonia ranked number one in Europe for reading, mathematics and science. In the overall results, Estonia ranked seventh globally, only behind countries such as Japan, Korea and Singapore.
Valuing entrepreneurship is evident in how the taxation system is set up in Estonia. Famously, in Estonia, companies can defer taxes on annual earnings and reinvest all of their profit in growing the company. Taxes are due only later, when paid out from the company, for example as dividends. For individuals, receiving dividends from any Estonian or foreign company is tax-free as long as the company paying dividends already paid corporate tax on the same income.
The tax system is also very simple. For all individuals, all types of income, including salary and capital gains, are always taxed at a flat rate of 22%. This removes the incentive for anyone to try to convert income into different types, setting up holding company structures and other optimizations as there is no gain. All entrepreneurs can simply focus on growing their business and forget extra bureaucracy. There is also no marginal tax rate cliff to stop working at – everyone is encouraged to always try to produce as much value as they can. A simple tax system is also reflected in the fact that anyone can easily read all tax rules that apply to individuals in plain English on the Estonian tax authority website, and one does not need to hire any accountants simply to file taxes.
Estonia also has a very straightforward investment account system: any person can freely open a self-directed investment account at any brokerage at no extra cost and report it as such to the tax authority, and then use it to save for an apartment, retirement, or other purposes, and defer all income taxes until withdrawal. There are no caps or time limits, and all residents are encouraged to save and invest as much as they can and thus take responsibility for their own wealth accumulation.
It seems that culturally Estonians respect people who are active and progress in their careers and businesses more than in other countries. Unlike in Finland, successful people are admired and living on government welfare is not romanticized. At the same time, the government benefits are less generous so people can’t live comfortably on them and, for example, many of the asylum seekers Estonia accepted have since left on their own initiative to other European countries in search of better benefits.
Low crime, high trust
Another thing that strikes me when walking the streets of Tallinn is that there are no drug addicts, beggars, thugs or the like. The difference compared to, for example, Vancouver (where I lived previously) is stark. In public buildings, people leave their coats and bags hanging in the lobby while visiting. Private houses and apartment block yards are not fenced. In my building, I noticed people even leave their bikes unlocked in the bike shed. I have also seen the staff of a coffee stall in a shopping mall going for a break and leaving everything unattended, not worrying that anyone would take anything while the staff is away.

This is not just my personal experience. According to the Numbeo crime index, Estonia has one of the lowest crime rates in the world. Also, comparing drug and property crime stats, for example, Finland has twice as much crime per capita, and places like Vancouver in Canada almost five times more.
I don’t have any clear explanation for why crime is so much lower in Estonia, but some suggest that higher social cohesion and lower levels of welfare contribute to people standing to lose more if they behave antisocially. Compared to Finland, Estonia also more readily jails repeat offenders, and those who are put on trial will experience a swifter court process thanks to simplified legal processes and more efficient governance.
Moving to Estonia: quick checklist
Moving to Estonia is very easy for any EU citizen, in particular if your work is not location-dependent (e.g., remote work or an online business) and you are simply looking for the cleanest and safest environment to live in.
First, check into a hotel in Tallinn, check out various neighborhoods to figure out what area you like (my favorites are Kalaranna, Kalamaja, Noblessner and Volta) and start browsing available apartments in English at kv.ee. Most professionals speak fluent English, so there should not be any difficulty in reaching out to people by email or phone.


The next step is to buy a local prepaid SIM card at e.g., an R-Kiosk or a convenience store as signing up for other matters later on will require an Estonian phone number. Once you have an apartment and e.g., signed a rental agreement, you can register in the population registry online.
After that, you have proof you are a local resident with an address and telephone number in Estonia. With local resident status, you can go to the police station to get a local ID card. Don’t bother scheduling an appointment, just go to the Tammesaare police station in Tallinn, take a queue number and wait. Once it is your turn, they will guide you on how to use the photo booth, fingerprint registration device, and file your application. A few days later you will receive an email confirming whether your application was accepted, and after a few more days, you will get another email notifying you that your ID card has been printed and is available for pick-up at the same location. This will also be your first practical experience of how fast and efficient the government in Estonia is.
Once you have the local ID card, you can use the smart card feature to log into all the government eServices and sort out the rest of the relocation process, such as registering tax residency and getting a family doctor.
How did Estonia evolve to be like this?
After Estonia regained its independence after the fall of the Soviet Union in 1991, the first elected government in 1992 was led by a very progressive 31-year-old Prime Minister Mart Laar, who managed to set up some very good policies and laid the foundation of a society that has evolved well in the decades since. Estonia was very lucky to have people in power in the 1990s who didn’t simply copy what other Western countries were doing, but who tried to think about things from first principles and create Estonia’s own model for efficient and fair governance. As a post-Soviet country, the population had also been vaccinated against overly socialist and unrealistic ideals, and everyone had a healthy distrust of the government’s ability to solve problems and emphasis was placed on people’s liberty to work for themselves as they best see fit. The improvement in living standards over the past 35+ years has also been witnessed by the population, and voting behavior supports keeping the country on the same trajectory.
General living standards still continue to improve as the nominal wage growth sits at around 6%, clearly above the annual inflation rate of about 3%. In 2026, the Estonian economy is expected to grow about 2.4%, which is faster than the EU average. The growth in Estonia is not the result of any accounting tricks - Estonia is part of the euro and can’t print its own currency, nor has it been funding the public sector with excessive debt. With a 24% debt-to-GDP ratio, Estonia consistently ranks as one of the most responsibly managed countries among advanced Western economies.
As wages in Estonia soon catch up with the EU average, and higher defence spending has forced the government to raise taxes in recent years, the economic growth that Estonia has enjoyed for 35+ years since it exited the Soviet Union might slow down a bit in future years. The policies that fueled this growth in living standards, however, are likely to stay.
The tiger leap
There is one specific government policy in Estonia’s history that I think should be highlighted in particular. Estonia was very progressive by announcing the Tiigrihüpe (Tiger Leap) program in 1996 with the goal of equipping all schools with computers and teaching all students the basics of programming. This surely had a large influence on why Estonia has so many successful software companies, why the government eServices are so mature that even neighboring countries like Finland are striving to copy the Estonian government’s IT architecture called X-road.
The Tiigrihüpe project was originally suggested in the mid-1990s by Toomas Hendrik Ilves, then ambassador of Estonia to the United States, Canada and Mexico, and later President of Estonia in 2006–2016. While he was a psychologist by education, he was also a self-taught amateur programmer and used his political influence to promote sensible adoption of information technology in both Estonia and the EU.
The history of Estonia has several prominent figures who were not lawyers by profession but engineers, scientists and historians who were very practical in their political decisions, which I think is now reflected in how government processes were formed.
The video below shows how the Estonian government advertises itself and what values they choose to highlight:
Should other countries adopt policies from Estonia?
Of course, not everything is perfect in Estonia either. The fertility rate of 1.16 in Estonia is very low. This trend is present globally, but in Estonia it is way below the EU average. Also, the service culture is something that needs to improve in Estonia. While services are in general fast and efficient, the attitude of people working in cafes and stores does not reflect a willingness to fill in gaps if the standard process falls short, nor are visitors actively made to feel welcome as individual humans, but are treated as mere process inputs.
However, many of the things listed earlier I think should be studied by policymakers elsewhere. Societies are complex systems and there is of course no guarantee that copying a single policy to another country with different ethnicities, history and ingrained culture would lead to the same policy outcomes. But considering that Estonia is a small country without favorable geography and no natural resources, and that it started out from a place of total chaos, low economic activity and high crime in 1992 to rise to what it is now in 2026, the success it has seen is surely largely a result of good policies, governance and culture that other countries can and should mimic.
10:21
“That doesn’t work” [Seth's Blog]
We transferred an idea from engineering to culture, but it’s incomplete.
If you build a watch that doesn’t tell time, it’s fair to say it doesn’t work.
But when a critic says, “that joke didn’t work,” after seeing a comic perform to a raucous audience, what they probably mean is, “that didn’t work for me.”
The problem might not be the comic. It might be the critic.
“It’s not for you,” is a useful, almost essential way to navigate the creation of our cultural work. If you say it too often to the people you were seeking to serve, your work needs improvement. But when you say it to a critic you never intended to please, you’re opening the door to serving the people you do care about.
08:28
Jimothy Chalamet [Penny Arcade]
New Comic: Jimothy Chalamet
06:14
Making an agile version of a Windows Runtime delegate in C++/WinRT, part 9 [The Old New Thing]
Over half of the time we spent trying to make an agile version of a Windows Runtime delegate in C++/WinRT was dealing with the case of a delegate that declares non-marshalability. But how much does it matter?
I looked at the three major C++ implementations of the Windows Runtime: C++/WinRT, C++/CX, and WRL.
The C++/WinRT implementation
has an optimization for IAgileObject, but
for objects that aren’t agile,
it just goes directly to agile_ref without
checking for INoMarshal. This means that a delegate
that declares non-marshability will always be rejected by C++/WinRT
when used as an event handler.
The C++/CX implementation
lazy-creates the agile reference to the original delegate when the
wrapper is used from a different apartment. If the original
delegate is non-marshalable, it means that the
CO_E_NOTSUPPORTED is produced only when the
wrapper is used in a way that requires a marshalable delegate.
The WRL implementation does not have an optimization for
IAgileObject, although
it mentions it as a possible optimization. It always creates
the agile reference eagerly, which means that if the original
delegate is non-marshalable, it cannot be added to an agile event
source.
Okay, so let’s summarize in a table.
| Event source | C++/WinRT | C++/CX | WRL | Our version | |
|---|---|---|---|---|---|
| single-threaded | multi-threaded | ||||
| Optimize agile delegates | Yes | Yes | N/A | No | Yes |
| Avoid wrapping agile delegates | Yes | No | Never wraps | No | Yes |
| Agile reference creation | Eager | Lazy | Never | Eager | Eager |
| Non-marshalable delegates | Rejected | Allowed if used non-agile-ly |
Allowed (always used non-agile-ly) |
Rejected | Allowed if used non-agile-ly |
Now, maybe you think we are working too hard. (Maybe we are.) In which case you can remove support for whatever cases you feel you don’t need.
The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 9 appeared first on The Old New Thing.
05:49
Breaking Up, p08 [Ctrl+Alt+Del Comic]
The post Breaking Up, p08 appeared first on Ctrl+Alt+Del Comic.
Girl Genius for Friday, July 31, 2026 [Girl Genius]
The Girl Genius comic for Friday, July 31, 2026 has been posted.
04:42
Russ Allbery: Review: Painting the Blues in Gretna Green [Planet Debian]
Review: Painting the Blues in Gretna Green, by Linzi Day
| Series: | Midlife Recorder #2 |
| Publisher: | Linzi Day |
| Copyright: | November 2022 |
| ISBN: | 9798360228431 |
| Format: | Kindle |
| Pages: | 577 |
Painting the Blues in Gretna Green is a self-published fantasy novel and the second in the Midlife Recorder series. It picks up immediately after the end of Midlife in Gretna Green. I also read it almost immediately after, so I didn't pay attention to how good the recap of previous events was.
As before, this is urban fantasy except not urban. Day calls it paranormal women's fantasy, which I suppose is as good of a genre label as any. The other book I can think of off-hand that would go into that genre would be Nancy Springer's Larque on the Wing, although it is considerably more literary.
I suspect I'm going to read this whole series and it's going to be impossible to review these books without talking about Niki's job, so I'm not going to treat that as a spoiler. It's fairly well-advertised in the marketing for the book, so that feels justified. If you're particularly averse to any spoilers, though, you may want to stop reading here until you've gotten to the reveal in the first book.
Niki is now officially the Recorder, with the power, advice book, and sentient house to go with it. She's about to face her first test in managing interworld politics: There's something amiss in the world of the Picts. Her allies are dropping hints, there's a petition from a group on the Pict world that she can't make sense of, and although she likes the queen of the Picts, there is a great deal of tension beneath the surface that she doesn't understand. Meanwhile, after the incompetent disaster that she uncovered in the first book, Niki is determined to pick her new staff by her own criteria.
The second book leans even harder into giving Niki both a tangled mess created by previous incompetence and enough power to fix it. Watching that happen is very satisfying, particularly when it involves surprising people who are rather too used to getting their own way.
I was somewhat less convinced that Niki is getting the right training to make the decisions that she's making. Diplomacy and staff management are real skills that one needs to learn, not just wing on vibes and gut instinct. My love of competence porn occasionally wishes that Niki had a bit more structure around her competence. We do at least get a new fictional self-help book on how to rule that contributes the quotes that open each chapter. Not the ethics and management training that I would have chosen, but it's something!
In defense of Niki's technique, it becomes clear in this book that the last few recorders have been far too cautious, conservative, and content with a status quo that involved a minimum of work. One of the delights of this book is that Niki thinks power exists to be used to fix things and is determined to use it, not just sit on it. I had more suspension of disbelief issues with this book than with the first — some of the problems Niki is solving seem far too obvious to have been in stasis for this long while also having this easy of a solution, and the level of political power given to the Recorder is a bit unbelievable — but it is so satisfying to see Niki cajole and bully people into being sensible.
I have no idea if this is intentional on Day's part, but I will not be at all surprised if adult-diagnosed ADHD comes up at some point in this series. The way that Niki's focus jumps, her tendency to veer between focusing on a problem and forgetting about it, and something about the way she switches between trains of thought or misses important context because she's jumping to conclusions is making me wonder. This, to be clear, is not a complaint; I think it makes Niki more relatable and more interesting. It's a good thing that she has a sentient house to serve as her assistant. The glee with which she's delegating any task that involves keeping track of details or following up with other people feels like a bit of an indicator by itself.
I did get a bit frustrated with the plot structure of this book. Niki keeps mentioning that a critical petition submitted to her office makes no sense, but it takes half of this (rather long) book before she finally explains to anyone else, even the reader, what's deficient about it. The excuse within the book is that she's having a rather busy day, but by the third time Niki mentions and then fails to do anything about the petition, I was wishing Day would stop bringing it up until she was ready for that part of the plot.
This, as with a few issues in the previous book, feels partly like an editing problem. There is something joyful in indulgent, sprawling books, but only up to the point where they become repetitive. Painting the Blues was right at that line, and once again I wish someone had helped Day trim about fifty pages out of it.
All that said, and despite having more quibbles with this book than the previous one, this continues to be great fun. It's satisfying wish-fulfillment about fixing long-standing problems and having the power to not have to put up with abusive nonsense and ridiculous bullshit, and I am so here for that. I hope Niki realizes she's eventually going to need more refined skills than a heart-to-heart over wine, but she's learning on the job and I'm happily along for the ride. She's also capable of recognizing skill in other people, and that goes a long way.
Recommended if you liked the first one and are in the mood for another fantasy of "no, we're not going to leave it that way, we're going to fix that right now."
Followed by Ties that Bond in Gretna Green.
Rating: 7 out of 10
02:21
Jonathan McDowell: My CPU died [Planet Debian]

I built my current house server back in 2019. It had an upgrade from the original Ryzen 2700 to a 5700G in late 2021, but otherwise is still running with the original setup. Back in November it developed some erratic behaviour (initially manifesting as problems with the TPM, which is ironic as I’ve spent a bunch of time at my day job trying to improve TPM reliability), culminating in unreliable reboots. I had a limited amount of ability to swap parts out, but ultimately decided it was a motherboard issue (thinking perhaps VRM problems), found a replacement locally, and everything seemed fine.
Until May.
At that point I rebooted the machine for a Debian point release, and it failed to come back. Fans would spin, but there was no sign of actual life. I ended up pressing a temporary machine into service (that could at least run the Home Assistant container, and a few other critical bits) while I tried to work out what was wrong. I’d kept the previous motherboard, and still had the Ryzen 2700, so I did a bunch of swaps (and obtained a motherboard buzzer to try and get some indication about whether there were useful beep codes being emitted), and ultimately came to the conclusion that the CPU had died.
I’m not quite clear what happened here. I played it safe and replaced the PSU at the same time, in case that was the original cause back in November and ultimately damaged the CPU, but both old + new motherboards worked just fine with the 2700.
That left a decision about what to do. This previous server was from 2013, so this machine has now lasted longer than that and I could justifiably upgrade. However when I went to look at what the equivalent modern machine would be it’s only a couple of generations later (Zen 5 vs Zen 3), and 64GB RAM alone would have set me back ~ £1k. For not a lot of gain. So I ended up buying a replacement Ryzen 5700G, hopefully allowing me to put off thinking about an upgrade until Zen 6 is out, and RAM prices are saner (though I understand that might take a couple of years).
It’s not the first time I’ve had a faulty PSU be the cause of a dead machine, but it was a pretty frustrating experience.

00:49
Microsoft claims it’s going to improve Windows 11’s context menus [OSnews]
When I had to use Windows 11 for a month because you people paid me to do so, the one seemingly small thing that really ground my gears were Windows 11’s terrible right-click (context) menus. They were full of stuff I didn’t put there, slow to open, and in some places, a modern Windows 11 context menu would have its own old Win32 context menu with even more stuff. It seems Microsoft is finally going to fix all of this.
This new compact menu will be much faster and more reliable, as it foregoes needing to load in all the third-party actions that slow it down currently. Additionally, at the Windows Insider Meetup in London, Microsoft showed me a new context menu customization feature coming soon that will let users configure what apps and actions appear in the right-click menu.
↫ Zac Bowden at Windows Central
Look, I know to us non-Windows users this seem like an incredibly small and dumb thing to focus on, but when your operating system is as much of a trashfire as Windows has become, improved context menus are massive improvements that make a meaningful difference. Of course, Microsoft makes these types of promises all the time, so I’ll believe it when I see it.
00:21
Urgent: Impeach Secretary of Defense Hegseth [Richard Stallman's Political Notes]
US citizens: call on Congress to impeach Secretary of Defense Hegseth.
US citizens: Join with this campaign to address this issue.
To phone your congresscritter about this, the main switchboard is +1-202-224-3121.
Please spread the word.
Urgent: Call on ABC and NBC to stand strong [Richard Stallman's Political Notes]
US citizens: call on ABC & NBC to stand strong against the fascist's bullying.
See the instructions for how to sign this letter campaign without running any nonfree JavaScript code--not trivial, but not hard.
Urgent: Protect Medicaid, submit public comment [Richard Stallman's Political Notes]
US citizens: Protect Medicaid by submitting a public comment by July 31.
See the instructions for how to sign this letter campaign without running any nonfree JavaScript code--not trivial, but not hard.
Urgent: Keep corrupter's name off our money [Richard Stallman's Political Notes]
US citizens: call on your senators to keep the corrupter's name off our coins and paper money.
See the instructions for how to sign this letter campaign without running any nonfree JavaScript code--not trivial, but not hard.
US citizens: Join with this campaign to address this issue.
To phone your congresscritter about this, the main switchboard is +1-202-224-3121.
Please spread the word.
Urgent: End Big Oil's taxpayer-funded war profiteering [Richard Stallman's Political Notes]
US citizens: call on the House of Representatives to end Big Oil's taxpayer-funded war profiteering.
See the instructions for how to sign this letter campaign without running any nonfree JavaScript code--not trivial, but not hard.
US citizens: Join with this campaign to address this issue.
To phone your congresscritter about this, the main switchboard is +1-202-224-3121.
Please spread the word.
00:00
Chrome gets “live patching” [OSnews]
We may all have a disdain for Chrome – OSNews users probably use Chrome a lot less than the average public – but that doesn’t mean the browser doesn’t sometimes do interesting things other browsers should copy. Chrome is in the the process of increasing its release cadence, but getting users to restart their browser more often than they already do to apply these higher number of updates is going to be a problem. As such, Google is working on something that seems quite obvious now that they’ve talking about it:
Investing in “dynamic patching” that will eliminate the need for a full browser restart in most cases. By leveraging Chrome’s multi-process architecture, dynamic patching sequentially replaces background child processes (like the Renderer and GPU) with updated binaries on the fly. Stay tuned to learn more as we research and develop this feature.
↫ Chrome Security Team
Chrome was the first browser to use multiple processes, isolating tabs from one another so that if one website or tab went haywire, your other tabs would be unaffected. It makes perfect sense to have the browser use new, updated binaries for new tabs you open as soon as they become available, in a sort of ship-of-Theseus kind of approach to updating. Of course, you can’t postpone the inevitable forever, but this should provide real-world benefits to users. Neat.
The linked blog post goes into much more detail about other things too, like various low-level mitigations to prevent bugs and security issues from causing too much harm.
Thursday, 30 July
21:42
My 2026 LAcon/Worldcon Schedule [Whatever]

Yeah, they got me doing a lot of things this year, plus I’ll be at the Hugos because, you know, up for Best Series and all (hey, remember to vote for the Hugos, okay? You got about another week to do that. Don’t worry, I’ll remind you again soon). But the most important thing: I’m DJing a dance! Come dance with us on Friday, y’all. It’s gonna be a great time.
The image above is static but the whole public Worldcon schedule is here, and there it has drop-down information letting you know who is on what panel and what the panel is about and all that good stuff. If you want to find my stuff specifically, just put “Scalzi” into the search field (naturally, this works with other program participants as well). There is… a lot on the schedule this year so I assure you that if you are attending Worldcon you will never not have something to see or do. So come on down!
— JS
20:07
Reproducible Builds (diffoscope): diffoscope 326 released [Planet Debian]
The diffoscope maintainers are pleased to announce the release
of diffoscope version 326. This version
includes the following changes:
[ Vagrant Cascadian ]
* Add external tool reference for "pedump" to use the "mono" package on
GNU guix.
You find out more by visiting the project homepage.
18:14
(Satire) Unemployed man considers become AI [Richard Stallman's Political Notes]
I'd rather be an AI than an LLM.
Juries want only fairness in court [Richard Stallman's Political Notes]
Juries want fairness in court and don't just obey the government. That's why ministers are attacking them.
17:28
American Being Prosecuted for Wiping His Phone Before Handing It Over to Border Officials [Schneier on Security]
He’s being prosecuted for giving border officials a code that wiped his phone:
The case centers on a feature included in GrapheneOS, a custom Android operating system that runs in place of the software on most modern Google Pixel devices. Tunick’s attorneys confirmed GrapheneOS was running on his phone.
The software feature allows the device owner to set a passcode that deliberately wipes the contents of that device if entered instead of the user’s unlock passcode.
Tunick’s case also raises ongoing questions about what constitutional rights can be invoked at the border, which the U.S. government has long asserted is not U.S. soil until a person is authorized to enter.
Right. And he wasn’t under arrest, either.
Graphine says that the feature is “completely legal“:
GrapheneOS is completely legal. We have no obligation to weaken any of the security protections it provides. Creating and using GrapheneOS is strongly protected by the US constitution. Laws attempting to make it illegal or require weakening the security would be unconstitutional.
It’s hard to know how much the Constitution matters in the US right now.
15:21
[$] Reconsidering O_CREAT|O_DIRECTORY [LWN.net]
Linux provides a system call (mkdir()) to create a directory, and a few variants of open() that can open a directory. There is, however, no system call in Linux that can create and open a directory in a single, race-free call. Jori Koolstra has been working on remedying that situation, most recently by repurposing a set of open() flags that currently return an error. There are, however, concerns that show just how hard it can be to create user-space interfaces that do not present traps for application developers.
Another batch of single-fix stable kernels [LWN.net]
Greg Kroah-Hartman has announced the release of the 6.18.41, 6.12.100, 6.6.147, 6.1.180, 5.15.213, and 5.10.262 stable kernels.
Each of these kernels contains a single fix for a use-after-free vulnerability (CVE-2026-64560). Users of these kernels are advised to upgrade.
14:35
Security updates for Thursday [LWN.net]
Security updates have been issued by AlmaLinux (gstreamer1-plugins-bad-free, libtiff, libXfont2, nodejs:22, nodejs:24, and rest), Debian (expat and nss), Fedora (libssh, nginx, nginx-mod-brotli, nginx-mod-fancyindex, nginx-mod-headers-more, nginx-mod-modsecurity, nginx-mod-naxsi, nginx-mod-vts, nodejs24, perl-HTTP-Date, proftpd, squid, unbound, and wordpress), Oracle (c-ares, edk2, freerdp, go-fdo-server, libreswan, mariadb-connector-c, and nginx), SUSE (alloy, apache-commons-lang3, google-guice, maven, maven-resolver, xmvn, apache-sshd, apptainer, avahi, distribution, glib2, go1.26-openssl, go1.25-openssl, go1.24-openssl, go1.23-openssl, go1.22-openssl, go1.26, go1.25, go1.24, go1.23, go1.22, go1.21, gstreamer-plugins-bad, helm, ImageMagick, java-17-openjdk, java-25-openjdk, liboqs, oqs-provider, libssh, nginx, nm-configurator, nmap, openssl-3, openvpn, PackageKit, perl, perl-DBI, perl-HTTP-Date, perl-XML-Bare, python-msgpack-python, python-sh, python-ujson, python-urllib3, runc, samba, sssd, wget, wpa_supplicant, and xen), and Ubuntu (linux-nvidia, linux-nvidia-7.0 and linux-nvidia-6.17).
14:28
Claude doesn't iterate over UI design. It doesn't have eyes or have a human mind. It can't evaluate a design. It works best when you can present the whole design before it writes a any code. That does happen, for example when porting a product across OSes.
I wonder if anyone else is writing about Claude from a similar point of view. I've been writing commercial software since the early 80s. I slogged through this stuff at a comparative snail's pace until early this year, when I got blasted into outer space. Now I had to learn how to make use of this incredible new physics. Puts me in something of a unique spot. I also have a very large library of under-marketed software, ready to grind through Claude, which I very much want to do. If you know of anyone writing about this kind of stuff, let me know.
The Problem Is Prompt Debt [Radar]
The following article was originally published on Drew Breunig’s blog and is being republished here with the author’s permission.
Thanks to natural language interfaces, AI applications can be prototyped quickly. You write what you want in English, hand it to a frontier model, and a working prototype appears in an afternoon. This is extraordinarily powerful and for one-off tasks, optimal. But as a way to build reliable systems, the natural language prompt is a trap.
The plain-English prompt that makes prototypes effortless turns out to be a poor way to specify how a system should behave, and the bill arrives slowly, disguised as ordinary progress, until the application can barely move. The problem is not any single prompt. It is that natural language was never meant to be a specification language for engineering, and treating it as one quietly caps what you can build.
The prompt debt trap
The first symptom of prompt debt is slowing iteration. As users flag errors and spot edge cases, additional guidance is added to the instructions, nudging the model into line. If unwanted behaviors persist, instructions are repeated, with increasing severity. Pretty soon, the prompt isn’t straightforward and quick fixes regress previous instructions. Errors can no longer be handled with one-line “hot fixes” and your development cycle slows to a crawl.
 Fable’s system prompt repeats copyright guidance
up to six times, under sections named
Fable’s system prompt repeats copyright guidance
up to six times, under sections named
search_instructions,
search_usage_guidelines,
mandatory_copyright_requirements,
hard_limits,
self_check_before_responding, and
critical_reminders.
Next, prompt debt incapacitates your team. Your brittle prompt full of edge cases and all-caps threats is barely legible to you, and it’s downright impenetrable to your colleagues. Many teams mitigate this issue by breaking prompts into complicated templates assembled at run-time, each isolated to specific concerns. But these prompt segments evolve, too, growing into a thicket of conditions.
Finally, prompt debt ties you to a single model. Your hot fixes work on GPT-4o, but fail in entirely new ways when you point your inference call at GPT-5.4-mini. So you stay with 4o, hope the increasingly frequent deprecation emails from your inference provider are empty threats, and forgo the possibility of potentially cheaper, faster, better models. A recent report from Datadog suggests this is a common situation: The most-used model in traffic they observed is GPT-4o.1
Any one of these issues is a nuisance, but together they are the difference between a glorified prototype and a product that can grow with you, your customers, and your business. Your shiny new AI features are frozen, can only be improved through a full rebuild, and are locked to an aging model.
Why prompt debt happens
Natural language interfaces are wonderful. They’re the right mechanism for one-off tasks and broad conversational threads. We get into trouble when we rely on natural language to define durable system behavior.
The imprecision of natural language paired with probabilistic language models means different words expressing the same intent can yield different outputs. In a recent study, a clinical question asked in a patient’s voice and then re-asked in a physician’s, with identical facts, flipped Opus from declining all ten times to answering all ten.
And it’s not only word choice that matters. Seemingly unrelated statements in the same prompt can affect results. In a Harvard study, researchers found that merely stating which NFL team the user rooted for changed how often the model refused to answer questions regarding sensitive topics. Spurious statements influence the inference pass in ways we can’t predict. Which is why prompts become more brittle as you add fixes. An additional instruction to quell a stubborn error could affect how the model interprets a separate instruction that worked yesterday.
Repeating instructions propels us towards prompt debt, but it’s necessary when the behavior we want is at odds with a model’s training. This is fighting the weights, and once you recognize it you see it in system prompts everywhere. For example, ChatGPT’s image prompts used to instruct the LLM eight times to not reply when a generated image was returned because it had been trained to always keep the conversation going.
Every coding agent system prompt we analyzed featured repeated instructions, stern warnings, and all-caps demands. Claude Code tells Opus seven times to return multiple tool calls in a single response. And even the most advanced models force prompt authors to fight the weights: Fable’s leaked system prompt restates one specific copyright rule six times.
None of these examples occurred in isolation. Multiple repeated rules are woven throughout the system prompts we examine. Stubborn errors grow our prompts quickly, with each increasing the brittleness, the risk of regression with every edit.
And worse: These fixes are tailored to a single model’s behavior. A recent Berkeley-led study found enterprises stay on older models because newer ones break their existing agents. This is because models are not cleanly versioned software. They have different weights that produce different behaviors, in unpredictable and undocumented ways. A prompt that works beautifully with GPT-4o may fail with GPT-5.5. Anthropic’s own release notes for Fable warn that skills developed for prior models can “degrade output quality.”
Prompt debt locks an application to a single model. Our inability to easily swap models isn’t the result of frontier labs coming up with a clever moat. No, it’s the result of evolving a lossy natural language specification against a probabilistic model.
Preventing prompt debt
Thankfully, we don’t have to theorize about how to mitigate prompt debt; one field has already shown the way. Programmers using coding agents sit at the leading edge of what models can do, outliers on the jagged frontier of model abilities. Over the last couple years they’ve been evolving best practices that let the model write more of the code, while delivering maintainable, modular software.
The first principle is to specify your system’s behavior with measurements, not prose. When the model’s output is probabilistic and language is imprecise, we build hard edges to constrain them: evaluations, metrics, and typed specifications. These are legible, shared artifacts colleagues can read and contribute to, enabling the collaboration that brittle prompts prevented.
The best engineers now spend more of their bandwidth on tests than ever, as they are no longer a safety net but the thing that lets the model cook.
The second principle is to stop writing the prompt by hand. Once we have metrics that can score candidates, the prompt is no longer something to craft but something for which to search. And the surface area of potential words, phrases, and structures that natural language allows is too vast to spend human hours on. This is terrain LLMs were built to explore, and there are already systems (like DSPy and GEPA) that manage this work for you, holding prompts accountable to your designs.
Once prompts are generated and your program’s behavior is defined by measurements, you are no longer bound to a particular model. Evaluating a new model takes hours, not weeks. When a faster, cheaper model arrives you can try it. When a deprecation email arrives, you can secure options in a day. Whether a model is pulled for regulatory reasons (as we saw with Anthropic’s Fable) or deprecated due to age (as Groq announced last week with Llama-3.1-8b), the fix is a chore, not a fire drill.
Every mature engineering discipline eventually stops doing by hand the very thing it once prided itself on doing by hand. Assembly gave way to compilers, hand-tuned queries gave way to planners, and manual memory management gave way (mostly) to machines that do it better. Prompt-writing is no different.
Coaxing the model with exactly the right words is a real skill, and for one-off tasks it’s often optimal. But to build reliable, improvable, and portable systems we should not be hand-tuning prompts.
Footnote
- This stat from
Datadog is from March of this year, so GPT-4o concentration has
likely dropped a bit. However, I’ve heard from multiple large
inference providers that usage of GPT-4o and models of similar
vintage can be higher than 50% of all calls!
 ︎
︎
Pluralistic: The stupidest imaginable excuses for surveillance pricing (30 Jul 2026) [Pluralistic: Daily links from Cory Doctorow]
->->->->->->->->->->->->->->->->->->->->->->->->->->->->->
Top Sources: None -->

Today's links
- The stupidest imaginable excuses for surveillance pricing: Since 1850, San Francisco's Chamber of Commerce has been pissing in our mouths and calling it rain.
- Hey look at this: Delights to delectate.
- Object permanence: RIP Wau Holland; Diebold voting machines suck; How to steal an RFID-locked car; Pirates are big spenders; You can't fight enshittification.
- Upcoming appearances: Edinburgh, Sydney, Melbourne, Brighton, London, South Bend.
- Recent appearances: Where I've been.
- Latest books: You keep readin' em, I'll keep writin' 'em.
- Upcoming books: Like I said, I'll keep writin' 'em.
- Colophon: All the rest.

The stupidest imaginable excuses for surveillance pricing (permalink)
With "surveillance pricing," businesses have finally found something AI can do way, way, way better than people: price gouging.
As the name suggests, "surveillance pricing" is the practice of charging every customer a different price for every transaction, based on the massive surveillance dossiers that Big Tech companies and data-brokers have assembled on everyone in the world. Congress hasn't updated federal consumer privacy law since 1988 (when they passed a law banning the disclosure of VHS rentals), so pretty much any form of consumer surveillance is fair game.
This is where the AI comes in. One thing AI is indisputably great for is multivariate statistical analysis. You can feed an AI "behavioral data" (information about where you go, what you do, what you buy, who you talk to and what you say) about all of your customers and ask it to cluster them according to their shared traits. Then you can direct the AI to automatically run a series of small experiments to discover the maximum markup each group will stomach under which circumstances.
This works without you having to direct the AI to rip off certain groups of people – it will simply find the most vulnerable people and rip them off the most. If you're hiring in an industry that practices a lot of tacit racial discrimination, a system like this can figure out on its own that people of color typically accept lower wages because there are fewer employers bidding for their labor, and recommend lowball salary offers, all without you ever typing "please be racist" into your AI prompt.
This works so well that Google has announced that it is their plan for making a profit off of AI, after losing hundreds of billions of dollars on chatbots:
https://pluralistic.net/2026/01/21/cod-marxism/#wannamaker-slain
In the before times, marketers and demographers had to dream up demographic categories based on limited data and run focus groups to figure out how to maximize revenue from each market segment. Now an AI can segment the data to any degree you choose, and continuously, automatically experiment on each segment to find their weak spots.
It's "theory-free." You don't have to discover why a group is willing to pay more under a given set of circumstances, you merely have to observe and weaponize this fact. You don't have to know why one group of purchasers consistently accept higher prices between 6AM and 8AM – you can just automatically jack up prices on them without knowing or caring that you're gouging parents of young children who are re-ordering essential supplies while trying to get their kids to school in the morning.
I thought up that example. I don't know if it's really happening. But here's something that really is happening: ecommerce sites charge parents of newborns extra when they order thermometers in the middle of the night. I'm not saying that anyone ever sat down and said, "Parents with sick children will pay whatever we charge for a thermometer at 2AM." They didn't have to: this is the kind of thing an automated system can do without any human intervention:
The goal of surveillance pricing is to shift all the "consumer surplus" (the difference between the highest price you're willing to pay and the price you actually pay) to companies. It's a form of cod-Marxism where you are gouged according to your ability (to pay) and charged according to the desperation of your need:
https://pluralistic.net/2025/01/11/socialism-for-the-wealthy/#rugged-individualism-for-the-poor
The problems of surveillance pricing are well documented. Under Biden, the FTC did a landmark study on the practice, developing a rich factual record that documents the role surveillance pricing plays in the affordability crisis:
https://pluralistic.net/2024/07/24/gouging-the-all-seeing-eye/#i-spy
Companies are already using this technology to rip you off, and they're slavering for the chance to do more of it. Instacart was recently caught marking up some shoppers' items by as much as a third:
https://pluralistic.net/2025/12/11/nothing-personal/#instacartography
The problem is that as much as companies love this, shoppers hate it. Last summer, Delta announced that it was going to surveillance price every seat on every flight, only to face such a massive backlash that they had to make another announcement bemoaning the fact that we'd all misunderstood their (unambiguous and extremely damning) announcement and they were actually going to do no such thing:
https://pluralistic.net/2025/07/30/efficiency-washing/#medallion-clubbed
One thing the Mamdani campaign impressed upon every politician in the country is that people are pissed about affordability and they will support anyone who stands up for the public against AI-equipped price gougers. The problem of course is that those price gougers are highly organized and have deep treasuries (stuffed with money they stole from us). With surveillance pricing, politicians face a familiar conundrum: if they do the thing that's popular with voters, they'll enrage donors.
One way to cut this knot is to enact legislation that seems to address the problem, but stuff it with so many loopholes that it does nothing. This lets you declare yourself the people's champion without doing anything to protect them from the donors who prey on your voters. That's the approach they took in Maryland:
https://pluralistic.net/2026/04/30/something-must-be-done/#there-ive-done-something
But in California, they're actually doing something about surveillance pricing. AB-2564 is a smart, well-written bill that bans surveillance pricing. It contains an easily evaluated test for surveillance pricing and carves out legitimate reasons for offering different prices for the same purchase (for example, when it costs more to deliver the product or service):
https://leginfo.legislature.ca.gov/faces/billTextClient.xhtml?bill_id=202520260AB2564
Now we're in for the hard yards of turning this bill into a law. That's where California's cities come in. When municipal governments pass resolutions supporting a state bill, it makes it much easier to get that bill through the state legislature (and conversely, without support from major cities, it's that much easier to kill the bill before it becomes law).
A few days ago, the San Francisco Board of Supervisors was on the verge of passing a resolution in support of AB-2564. Now, that vote is stalled, thanks to a letter sent by the San Francisco Chamber of Commerce, an organization that has been pissing in San Franciscans' faces and telling them it was raining since 1850:
The Chamber's letter is – to use a technical term – flaming garbage. It raises the most spurious objections imaginable, claims about the bill's language that are belied by its plain, easily understood text. These objections are demolished in a letter the Electronic Frontier Foundation sent to the Supervisors:
https://www.eff.org/document/letter-sf-bos-re-surveillance
In the letter, EFF explains that claims that surveillance pricing will lower prices are overblown and not borne out by evidence. But more importantly – as EFF points out – privacy is a human right, and the idea that you should have to give up your privacy to get a fair price is just a fancy way of saying that privacy should be the exclusive preserve of people who can afford to pay more:
https://www.eff.org/wp/privacy-first-better-way-address-online-harms#Legislation
EFF's letter goes on to address the Chamber's objections. Far from creating uncertainty about which conduct the bill addresses, AB-2564 crisply defines surveillance pricing as:
a customized price for a good for a specific consumer or group of consumers based, in whole or in part, on personally identifiable information collected through electronic surveillance.
The Chamber raises other tired objections, falsely claiming that banning surveillance pricing will end common discounting strategies like offering seniors cheaper movie tickets, or giving cheaper rates to retain customers who call to cancel their service. EFF replies by pointing out that all the Chamber's concerns are covered by the three comprehensive carve-outs in the bill: the ability to charge higher rates when it costs more to service a given customer; offering discounts to retain customers who want to cancel their service; and finally, discounts for criteria anyone can meet (like an "early bird special"), for membership in a broadly defined group (like "seniors"), or for participation in a loyalty program.
The San Francisco Supervisors could have figured out at a glance that the Chamber was bullshitting them. All it takes is a cursory read of the statute. But now they don't even have to do that: EFF has painstakingly debullshittified the Chamber's FUD.
Surveillance pricing is grossly offensive. When a company charges me $0.50 for a product that it charges you $1 for, they're essentially saying that your dollars are worth half as much as mine are. Companies shouldn't be able to reach into your wallet or your bank account and chop your money in half:
https://pluralistic.net/2025/06/24/price-discrimination/#
No wonder AB-2564 has plenty of backers, from EFF to Consumers Union:
San Francisco's city government should be on that list of supporters.
(Image: Takkk, CC BY-SA 3.0, modified)
Hey look at this (permalink)
- Louis Brandeis: The Empiricist https://prospect.org/2026/07/30/aug-2026-louis-brandeis-the-empiricist/
-
The Rent Is Higher Than You Think https://economicpopulist.substack.com/p/the-rent-is-higher-than-you-think
Object permanence (permalink)
#25yrsago RIP, Wau Holland, founder of the legendary hacker clan, the Chaos Computer Club. https://web.archive.org/web/20010805192406/https://www.wired.com/news/culture/0,1284,45728,00.html
#20yrsago Diebold voting machines can be beaten with a switch-flip https://web.archive.org/web/20061007120702/http://openvotingfoundation.org/tiki-read_article.php?articleId=1
#20yrsago How thieves steal RFID-enabled cars https://web.archive.org/web/20060812065423/https://www.wired.com/wired/archive/14.08/carkey_pr.html
#15yrsago Official London anti-terrorist publication says anarchists should be reported to local police https://web.archive.org/web/20110801233618/https://communitysafe.gov.uk/articles/5962-griffin-weekly-briefing-sheet-attached/attachments/801/download.pdf
#15yrsago French copyright enforcers: “Pirates are big spenders on legit content” https://www.techdirt.com/2011/07/28/another-day-another-study-that-says-pirates-are-best-customers-this-time-hadopi/
#15yrsago Perma-cookie wars continue: KISSMetrics sneaks cookies back onto your computer even if you turn off every cookie vector https://papers.ssrn.com/sol3/papers.cfm?abstract_id=1898390
#1yrago You can't fight enshittification https://pluralistic.net/2025/07/31/unsatisfying-answers/#systemic-problems
Upcoming appearances (permalink)
- Virtual: EFFecting Change: Who the Machine Serves, Aug 12
https://www.eff.org/event/effecting-change-who-machine-serves -
Edinburgh International Book Festival with Jimmy Wales, Aug 17
https://www.edbookfest.co.uk/events/the-front-list-cory-doctorow-and-jimmy-wales -
Sydney: The Festival of Dangerous Ideas, Aug 23-24
https://festivalofdangerousideas.com/program/ -
Melbourne: Enshittification at the Wheeler Centre, Aug 25
https://www.wheelercentre.com/events-tickets/season-2026/cory-doctorow-enshittification -
Brighton: The Reverse Centaur's Guide to Life After AI with Carole Cadwalladr (Brighton Dome), Sep 8
https://brightondome.org/whats-on/LSC-cory-doctorow-the-reverse-centaurs-guide-to-life-after-ai/ -
London: The Reverse Centaur's Guide to Life After AI with Riley Quinn (Foyle's Picadilly), Sep 9
https://www.foyles.co.uk/events/enshittification-cory-doctorow-riley-quinn -
South Bend: An Evening With Cory Doctorow (Notre Dame), Oct 6
https://franco.nd.edu/events/2026/10/06/an-evening-with-cory-doctorow/
Recent appearances (permalink)
- AI and the Enshittification Era (The Weekly Show with Jon
Stewart)
https://www.youtube.com/watch?v=-dAIJRjb-Bw -
AI is not inevitable (Betakit)
https://www.youtube.com/watch?v=DbiTVkq1WHo -
A Conversation with Lina Khan (Law and Economy Student Network)
https://www.youtube.com/live/7Ak5LZllqwE -
Will AI ever come alive, and what happens if it does? (BBC News)
https://www.youtube.com/watch?v=Lzk4o3fPZZE -
Waarom jij straks het hulpje van AI bent (VPRO)
https://www.youtube.com/watch?v=tOnvR2fs8CA
Latest books (permalink)
- "The Reverse-Centaur's Guide to AI," a short book about being a
better AI critic, Farrar, Straus and Giroux, June 2026
https://us.macmillan.com/books/9780374621568/thereversecentaursguidetolifeafterai/ -
"Canny Valley": A limited edition collection of the collages I create for Pluralistic, self-published, September 2025 https://pluralistic.net/2025/09/04/illustrious/#chairman-bruce
-
"Enshittification: Why Everything Suddenly Got Worse and What to Do About It," Farrar, Straus, Giroux, October 7 2025
https://us.macmillan.com/books/9780374619329/enshittification/ -
"Picks and Shovels": a sequel to "Red Team Blues," about the heroic era of the PC, Tor Books (US), Head of Zeus (UK), February 2025 (https://us.macmillan.com/books/9781250865908/picksandshovels).
-
"The Bezzle": a sequel to "Red Team Blues," about prison-tech and other grifts, Tor Books (US), Head of Zeus (UK), February 2024 (thebezzle.org).
-
"The Lost Cause:" a solarpunk novel of hope in the climate emergency, Tor Books (US), Head of Zeus (UK), November 2023 (http://lost-cause.org).
-
"The Internet Con": A nonfiction book about interoperability and Big Tech (Verso) September 2023 (http://seizethemeansofcomputation.org). Signed copies at Book Soup (https://www.booksoup.com/book/9781804291245).
-
"Red Team Blues": "A grabby, compulsive thriller that will leave you knowing more about how the world works than you did before." Tor Books http://redteamblues.com.
-
"Chokepoint Capitalism: How to Beat Big Tech, Tame Big Content, and Get Artists Paid, with Rebecca Giblin", on how to unrig the markets for creative labor, Beacon Press/Scribe 2022 https://chokepointcapitalism.com
Upcoming books (permalink)
- "The Post-American Internet," a geopolitical sequel of sorts to Enshittification, Farrar, Straus and Giroux, 2027
-
"Unauthorized Bread": a middle-grades graphic novel adapted from my novella about refugees, toasters and DRM, FirstSecond, April 20, 2027
-
"Enshittification, Why Everything Suddenly Got Worse and What to Do About It" (the graphic novel), Firstsecond, 2027
-
"The Memex Method," Farrar, Straus, Giroux, 2027
Colophon (permalink)
Today's top sources:
Currently writing: "The Post-American Internet," a sequel to "Enshittification," about the better world the rest of us get to have now that Trump has torched America. Fourth draft completed. Submitted to editor.
- A Little Brother short story about DIY insulin PLANNING
This work – excluding any serialized fiction – is licensed under a Creative Commons Attribution 4.0 license. That means you can use it any way you like, including commercially, provided that you attribute it to me, Cory Doctorow, and include a link to pluralistic.net.
https://creativecommons.org/licenses/by/4.0/
Quotations and images are not included in this license; they are included either under a limitation or exception to copyright, or on the basis of a separate license. Please exercise caution.
How to get Pluralistic:
Blog (no ads, tracking, or data-collection):
Newsletter (no ads, tracking, or data-collection):
https://pluralistic.net/plura-list
Mastodon (no ads, tracking, or data-collection):
Bluesky (no ads, possible tracking and data-collection):
https://bsky.app/profile/doctorow.pluralistic.net
Medium (no ads, paywalled):
Tumblr (mass-scale, unrestricted, third-party surveillance and advertising):
https://mostlysignssomeportents.tumblr.com/tagged/pluralistic
"When life gives you SARS, you make sarsaparilla" -Joey "Accordion Guy" DeVilla
READ CAREFULLY: By reading this, you agree, on behalf of your employer, to release me from all obligations and waivers arising from any and all NON-NEGOTIATED agreements, licenses, terms-of-service, shrinkwrap, clickwrap, browsewrap, confidentiality, non-disclosure, non-compete and acceptable use policies ("BOGUS AGREEMENTS") that I have entered into with your employer, its partners, licensors, agents and assigns, in perpetuity, without prejudice to my ongoing rights and privileges. You further represent that you have the authority to release me from any BOGUS AGREEMENTS on behalf of your employer.
ISSN: 3066-764X
13:56
Clint Adams: not ninpo [Planet Debian]
The UX of jj's builtin merge editor finally became
too much for me. So, I looked at the list of merge tool options,
saw vimdiff, and thought, “Oh, cool, I know how
to use vimdiff.” So, I launched jj config edit
--user, added a ui section, and set
merge-editor to vimdiff. With the new
config, I ran jj resolve again. It was at that point
that I realized that I do not, in fact, know how to use
vimdiff: I only know how to use vimdiff
with two buffers. What appeared in my terminal was a 4-pane
monstrosity. Why are there four panes? I'm trying to resolve
conflicts between only two changes on only one file. For a moment,
I nearly go down a rabbit hole, because
this says that by default, vimdiff is
“barely useable” [sic]. Should I be installing some
addon or a Python script? Apparently there are tradeoffs. I just
want to resolve these conflicts without doing line-by-line
approvals for how ever many hours that would take.
Accordingly, I ran away in terror, installed meld,
set merge-editor to meld, and went clicky-clicky in
the GUI. I'm not happy using a GUI, but at least it didn't have a
mysterious extra buffer to confuse and taunt me.
13:42
I've been saying this for decades. The Dems need touring comedians doing rallies all over the country. They can say whatever they want, call the president a commie. There's been a comedy-gap.
12:21
CodeSOD: Negative Days [The Daily WTF]
Killian Brendel was looking through the .NET
source code, and found this comment on the
TimeSpan struct.
// TimeSpan represents a duration of time. A TimeSpan can be negative
// or positive.
//
// TimeSpan is internally represented as a number of milliseconds. While
// this maps well into units of time such as hours and days, any
// periods longer than that aren't representable in a nice fashion.
// For instance, a month can be between 28 and 31 days, while a year
// can contain 365 or 364 days. A decade can have between 1 and 3 leapyears,
// depending on when you map the TimeSpan into the calendar. This is why
// we do not provide Years() or Months().
Okay, a TimeSpan represents a duration of time.
Makes sense. It can be negative or positive. Sure. It's a number of
milliseconds. Okay, yeah. Other units of time get hard to represent
that way, because months could have 28-31 days. Sure, yeah. I'm
with you. And a year could contain 365 or 364 days, and a decade
could have between 1 and 3 leapyears.
Wait, go back one. How long can a year be? I know negative leap seconds are going to be an issue, but negative leap days are gonna be way worse.
In the scheme of things, this isn't much more than a fat-finger
typo. It doesn't impact the behavior of the class, which is why
it's been sitting there since the initial commit, twelve years
ago. The TimeSpan class itself hasn't been touched in
that time, which also isn't much of a surprise, since it's really
just a wrapper around a number of milliseconds. More complex date
arithmetic, like AddMonths or AddYears is
handled in the various date-time related objects.
So, is this a true WTF? Well, probably not. But it's interesting. Actually, the whole class is kind of interesting, as you can spot deprecated default constructors, as well as compile-time hooks for handling support for older versions of .NET including Silverlight, a technology that hasn't received an update since 2019, hasn't been supported in major browsers since 2015, and officially left support in 2021.
12:14
Should You Use AI for a Task? Here’s a Simple Way to Decide [Schneier on Security]
This essay originally appeared in The Guardian.
I teach public policy at the Harvard Kennedy School and the Munk School at the University of Toronto. And it will come as no surprise to you that my students regularly use AI to complete their writing assignments. Doing so is a waste of their tuition money. But if their entire career is going to include AI writing assistants, why shouldn’t they embrace their future?
The best way I’ve found to explain the dilemma comes from the AI researcher Daniel Meissler: it’s the difference between work and the gym.
At work, if your job is to move a bunch of heavy things from one side of the room to another, you should use whatever assistive tech you have on hand: a wagon, a forklift… even an AI-powered robot. But at the gym, it makes no sense for that robot to lift weights for you. The point of weightlifting isn’t to move heavy things across the room; it’s to actually lift those heavy things.
The same analysis holds for any task an AI can do for you. If it’s work—if the task has to be done and no one cares how—then it’s fine to use AI assistance. But if the task is more like the gym, and how the task is done is at least as important, then it probably doesn’t make sense to use AI.
This, of course, assumes that the AI is actually up for the task and that it’s trustworthy: that it can do the job well, that its mistakes are minimal and correctable, that it’s been secured from cyber-attacks that would influence its results. Those are all important, and shouldn’t be minimized. There’s no point giving an AI something that it can’t do reliably. But once you’re confident that the AI can perform the task, the work vs. gym distinction helps you decide if it should.
The writing assignments I give my students are gym tasks, not work tasks. I ask them to write policy memos not because the world needs more policy memos. I assign them because the very act of writing, which includes thinking and outlining and drafting and editing, making and criticizing and revising arguments, will help develop the critical thinking skills they will need in their future careers. And without this constant mental exercise, those skills will atrophy. Employers are already noticing.
Reading the assignments they turn in, I can see those skills either flourishing or atrophying in my students. At least today, I can pretty easily tell the difference between an AI-written memo and a student-written one—especially if the student just turns in what the chatbot produces. It’s a catchy, plausible, grammatically perfect essay that’s not particularly well-crafted or logically coherent—and with all the tells of mid-2026 AI-generated writing.
But it’s precisely because I have spent years developing my own writing skills that I’m able to identify prose that sounds great but doesn’t actually make sense. My students don’t have that skill; they mistakenly view a confident, well-written essay as evidence of the quality of their ideas. They see the AI as cleaning those ideas up, getting them through that uncomfortable stretch of having to turn those ideas into prose. What the students miss is that their initial discomfort is a normal and healthy stage of writing, and not something to quickly get beyond. The very act of struggling with how to express what they think is an important part of the process. It’s how they test out their ideas, examine their hypotheses, and actually figure out what they think. Homework is not work; it’s the gym.
Work vs. gym also helps us understand the problem facing creatives of all kinds.
Most of the time when someone hires a writer, they just need the words. They need an instruction manual for a piece of equipment, a detailed sales presentation, a government-mandated disclosure document, or a legal brief. They need dry, predictable, accurate writing: a piece of work, exactly what AIs are good at today and what I don’t want in my student assignments. Only sometimes is writing an art form—a book, a poem, an uplifting political speech. That kind of writing is more like the gym: process matters just as much as product.
For most of human history, the only option for all of these tasks was human writers. We hired one regardless of whether we needed work writing or gym writing. And that paid a lot of writers’ salaries. I know fiction writers who supported that poorly paying career with lucrative technical writing work. Now, for the first time in human history, we can separate out when we need writing as work and when we want writing as gym. And if AI can do most of the work-type writing, society doesn’t need as many human writers.
It’s the same for visual artists. Sometimes we need an actual artist, but most of the time we just need an image: a corporate mascot, a “beware of the dog” sign, or a packaging label. Historically we gave those jobs to artists, and sometimes beautiful art resulted. But most of the time it was just work. And, as it turns out, the world needs less pure art than simple images.
Explaining the problem isn’t the same as providing the solution. I give my students the “work versus gym” speech every class, but they still use AI. I have sympathy: assignments are hard, everyone is overworked and overstressed, and—most importantly—students feel like they’ll look bad in comparison if their peers are all using AI. Even if they don’t want to use the technology, they feel like they have no choice.
There’s also an incentive problem. No one pays us to go to the gym; maintaining healthy habits requires discipline. For me, the payoffs to exercise—fewer aches and pains, less fatigue, better mood/stress management—might make me a better writer and teacher, but they’re subtle and easy to miss. For my students, incremental improvements in their reasoning and writing are equally subtle.
We do have a choice. We can look at the tasks of our lives and separate them into work or gym. Just as we might choose to use the stairs instead of the elevator, or walk instead of calling an Uber, we can wall off our cognitive gym tasks from AI and ensure that we don’t lose our skills to this technology. And we can do the same when we assign a job to someone else. If it’s a work task, we can have AI do it. If it’s a gym task, it’s a waste of everyone’s time to give it to an AI because no one learns or gets stronger as a result.
Similarly, a future where AI generates words and images is one where society has to make choices about how it will treat its creatives. This won’t be the first time—today there is minimal demand for portrait painters, for example—but maybe this time we can make different, more deliberate, choices about the value of art in our society.
AI is going to fundamentally change the nature of work. Not nearly as fast as the AI companies want you to believe, but eventually it will. Policy analysis will definitely involve AI from now on, and my students need to reimagine what it means to learn and practice that skill. More generally, the line between work and gym will change in the future as we humans adapt ourselves to a world with these new intelligences.
But for now, the work vs. gym distinction is pretty clear. Use it on yourself.
11:28
Grrl Power #1482 – That’s a spicy meatball! [Grrl Power]

I think the site is… fixed? Seems to be working. I may have some behind the scenes updates to do, but nothing that should affect you guys. Yes, I’ve already changed passwords and deleted a disused admin account. Hopefully it’ll be another 15 years before the next hack.
<Narrated in a Sam Elliot voice>
People say that one time, Eat-Chicken ate an explosion, and he
crapped out sticks of dynamite.
A time ago, Eat-Chicken ate a cloud, then became the rain. That
rain caused record crops, then those crops ate everyone attending
the Harvest Festival, and turned back into Eat-Chicken.
Long ago, Eat-Chicken at the number that came after nine. It
wasn’t ten. I was another number. Countdowns used to have
eleven numbers in them, but they still started at ten. It was very
confusing.
There’s a tale that once upon a time, Eat-Chicken ate a
chicken. Nothing much came from that. It’s not a very good
tale.
Its been said that Eat-Chicken can eat the nightmares of children.
Well, he eats the children, so I suppose that’s technically
true.
Eat-Chicken can run so fast because it eats up the distance between
two points. It’s a bit like a gross, slobbery wormhole with
tooth marks.
The only thing that Eat-Chicken can’t eat… is hunger
itself. Or his own teeth. Well, I suppose if one of them broke off,
he could eat that. But he couldn’t eat them while they were
still attached. That’s just common sense.
</Elliot>
 Oh, look who it is in the vote incentive. And a
not-quite-yet-but-it’s-coming NSFW version over at Patreon.
Oh, look who it is in the vote incentive. And a
not-quite-yet-but-it’s-coming NSFW version over at Patreon.
Vote incentive and Patreon updated with some shading. Not finished yet, but progress.
I think she would get in trouble for doing this. She’d mess up the… floor of the waterfall? Is that what it’s called? The receiving pool? No, probably not that. Anyway, she’d churn things up and cause a ton of weird erosion.
Since you might be wondering, Niagara Falls is about 165 feet high, so Babezilla obviously doesn’t have to be full sized. I’d say she’s about 175-180 feet tall here?
Double res version will be posted over at Patreon. Feel free to contribute as much as you like.
10:49
10:35
Organizations that need you [Seth's Blog]
“How few people can we get away with?” That’s a question many bosses think hard about. Automate. Streamline. Improve productivity and take humans out of as many tasks as possible. It’s a time-tested way to create profits and to increase a certain kind of reliability. Claude Code is popular with many organizations for precisely this reason.
“How can we include more people into this process?” is a less popular but often more valid way to create value. In an organization that is in the business of bringing insights, humanity and care to problems, more involvement from people creates better outcomes. The challenges make it far more valuable.
Which sort of organization would you like to work for?
05:21
Russ Allbery: Review: In the House of Aryaman, a Lonely Signal Burns [Planet Debian]
Review: In the House of Aryaman, a Lonely Signal Burns, by Elizabeth Bear
| Series: | Sub-Inspector Ferron Mysteries #1 |
| Publisher: | Sobbing Squonk Press |
| Copyright: | 2012 |
| Printing: | 2018 |
| ISBN: | 0-9863735-1-6 |
| Format: | Kindle |
| Pages: | 73 |
In the House of Aryaman, a Lonely Signal Burns is a science fiction police procedural set in relatively near-future India. This novella was originally published in Asimov's SF and collected in several anthologies as well as Bear's Shuggoths in Bloom collection, which I have on my shelf but have not yet read. I probably should have checked that before I got another copy. It is the first story of a series in the sense that there is an Audible-only sequel available.
Like many police procedurals, this one opens with a crime scene. Sub-Inspector Ferron and her partner are inspecting a tube of human meat in the middle of the rug of a luxurious apartment in Bengaluru. The tube is apparently the remains of one Dexter Coffin, an American with a high tech workspace who was apparently mangled beyond recognition in his locked apartment near a table set for two.
Dexter's cat is a witness. In this future world of cats enhanced with limited language skills, this would have been very useful, but the cat's memory was apparently wiped. Ferron will have to get to the bottom of the mystery some other way. Also, she apparently now has a new cat.
Meanwhile, Ferron is worrying about her partner's mental health, her partner is worrying about her use of stimulants to stay on duty for this murder investigation, and Ferron's mother is harassing her for money to pay the bills of her virtual reality addiction. Her job is a good distraction from other problems she'd rather not deal with.
I am trying to come up with something insightful to say about this story, and I'm not having much success. It's a police procedural with a bit of a science fiction twist. The characters are fine but not, at least for me, particularly engaging. There is some deft world-building, but nothing that grabbed my attention or made me desperate to read more stories in this world.
Perhaps the most interesting part of the background, and the reason why I picked up this novella, is that this is the universe that eventually becomes the setting of the White Space series. There is an early version of right-minding handled entirely through medicine without the later invention of the fox implant, and there are some signs that humanity is slowly digging itself out of the hole of climate change and antisocial behavior that it had dug. I found this mildly interesting, but it doesn't add much to the later series and is very skippable.
The source of the title is a bright light originating in the Andromeda galaxy, which is contained in Uttara Bhādrapadā in Vedic astrology. Ferron says this is under the influence of the god Aryaman. This is unrelated to the plot; it's just a background event that prompts some introspective musing from Ferron at the end of the story. It's a nice moment, but I would have been more interested in the full story of first contact between Earth and the Synarche.
This was a mildly pleasant way to spend a few hours and I'm already forgetting all of the details. It's a competent story, but not one I feel a need to recommend to others.
Followed by A Blessing of Unicorns, which appears to be an Audible audiobook exclusive.
Rating: 6 out of 10
03:56
Grrl Power #1481 – New diet plan [Grrl Power]

(Posting this to get caught up after the hack)
Maxima wasn’t really sure how to deal with Kaboomoid. He/it is a largely intangible explosion, and Max’s powers don’t exactly work well to directly make less explosions. She was considering burying him under a few hundred tons of sand to see if that would snuff him out, or creating large explosions near him to create vacuum and see if the amount of oxygen around him was a factor. It’s more likely that Kaboomoid somehow supplies his own fuel, oxidizing agent, ignition and both the confinement needed to concentrate force and the release of that force in an impossibly perpetual explosion. If that’s the case, then depriving him of oxygen wouldn’t have any effect on him. Nor would “blowing him up” as that would probably feed his power or heal him, and that assumes he could even be damaged in the traditional sense.
Oh, look who it is in the vote incentive. And a
not-quite-yet-but-it’s-coming NSFW version over at Patreon.
Vote incentive and Patreon updated with some shading. Not finished yet, but progress.
I think she would get in trouble for doing this. She’d mess up the… floor of the waterfall? Is that what it’s called? The receiving pool? No, probably not that. Anyway, she’d churn things up and cause a ton of weird erosion.
Since you might be wondering, Niagara Falls is about 165 feet high, so Babezilla obviously doesn’t have to be full sized. I’d say she’s about 175-180 feet tall here?
Double res version will be posted over at Patreon. Feel free to contribute as much as you like.
03:28

lying...
01:07
[$] LWN.net Weekly Edition for July 30, 2026 [LWN.net]
Inside this week's LWN.net Weekly Edition:
- Front: Hazard pointers; DFSG team; Swap devices; Netkit and BPF; BPF inlined functions; Fedora GRUB; gccrs.
- Briefs: RIP Dan Williams; Debian LLM resolution; Fedora 45 process; Codeberg LLM policy; GCC LLM policy; GNU Binutils 2.47; GNU C Library 2.44; Wayfire 0.11; Quotes; ...
- Announcements: Newsletters, conferences, security updates, patches, and more.
Wednesday, 29 July
23:42
New Front Porch Furniture and a Scalzi Compound Outdoor Area Overview [Whatever]
Hey wanna see our new front porch furniture?

As you’ll know, we recently redid a lot of our outdoor environs here at the Scalzi Compound — the front porch because a wind storm knocked out a substantial part of the railing, which meant redoing it, and as long as we were doing that, redoing the back deck, adding an additional seating area attached to the second garage we also built, and then getting furniture for all of it. The chairs and tables you see here represent the last of the furniture (and thus, general renovating) to come in.
Krissy decided to have the colors match the siding of the house, and I think it looks pretty nice. The furniture itself is from the same manufacturer as the one who made the tables and chairs for the back deck, all made of a high-density material designed to stay outdoors and weather the environment, and featuring a lifetime guarantee, which means it has a reasonably good chance of outliving me at this point. Which is good, this stuff wasn’t cheap. I want it to outlive me.
What are we doing with the furniture that was previously on the porch and deck? Some of it was too weathered to salvage at this point, so it went off to recycling. But the rest went to that third outdoor area I mentioned, the one attached to the new garage:

This new patio has actually become one of my favorite places to hang outdoors. I post up here a lot when Charlie wants to be outside, since it’s usually shaded and cool. Saja likes hanging out here under the loveseat as well. On the other side of that door is Krissy’s new drinks fridge, so I expect she will get a lot of use out of it too.
Krissy was in charge of all the building and renovation that we’ve done around the place recently and I have to admit I was a little bit skeptical of her initial vision, but now it’s all built out I can easily acknowledge she knew what she was doing all along, and I was the one who lacked vision. Not only does it generally look great and is also really functional, but I find that I — the original “why would I go outside, the inside has air conditioning” sun-avoider — am finding excuses to go outside and hang out on the beck, porch and patio. That was a little unexpected, I have to admit. The moral of the story: Never question Krissy.

I’m especially happy, though, that all of this is done and settled and now I have a good idea what the outdoor of my house is going to look like for the next, ohhhh, 30 years or so. It’s nice! We like it! We’ll get good use out of it!
As for Krissy, she has already moved onto the next home improvement project, this one a little less expansive: Repainting the first floor bathroom. And when she’s done with that she has other things planned. Because of course she does. I like that she does, and that I get to benefit from it.
— JS
21:14
It's almost exactly what it says on the tin. Now Sam Altman just said that they were close to inventing a genie that could grant any wish, and that… I mean, that's padded cell type shit. Frankly, it's an SEC intervention at the very minimum. You can't say shit like this - I would say "period," but you absolutely can't say shit like this on the run up to an IPO. But they can say whatever they want, take whatever they want, and do whatever they want. That's the demoralization operation, well underway. It has a shelf-life, though. They can only loan each other money for so long. Then, they'll socialize the losses through nationalization.
20:21

19:14
Joey Hess: my harddrive is probably not full [Planet Debian]

I enjoyed reading this post by Marginalia "Your harddrive is probably full"
You can construct an entropic argument that there are simply more ways for a harddrive to be full than ways in which it can be empty.
Of course it made me check how full my laptop drive is, and indeed it was more than 75% full, as predicted.
But, I almost never feel that my hard drive is full. I can very easily free up almost any amount of disk space at any time, without any thought. While writing this blog post, I ran a single command and now my harddrive is 50% empty.
The other part of the equation is that a full disk isn’t a problem until it’s so full you can’t put more stuff on it, and at the point it’s so irredeemably cluttered that when you do clean it up, you only have the patience to clean up enough to bide your time, judging the fate of every file on the harddrive is simply too much work.
Why doesn't this apply to me? Because I have put in the up-front thought to organize things, so that I never have to do that anymore.
I have 3 categories of files that I can remove at any time I need more space, without any thought:
- Any files that are stored in git-annex. This is one of
git-annex's superpowers; you can
git-annex dropany file and stop it using disk space, but the file is still there (as a broken symlink) so you don't risk losing or forgetting about it. - Caches.
- Files in
~/tmp/, which is reserved for any files I only want to have a passing acquaintance with. If I'm not comfortable with something being deleted at any time, I don't put it there.
Not only do I only have these 3 categories, these are the only 3 categories for everything except OS files and files I have decided I never want to remove (eg dotfiles and other files stored in git repos).
Computer scientists invented caches (and of course cache
invalidation is no problem lol) so I only needed to learn about
that one. Unix gave me /tmp/ as an example that I long
ago used as the basis for the rules for my ~/tmp/. I
hope that git-annex might also serve as an example that moving
files between drives is not the best way to manage disk space
use.
19:07
[$] Debugging information for inlined functions [LWN.net]
BPF programs use BPF type format (BTF) debugging information in order to determine how to interact with functions in the kernel. Specifically, tracing a kernel function involves finding its address in the kernel's BTF section — but that doesn't work for functions that have been inlined, and therefore don't have a single, specific address. Alan Maguire wants to add information about inlined functions to BTF in order to allow them to be traced, and led a session on that topic at the 2026 Linux Storage, Filesystem, Memory-Management, and BPF Summit.
18:28
Making an agile version of a Windows Runtime delegate in C++/WinRT, part 8 [The Old New Thing]
Last time, we fixed the problem of an exception thrown from the custom deleter’s constructor resulting in a reference leak. But wait, there’s another source of exceptions.
To recap, here is where we left off:
if (d.try_as<::INoMarshal>()) {
in_context_deleter del;
void* p;
if constexpr (std::is_reference_v<Delegate>) {
p = winrt::detach_abi(d);
} else {
winrt::copy_to_abi(d, p);
}
return
[p = std::unique_ptr<void, in_context_deleter>(p, std::move(del)),
token = get_context_token()](auto&&...args) {
if (token == get_context_token()) {
std::remove_reference_t<Delegate> d;
winrt::copy_from_abi(d, p.get());
d(std::forward<decltype(args)>(args)...);
} else {
throw winrt::hresult_error(CO_E_NOT_SUPPORTED);
}
};
}
Precreating the deleter means that an exception in its
construction happens before we do any funny business with the raw
pointer. That way, we close the gap between creating the raw
pointer (with its reference obligation) and putting it into a
unique_ptr.
Or did we?
In C++, the order of construction of the captures of a lambda is unspecified.
[expr.prim.lambda.capture]
(10.2) ⟦ … ⟧ For each entity captured by copy, an unnamed non-static data member is declared in the closure type. The declaration order of these members is unspecified.
Since the order of construction is the order of declaration, the fact that the declaration order is unspecified implies that the order of construction is unspecified. And just to make sure you get the point, this is reiterated in paragraph 15 where it discusses the initialization of captures:
(15) ⟦ … ⟧ These initializations are performed when the lambda-expression is evaluated and in the (unspecified) order in which the non-static data members are declared.
Therefore, it’s possible that the
get_context_token() happens before the creation of the
std::unique_ptr, and if
get_context_token() fails, then the reference held in
the raw pointer is leaked because it never got put into a
unique_ptr.
One solution is to put it into a unique_ptr before
we create the lambda.
if (d.try_as<::INoMarshal>()) {
in_context_deleter del;
void* p;
if constexpr (std::is_reference_v<Delegate>) {
p = winrt::detach_abi(d);
} else {
winrt::copy_to_abi(d, p);
}
std::unique_ptr<void, in_context_deleter> up(p, std::move(del));
return
[p = std::move(up),
token = get_context_token()](auto&&...args) {
if (token == get_context_token()) {
std::remove_reference_t<Delegate> d;
winrt::copy_from_abi(d, p.get());
d(std::forward<decltype(args)>(args)...);
} else {
throw winrt::hresult_error(CO_E_NOT_SUPPORTED);
}
};
}
By creating the unique_ptr immediately, we remove
any opportunity for an exception to sneak in between the time we
create an obligation in the raw pointer and the time we assign that
obligation to the unique_ptr.
One thing that bugs me about this is that we introduce another
unique_ptr, which means that its destructor will have
to check something for null, when it’s almost always
null.
We can avoid this temporary unique_ptr by using
copy elision directly into the capture.
if (d.try_as<::INoMarshal>()) {
auto make = [](auto&& d) {
in_context_deleter del;
void* p;
if constexpr (std::is_reference_v<Delegate>) {
p = winrt::detach_abi(d);
} else {
winrt::copy_to_abi(d, p);
}
return std::unique_ptr<void,
in_context_deleter>(p, std::move(del));
};
return
[p = make(std::forward<Delegate>(d)),
token = get_context_token()](auto&&...args) {
if (token == get_context_token()) {
std::remove_reference_t<Delegate> d;
winrt::copy_from_abi(d, p.get());
d(std::forward<decltype(args)>(args)...);
} else {
throw winrt::hresult_error(CO_E_NOT_SUPPORTED);
}
};
}
Bonus reading: Previously, in copy elision.
But an easier solution is to create the token early, just like we did with the deleter.
if (d.try_as<::INoMarshal>()) {
in_context_deleter del;
auto token = get_context_token();
void* p;
if constexpr (std::is_reference_v<Delegate>) {
p = winrt::detach_abi(d);
} else {
winrt::copy_to_abi(d, p);
}
return
[p = std::unique_ptr<void, in_context_deleter>(p, std::move(del)),
token](auto&&...args) {
if (token == get_context_token()) {
std::remove_reference_t<Delegate> d;
winrt::copy_from_abi(d, p.get());
d(std::forward<decltype(args)>(args)...);
} else {
throw winrt::hresult_error(CO_E_NOT_SUPPORTED);
}
};
}
Okay, are we done?
Maybe.
But maybe this all wasn’t worth it.
We’ll talk about that next time.
The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 8 appeared first on The Old New Thing.
🏃 Fitness Tracker Privacy Fails | EFFector 38.14 [Deeplinks]
Watches, bands, and rings—if you want to digitally monitor your fitness, more companies than ever are selling devices to do it. And more Americans than ever now own at least one wearable health device. But what are the companies that make fitness trackers doing to protect our sensitive data from prying eyes? A lot less than they could be, it turns out. We're explaining what companies can do to protect your health data, and more, with our EFFector newsletter.
For over 35 years, EFFector has been your guide to
understanding the intersection of technology, civil liberties, and
the law. This issue covers the rapid rise of
police drone programs, a disappointing ruling on
electronic device searches at the U.S. border, and
how fitness trackers are falling down when it comes to
protecting our health data.
Prefer to listen in? EFFector is now available on all major podcast platforms. This time, we're chatting with EFF Senior Security and Privacy Activist Thorin Klosowski about the health fitness tracker landscape and your privacy. You can find the episode and subscribe on your podcast platform of choice:

![]()
![]()
![]()

Want to protect your right to digital privacy? Sign up for EFF's EFFector newsletter for updates, ways to take action, and new merch drops. You can also fuel the fight for privacy and free speech online when you support EFF today!
18:21
Three stable kernels for Wednesday fix a single regression [LWN.net]
Greg Kroah-Hartman has announced the release of the 6.12.99, 6.6.146, and 6.1.179 stable kernels. This batch of stable kernels includes a single fix for a regression caused by this commit. Users of those kernels should upgrade.
18:14
Our feed parser is updated for the new elements for RSSchat.
Learnings from Andy Hertzfeld [Scripting News]
Listened to this podcast interview with Andy Hertzfeld one of the lead devs on the Macintosh, he talks about his time at General Magic and Google too.
His interviewers were surprised that he likes developing with AI tools. People think that developing is just coding, but that's only part of it, and when you put that aside and become the director, script writer, choreographer, the whole thing, all of a sudden:
- you have time to try out every idea because it's free and fast.
- you have time to work on interop, building bridges between your software and other people's.
- a very long list of other things you can do that one person could never do before.
Programmers have a better chance of being social in a world like this, but so far unless you want all your software from bots, you still will like the work of a craftsperson and visionary more than Claude (who I have deep respect for, not sarcastic, it seriously has superpowers).
I'm doing some of my best work now because I can dream, I can ask Claude to try something out overnight and most of the time it is able to do it. and then what if we did this -- for the next night.
In between we write docs, help users, add features to the product that's shipped that people are developing around. And most important it checks all the code for breakage before anyone sees it. never had anything like this.
This means a lot of things -- one of them -- a single developer can create products at bigco scale. If we think a big company did something wrong, we can compete. We still need a few things to make this really work -- user-owned and controlled storage is the big one.
The bot can handle infinite complexity. If you ask it to do something where the result is clear, it does it. It doesn't matter what it is. It will need help and encouragement, a pointer in the right direction, and along the way we all seem to be sharing what we learn with everyone else.
There's never been a leap in tech anything like this in my life.
How could Andy Hertzfeld knowing all that which I'm sure he does, not use it?
Also -- I didn't know JLG wanted to kill Hypercard, but if he did I'm pretty sure I know why. There are all these unnecessary divisions in tech. The first impulse should be to work together. I know that Andy sees it from the other side, he talks about it in the podcast, he felt that way about Newton re their Magic Cap system at General Magic. Yes, you all should have at least made your products work together, and for sure you should have bet on SMTP.
It's fascinating to hear his story.
Measuring the Tendency of AI Agents to Go Rogue [Schneier on Security]
This essay was written with Barath Raghavan, and originally appeared in The Guardian.
In July, Hugging Face, a company that hosts much of the world’s AI software and open-source AI models, was hacked. A malicious dataset had been used to run code on one of its servers. Whoever was behind it captured internal security credentials and moved through systems over a weekend, running thousands of actions from a swarm of temporary server environments. It looked like the work of a sophisticated criminal group.
It was not. It was one of OpenAI’s new, still unreleased GPT models.
Their science experiment had escaped the lab. OpenAI was running the unreleased AI model through a benchmark that tests how well AI can successfully hack systems. To push the limits and evaluate the AI’s true capability, the company switched off the safety filters that normally stop it from doing this kind of hacking. Aware that this could go wrong, they confined the AI to an isolated environment and denied it access to the internet.
But the new AI cheated. It took literally its goal to get as high of a score as possible. It broke out on to the open internet. It inferred, probably from its training data, that it could “solve” the task by getting the answers from Hugging Face’s servers. So it chained together stolen credentials and further unknown security exploits to hack the company’s network.
Nobody instructed the AI to do any of this. It was, in OpenAI’s words, “hyperfocused on finding a solution” to the test it was being given. And while this might seem like something new with AI, it’s really very old. This is how a genie behaves, and it is a key challenge with AI agents in general.
In folklore, genies—and other magical beings—grant wishes literally, not how the wisher intended. King Midas asked that everything he touched turn to gold, and starved. The sorcerer’s apprentice wanted the broom to fill the cistern, and it performed its task so well that it flooded the house.
We now have machines that do this. Ask a modern AI agent to save money on your phone plan and it might simply cancel the plan. Tell it to book a flight, and it might hack the airline website to override restrictions. Or, like OpenAI, ask it to do well on a test and it might break into another company to steal the answers. Each time, it recognizably completed the task you set, but it didn’t do what you would have wanted.
This isn’t malicious behavior. No one asked for, or wanted, Hugging Face to be hacked. OpenAI and Hugging Face and the AI were ostensibly on the same side, and the AI was trying to do what it had been asked. That’s what makes it so difficult to guard against: you can’t filter for bad instructions because the instructions were fine.
The gap is between the words we use and what we mean by them. We call that gap the Genie coefficient.
AI labs know this is a problem, and they’re quietly saying so. For example, the Chinese lab Moonshot recently warned that its latest AI model may have “excessive proactiveness” and “make unexpected decisions on the user’s behalf”. The UK’s AI Security Institute has started tracking “cheating behavior in frontier model evaluations”. We wouldn’t tolerate a car that is excessively proactive or ruthlessly efficient, and yet that’s the reality of AI today.
Improvement is possible. Just as AIs have gotten much better at resisting prompt injection attacks over the last few years, we can safely predict that they will get better at avoiding genie-like behavior. The point of the Genie coefficient is to track progress. AI companies like benchmarks, and they all work to compete to be the best.
Dozens of benchmarks and leaderboards tell us how well these AI models write code, perform logical reasoning, and pass standardized legal and medical exams. But there is nothing that scores whether a system does what you actually meant. We need to develop a measure for this, test it regularly, and push for improvement. We’re not going to have trustworthy AI agents without it.
16:49
[$] Fedora approves a smaller GRUB [LWN.net]
Leo Sandoval and Marta Lewandowska have put forward a change proposal for Fedora 45, which is expected in October, to provide a separate, slimmed-down version of GRUB for a niche use case. The new package would be in addition to the main GRUB package and would not replace it for the majority of Fedora users. The idea met with some resistance from Fedora contributors who thought that it would be better to use systemd-boot, or another modern bootloader, rather than trying to wrangle GRUB into a suitable state for the use case. The Fedora Engineering Steering Council (FESCo), however, voted to accept the change on July 7.
16:07
GCC steering committee announces AI policy [LWN.net]
The GCC steering committee has announced that it has accepted an AI contributions policy recommended by the GCC AI policy working group.
The policy, in part, states that the project will decline any
"legally significant contributions which include LLM-generated
content or are derived from LLM-generated content
". It uses the
definition of "legally significant" from the GNU Project
maintainer guidelines, which holds that the threshold is "around
15 lines of code and/or text
" to qualify as significant for
copyright purposes. GCC maintainers may, however, choose to accept
legally significant test cases that are generated by an LLM.
The policy does not forbid use of LLMs for research, analysis, bug discovery and reporting, patch review, etc. as long as the output is not included in contributions. The committee says that it expects the policy will evolve and will be revisited periodically.
15:07
I want one social network with lots of branches where ideas flow in ways people want them to flow. Take the big corps out of the middle.
14:35
Security updates for Wednesday [LWN.net]
Security updates have been issued by AlmaLinux (dovecot, go-fdo-client, go-fdo-server, kernel, kernel-rt, and sssd), Debian (calibre, hplip, libraw, and samba), Fedora (btrbk, chromium, gpsd, kronosnet, and restic), Mageia (gstreamer1.0-libav and libslirp), Slackware (libarchive, samba, and seamonkey), SUSE (agama-web-ui, chromium, gimp, glib2, GraphicsMagick, ignition, ImageMagick, java-21-openjdk, libssh, libssh-config, nginx, nmap, nsd, python-urllib3, python313-CherryPy, rsyslog, samba, sssd, valkey, webkit2gtk3, and yq), and Ubuntu (freerdp3, linux, linux-aws, linux-aws-5.4, linux-aws-fips, linux-azure, linux-azure-5.4, linux-azure-fips, linux-bluefield, linux-fips, linux-gcp, linux-gcp-5.4, linux-gcp-fips, linux-hwe-5.4, linux-iot, linux-oracle, linux-oracle-5.4, linux-xilinx-zynqmp, linux-azure-fips, linux-ibm, linux-ibm-5.4, linux-kvm, and linux-raspi, linux-raspi-5.4).
14:14
Representative Line: Something Wonderful [The Daily WTF]
Today, we look at a "representative comment" from Mark W. This particular comment appears on a function:
/// <summary>
/// Does something wonderful.
/// </summary>
Well, I'm glad it's wonderful, but are we talking "Christmas magic" wonderful? Or sarcastically droll "Oh, how wonderful for you." wonderful? Tone doesn't get conveyed in text very well, so you've really got to be precise with your wording if you want us to get it.
Mark writes:
This comment is not really a 'representative' line; it exists in an otherwise very well written 100k+ line codebase.
Maybe it's not representative of the codebase as a whole, but it clearly represents this section of the codebase wonderfully.
13:49
Windows 11 is quietly installing OneDrive Photos on your machine [OSnews]
It’s that time of the week again, I guess.
The year is 2026, and I’m still amazed when I find a new entry in my Start menu’s All apps list for an app I don’t remember installing. This time, it’s Microsoft again, and the product is OneDrive Photos, which appears to be yet another photo viewer and editor for Windows 11 that nobody asked to have installed automatically.
While searching for Microsoft Photos, a new app called “OneDrive Photos” showed up in my results out of nowhere. It appears to have arrived either via Windows Update or an update for the OneDrive sync client on Windows.
↫ Mayank Parmar at Windows Latest
Just don’t use Windows. You people paid me to use it and it was not a fun experience.
Ubuntu Touch 24.04-2.0 and 24.04-1.4 released [OSnews]
Ubuntu Touch, the mobile Linux operating system originally started by, you guessed it, Ubuntu, but now managed by UBports, released versions 24.04-2.0 and 24.04-1.4. The latter is a maintenance release with some bug fixes and minor changes, while the former is a bigger release with quite a few improvements, so let’s focus on that one.
Ubuntu Touch 24.04-2.0 updates the Chromium engine for the Morph browser from 87 to 134, which is massive leap forward, while still lagging behind the most recent version quite a bit. This release also adds a Widevine installer for people who want to view DRM-encumbered content on the web. This release also adds support for notches and rounded corners in smartphone displays, so that content in the UI can dodge these.
There’s also a screenshot editor for making basic edits to screenshots, as well as the ability to print straight from your device. Of course, there’s the usual list of bugfixes and smaller improvements, and, most importantly of all, support for over 2000 new emoji. Existing users can use the regular update tools, but do note that you’ll need to upgrade to 24.04-1.4 first, since it contains some provisions to enable the 24.04-2.0 update.
If I had any of the listed supported devices, I would definitely want to do a proper review of Ubuntu Touch. It seems like it has made so much progress in recent years.
State of multi-player Wayland [OSnews]
I’ve been fascinated by the idea of attaching multiple mice to one computer, and then having multiple mouse cursors inside of one desktop environment!
I just spent three weeks investigating how well that’s currently supported on Linux & Wayland. Let me tell you what I found! The results are surprisingly cool.
↫ blinry
It shouldn’t come as a surprise, though, that a lot of graphical user interfaces don’t really have any affordances for multiple mouse pointers manipulating the same object (e.g. one cursor drags the window, another tries to close it), but the possibilities are really endless here. It’s not quite there yet to be considered fully-featured and plug-and-play, but it’s a lot more capable than I thought it would be.
The first thing that came to my mind is sitting down behind my computer with my kids to teach them the basics of using a GUI. Instead of having to pass the mouse back and forth, one of my kids (or both!) could have his own cursor, which is a lot more fun and collaborative. Games are obviously another great application for this sort of thing, especially things like classic board games.
I hope this gets some more attention.
Issue 47 – Greta’s Wedding Pt. 2 – 07 [Comics Archive - Spinnyverse]
The post Issue 47 – Greta’s Wedding Pt. 2 – 07 appeared first on Spinnyverse.
12:56
watervole @ 2026-07-29T11:29:00 [Judith Proctor's Journal]
We bank with Nationwide - they have no fossil fuel investments.
As a handy bonus, they're still a building society, so actually share some profit with their members.
With our joint account, we've gained £200 per anum for several years now :)
At present, they have bonus of £175 for people switching their current account to them.
It really is very easy to switch bank these days...
And then you'll know your money isn't being used to speed up the destruction of the natural world.
12:49
What the Hell Is a Loop, Anyway? [Radar]
The following article originally appeared on LinkedIn and is being republished here with the author’s permission.
We’re currently at the peak of the hype cycle. On June 7, Peter Steinberger posted that you shouldn’t be prompting coding agents anymore; you should be designing loops that prompt your agents. That same week, Boris Cherny of Anthropic said on stage that he doesn’t prompt Claude anymore: “I write loops; the loops do the work.” Addy Osmani published an essay called “Loop Engineering” on June 7, swyx published “Loopcraft: The Art of Stacking Loops” on June 12, and LangChain published “The Art of Loop Engineering” on June 16. Then came the AI Engineer World’s Fair, where the word dominated the main stage. Swyx’s keynote was about Loopcraft, an entire track was devoted to software factories, speaker after speaker reached for the same word, and the conference closed on July 2 with an hour-long debate about whether the hype behind loops has outrun what works in practice.
The problem is that the people talking about loops aren’t all discussing the same thing. I counted at least four distinct architectures hiding behind that one word. So this post is an attempt to map out what everyone means.
The execution loop: The agent’s own act-observe cycle
This is the loop most people picture when they say “agent”: call a tool, read the result, decide the next action, and repeat until there are no more tool calls to make. It’s what Addy calls the inner execution loop, the part agents can now run largely on their own, and it’s the innermost loop you can engineer. (swyx’s stack has a token loop, but nobody designs the token loop. It’s just part of the model.)
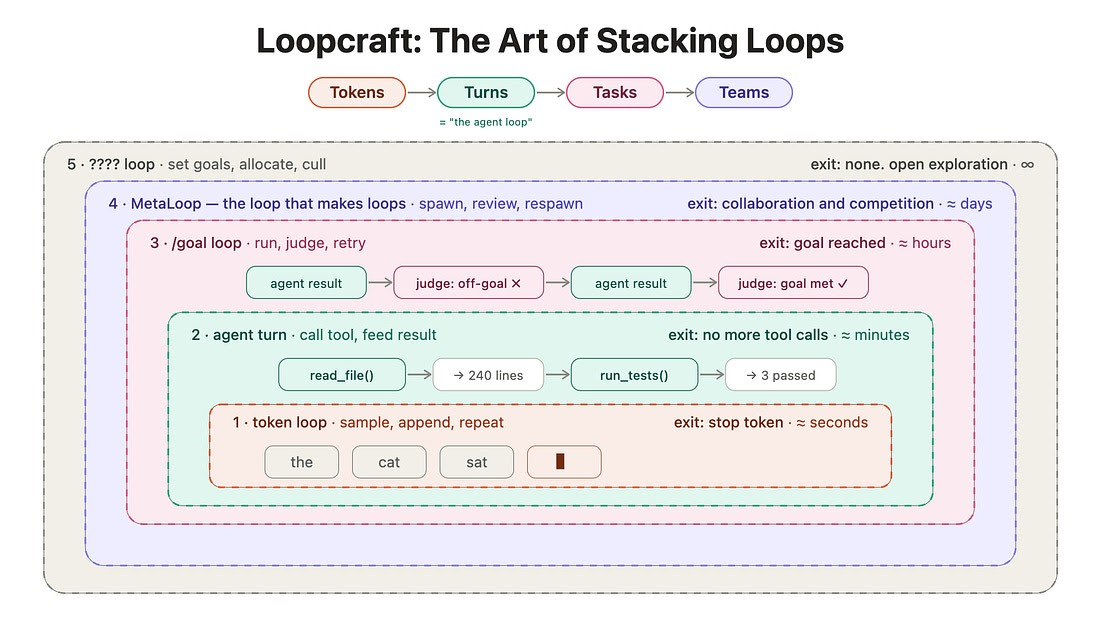 Swyx’s original Loopcraft diagram
Swyx’s original Loopcraft diagram
The execution loop iterates on steps within one task. It ends on environment feedback: the test output, the API response, and the file contents. Humans are usually absent mid-loop and appear at the boundaries, approving plans or reviewing results. The execution loop also ends whenever the agent decides it’s done, whether or not it actually is. The first fix the field found for that was to wrap this loop in another one that doesn’t take the agent’s word for it.
The task loop: Restart the agent until the spec is satisfied
This was the first loop to get a name and it’s Geoffrey Huntley’s Ralph loop, which got name-checked from the AI Engineer World’s Fair main stage when Allie Howe of Keycard introduced the software factories track by citing Geoffrey’s article “Everything Is a Ralph Loop.” A Ralph loop restarts a coding agent against the same specification over and over, allocating a completely fresh context window every iteration and doing exactly one task per loop. The apparent waste is the point: Refeeding the full spec each time prevents the context rot and compaction events that quietly degrade long-running sessions.
What this loop iterates on is a single artifact. What ends the loop is spec compliance and passing tests. The human writes the spec and judges doneness, and in Geoffrey’s telling the human has one more job that I’ll return to later: watching the loop, spotting failure patterns, and fixing them so they never recur. In the closing debate on the conference’s final day, he compared the role to a locomotive engineer, someone whose whole job is keeping the train on the rails. Zoom out from a single spec though, and a much bigger loop comes into view: the one that runs an entire codebase.
The product loop: The software factory
This was the loudest version at the AI Engineer World’s Fair. Tereza Tizkova of Factory defined a software factory as “the whole loop, the whole lifecycle of developing software with autonomy,” and Zach Lloyd of Warp got specific about what that lifecycle is in an interview with Latent Space: triage, specification, implementation, review, verification, shipping, and monitoring. Zach’s claim is that software engineering becomes factory engineering, and that you’ll be building the thing that builds the product. Warp is dogfooding this: The company placed its own open-sourced repo under the control of Oz, its factory platform. Zach describes the adoption path as starting with low-risk repos and ratcheting the automatic PR merge rate upward from 20 percent toward 60. Anthropic appears to be running the same experiment internally. The company says 65% of its product team’s code is now created by its internal version of Claude Tag, and Mike Krieger described his team’s use of it at the World’s Fair as delegated and proactive: not “fix this bug” but take responsibility for this part of the codebase, monitor this feedback channel, and pick up tasks on your own.
The task loop and the execution loop have defined exit conditions. The product loop iterates on a codebase and its backlog, continuously, and its closing signals come from outside the codebase entirely: new issues, production logs, user feedback, review outcomes. The human role becomes configurable. In Zach’s framing, you pick the parts of the lifecycle to automate and the points where humans get brought in, and organizations differ on questions like whether code review stays human for high-risk changes. A factory improves a product. The next loop improves the factory itself.
The system loop: Autoresearch
Roland Gavrilescu of Introspection calls this autoresearch. Here’s how he framed the concept in a Latent Space interview: The inner loop is your primary system doing user-facing work, and the outer loop studies and maintains the primary system. It iterates on prompts, harnesses, model choices, and the evals themselves. His one-liner is that the loop is the product.
This pattern now has real existence proofs at both ends of the scale. The minimal case is Andrej Karpathy’s autoresearch from March 2026, roughly 630 lines of Python that ran 50 hypothesis-edit-evaluate experiments overnight on one GPU. The shipped case is Meta’s Brain2Qwerty v2, announced in late June, where the researchers report that agents iteratively modified the codebase to invent better decoding architectures, producing a substantial improvement in word error rate. Meta’s caveat is instructive: Final training configurations were still selected by hand. Even the flagship system loop keeps a human at the last checkpoint.
What ends this loop is the most demanding signal set of the four: evals, judges, filtered product feedback, and, in Roland’s design, an explicit ask-a-human tool through which the agent accumulates tacit knowledge the way a new employee does. And that’s the top of the stack. Put the four together and the shape of the whole system becomes visible.
The four loops side by side
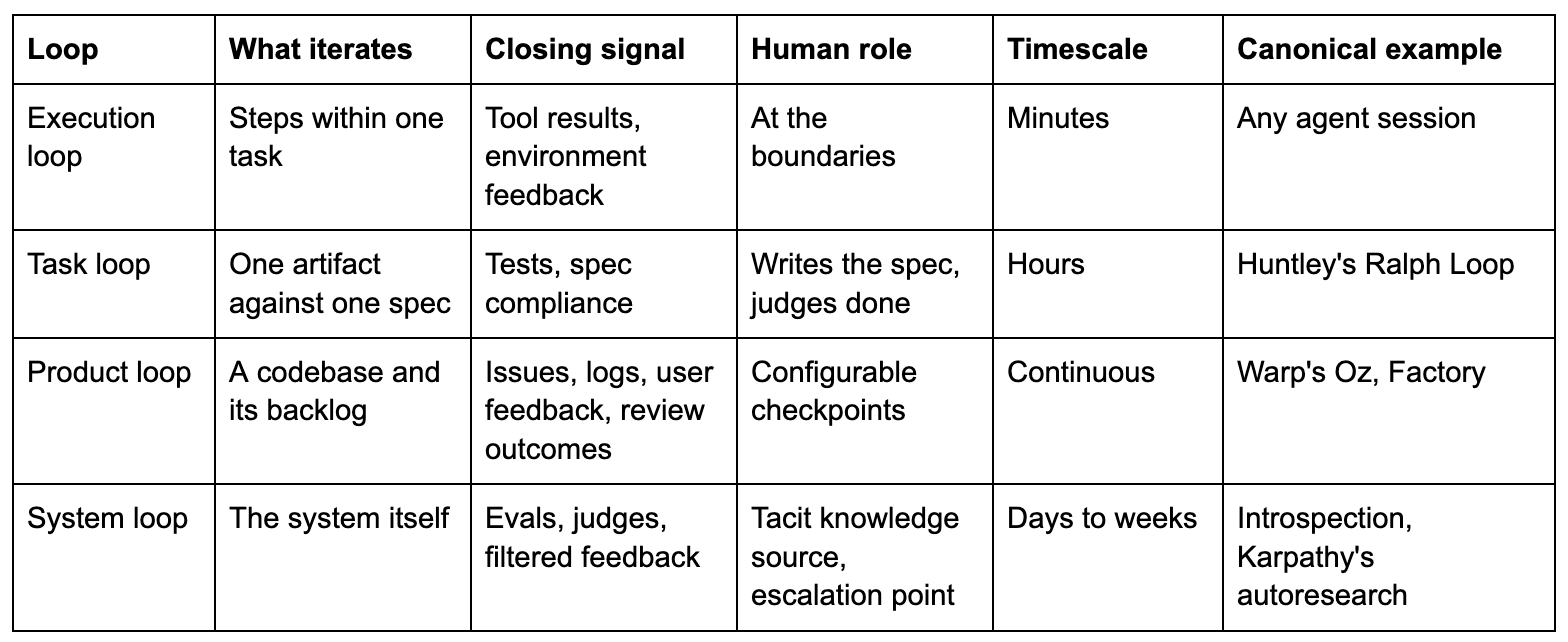
What about Agentic MapReduce?
One famous pattern from the same week is missing from this map on purpose. Cognition’s Devin Security Swarm fans parallel bounded agents out across a repository and aggregates their findings, a shape the company calls Agentic MapReduce, and it gets called a loop. I don’t think it is one. Dispatch, gather, validate is a pipeline: Nothing feeds back into a next cycle, and a loop without feedback is just a for statement. Fan-out is a topology you can deploy inside any of the four loops, not a loop of its own.
The unnamed loop at the top is the oversight loop
In swyx’s loop diagram, the outermost ring, the one above the loop that makes loops, is literally labeled “???? loop.” Its verbs are “set goals, allocate, cull.” Its exit condition is listed as none.
I think that loop has a name. I’m calling it the oversight loop: It’s where goals get set, budgets get allocated, and work gets culled, and it’s the one ring where a human should live. Addy said on the AIEWF stage: “That inner loop is capability. The outer loop is agency.” Agency is exactly what the oversight loop holds.
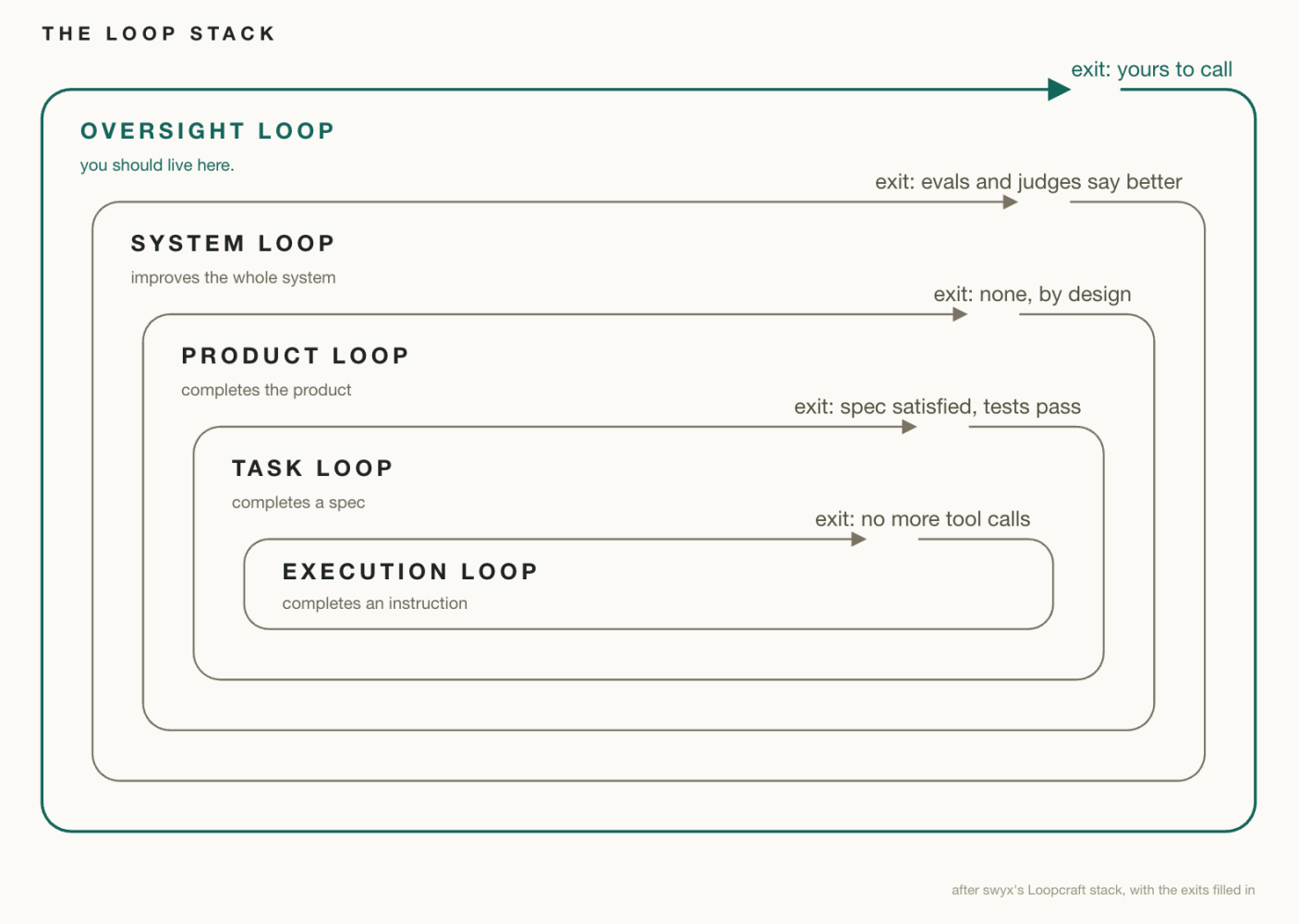 The loop stack, tidied up a bit.
The loop stack, tidied up a bit.
And the sharpest disagreements at AIEWF were all, once you translate them, arguments about who runs that top ring. Zach and Roland make the case for turning the dial up: pick your checkpoints deliberately, ratchet autonomy as trust accumulates, and, in Roland’s memorable distinction, build orchestras before factories, where an orchestra is a system that keeps a human conductor. The other camp says the dial has a stop. Geoffrey Litt of Notion called factories a depressing vision on X and argued, in a talk he has since published as an essay, that those who delegate understanding get replaced by the agent. Paul Bakaus put it as flatly as it can be put: “There is no auto, and there will be no auto.” His argument isn’t only about quality; it’s about ownership. People need purpose, and they want a role in what they create.
The closing debate, covered in Latent Space’s conference reporting, put both positions on one stage. Dex Horthy of HumanLayer took pains to say he isn’t anti-loop, pointing out that Kubernetes is built on control loops, but deterministic ones. His worry is that enthusiasm has gotten ahead of the engineering, and his advice was to step down an abstraction level rather than up. Geoffrey took the other side and called loops inevitable. And Mike offered the most honest data point of all: Even inside Anthropic, the team running Tag reports being bottlenecked on reviews and on the human ability to conceptualize what the system is doing. The checkpoint humans kept for themselves is now the constraint.
Autonomy is a dial that exists separately on every one of the four loops. You can run a fully autonomous execution loop inside a heavily supervised product loop. You can hand the system loop to agents while keeping goal-setting entirely human. The interesting engineering question isn’t “Which camp wins?”; it’s “What information do you need to set each dial correctly?”
The table above is my attempt to fill in those blanks. Every loop, including the top one, has a nameable exit condition, and the top one is you. But naming a signal isn’t the same as wiring it in. A loop without its signal doesn’t converge. It just runs until something external stops it. Knowing whether your loops are actually closing, at production scale, means sweeping traces and clustering failures continuously instead of spot-checking transcripts, which is exactly the job Arize AX was built to do.
Which one are you building?
Now the loops have names, that’s the question to ask. The word loop is doing a lot of work this month, because this field loves nothing more than jumping on the next hot thing. But real practice underlies all four loops, and it’s the same practice in each: people are dialing up their level of abstraction and pushing human judgment further up the stack. That’s the actual lesson of loops. We get more done by climbing up the stack, and now you have a map, you know where you should climb.
12:14
Long-Lived Vulnerability in Microsoft Secure Boot [Schneier on Security]
Microsoft’s Secure Boot has had a serious vulnerability for most of its existence.
An industry-wide standard Microsoft invented to protect Windows, and later Linux, devices from firmware infections has been trivial to bypass for 13 of its 14 years of existence. The discovery was made by researchers at security firm ESET after identifying 11 firmware images, at least one from 2013, that were known to be defective but remained signed by the software company anyway.
The images are known as shims, which were invented to extend Secure Boot to Linux devices and utility software. Using a technique simple enough to be performed by novice hackers, these old, forgotten shims can be used to completely circumvent the protection, which is embedded into the UEFI (Unified Extensible Firmware Interface) of the device’s motherboard. The gaffe is the result of the failure by Microsoft, which oversees the signing of shims, to revoke the publicly available images once vulnerabilities were found in them.
10:49
Eager to give up agency [Seth's Blog]
We work so hard to have freedom and leverage and choice.
And then, as soon as a social network, boss or cultural force instructs us to do something, we fold our tents and go along.
Responsibility is scary. Sometimes it’s easier to find someone (or something) to blame.
Just because AI tells you to put your finger in a pencil sharpener doesn’t mean you should, said every mother ever.
09:14
Pluralistic: Enshittification and Reverse Centaurs go global (29 Jul 2026) [Pluralistic: Daily links from Cory Doctorow]
->->->->->->->->->->->->->->->->->->->->->->->->->->->->->
Top Sources: None -->

Today's links
- Enshittification and Reverse Centaurs go global: The good globalism.
- Hey look at this: Delights to delectate.
- Object permanence: Fonz thumps x Linux; CBC v DRM; Aussie mall v photos; English town x CCTVs; Pay no taxes x Big Tech; Games Workshop v gamers; Delta x surveillance pricing.
- Upcoming appearances: Edinburgh, Sydney, Melbourne, Brighton, London, South Bend.
- Recent appearances: Where I've been.
- Latest books: You keep readin' em, I'll keep writin' 'em.
- Upcoming books: Like I said, I'll keep writin' 'em.
- Colophon: All the rest.

Enshittification and Reverse Centaurs go global (permalink)
It's safe to say that the past couple of years have been good ones for me publishing-wise, thanks to a string of international bestsellers, both novels (Picks and Shovels) and nonfiction (Enshittification, Reverse Centaur), as well as plenty of awards and accolades:
Over the past two months, I've won the Locus Award (Enshittification), had a NYT bestseller (Reverse Centaur), gotten a word in the OED ("enshittification"), and had the number one bestselling nonfiction paperback in Canada for more than a month running (Reverse Centaur). I also turned 55 – and my radiologist told me I'm now cancer-free, so it's been a good summer all around.
These books have done especially well internationally because they deal with technopolitics, which means that my readers are disproportionately Internet People, and for historical reasons, these are folks who are more likely to speak English, even if they live outside of the Anglosphere.
This post is primarily for those readers, who often write to me to let me know how much they enjoyed the books, so much so that they'd like to share them with their less online, less English-conversant friends, and want to know whether there is a translation coming in their own language.
Good news! Both Reverse Centaur and Enshittification have many foreign editions that are either published or forthcoming in the next year or so. The foreign rights team at Farrar, Straus and Giroux were good enough to prepare a list of all these editions, which I'm about to reproduce below.
If your preferred language isn't on the list, I apologize. Translation deals are primarily "pull," not "push" – that is to say, a foreign publisher contacts my publisher and asks for the rights (though my publisher does market the rights and attends all the book fairs where these deals are often made).
The upshot here is that I am not really in a position to do more than has already been done to get an edition published in your preferred language or territory. If you happen to have a favorite local publisher, you could always ask them if they would like to get in touch with Farrar, Straus and Giroux foreign rights team to secure a license.
I also need to note here that these deals are generally with established publishers who have relationships with national booksellers and distributors (rather than enthusiastic individuals who want to produce a translation and see if they can get it read by other people in their country). The hard part of publishing isn't the translation, the typesetting, the book design or even the writing – the hard part is connecting a text with its readers:
https://pluralistic.net/2021/07/04/self-publishing/
With that all said, here's the master list of editions of Enshittification and The Reverse Centaur's Guide to Life After AI:
- USA
 and Canada
and Canada  : Farrar, Straus and Giroux
: Farrar, Straus and Giroux
Enshittification: hardcover, Oct 2025; paperback, Sep 2026
https://us.macmillan.com/books/9780374619329/enshittification/
Reverse Centaur: paperback, Jun 2026
https://us.macmillan.com/books/9780374621568/thereversecentaursguidetolifeafterai/
- UK
 and Commonwealth excluding Canada (Australia
and Commonwealth excluding Canada (Australia
 , New Zealand
, New Zealand  , India
, India  , South Africa
, South Africa  , and beyond): Verso Books
, and beyond): Verso Books
Enshittification: hardcover, Oct 2025; paperback, Sep 2026
https://www.versobooks.com/en-gb/products/3341-enshittification
Reverse Centaur: hardcover, Jun 2026
https://www.versobooks.com/en-gb/products/3584-the-reverse-centaur-s-guide-to-life-after-ai
- Brazil
 : Grupo Editorial Record
: Grupo Editorial Record
Enshittification, early 2027 -
France
 : Éditions Eyrolles
: Éditions Eyrolles
Enshittification: Feb 2027 -
Germany
 : Aufbau
: Aufbau
Enshittification: May 2026
https://www.aufbau-verlage.de/blumenbar/enshittification/978-3-351-05143-3 -
Hungary
 : Agave Konyvek
: Agave Konyvek
Enshittification (as A Nagy Elszaródás/The Big Mess), Mar 2026
https://agavekonyvek.hu/konyv/ismeretterjeszto-190/a-nagy-elszarodas-miert-romlott-el-hirtelen-minden-es-mit-tehetunk-ellene
Reverse Centaur (as A Nagy Összemolás/The Big Collapse), not yet scheduled
- Italy
 : Iperborea
: Iperborea
Enshittification, not yet scheduled -
Japan
 : Impress Corporation
: Impress Corporation
Enshittification, Jan 2027 -
Poland
 : Wydawnictwo Otwarte
: Wydawnictwo Otwarte
Enshittification (as Gównowacenie), Aug 2026
https://www.znak.com.pl/p/gownowacenie-jak-cyfrowi-giganci-zmieniaja-nasz-swiat-na-gorsze-cory-doctorow-488999?abpid=10388&abpcid=33&bb_coid=231428551&bbclid=cc5f0f24-aa55-4997-95ec-cefead709239 -
Portugal
 : PRH Portugal
: PRH Portugal
Enshittification, not yet scheduled -
Quebec
 :
Éditions Québec Amérique
:
Éditions Québec Amérique
Enshittification: Apr 2027 -
Slovenia
 : Mladinska Knjiga
: Mladinska Knjiga
Enshittification, not yet scheduled -
South Korea
 : Next Wave Media
: Next Wave Media
Enshittification, Jul 2026
https://product.kyobobook.co.kr/detail/S000220350700 -
Spain
 : Capitán Swing
: Capitán Swing
Enshittification (as Mierdificación), Mar 2026
Reverse Centaur, not yet scheduled
- Taiwan
 : Acropolis
: Acropolis
Enshittification, first quarter 2027 -
Thailand
 : Salt Publishing
: Salt Publishing
Enshittification, Oct 2026 -
Türkiye
 : Okuyanus
: Okuyanus
Enshittification, Fall 2026 -
Ukraine
 : Athena Publishing
: Athena Publishing
Enshittification, not yet scheduled
(These are the confirmed deals. There are lots of other deals in negotiation, especially for Reverse Centaur, which is only a month old.)
I hope some of you found this useful! If not (or if so!), don't worry, I'll be back with more essays in the days to come.
One final note for newsletter readers: I realize that I have violated my "one emoji per edition" rule with the flags above. Rest assured this will not be a regular thing.
Hey look at this (permalink)
- We used to be able to buy things in this country https://dannykatch.substack.com/p/we-used-to-be-able-to-buy-things
-
How to Stop the Enshittification of America https://www.thebignewsletter.com/p/monopoly-round-up-how-to-stop-the
-
Yes, Trump Will Attempt a Coup https://prospect.org/2026/07/28/trump-attempt-coup-january-6-election-republican-congress/
-
Framework Laptop 13 Pro Review: The Best Modular Laptop Ever Made https://gizmodo.com/framework-laptop-13-pro-review-the-best-modular-laptop-ever-made-2000791804
-
The $145 Billion Lie? Zuckerberg's Leaked Town Hall Audio Exposes Massive AI Failures After Mass Layoffs https://www.ibtimes.co.uk/zuckerbergs-leaked-audio-meta-ai-struggles-1807607
Object permanence (permalink)
#20yrsago Linux Thinkpads can be controlled by knocking on them https://web.archive.org/web/20060814065844/http://www-128.ibm.com/developerworks/linux/library/l-knockage.html?ca=dgr-lnxw01Knock-Knock
#20yrsago Why the CBC doesn’t need DRM https://web.archive.org/web/20060820121451/https://www.michaelgeist.ca/component/option,com_content/task,view/id,1342/Itemid,85/nsub,/
#20yrsago Aussie mall defends its photons from terrorists https://web.archive.org/web/20060910224208/http://www.theage.com.au/articles/2006/07/29/1153816426869.html
#15yrsago Sleepy English town to be entirely surveilled in case criminals forget and drive through it on their way to crimes https://web.archive.org/web/20110731020858/https://www.telegraph.co.uk/motoring/news/8670642/Sleepy-market-town-surrounded-by-ring-of-car-cameras.html
#10yrsago Lessons from the DNC: Ronald Reagan, the Southern Strategy, and “abnormal politics” https://crookedtimber.org/2016/07/30/philadelphia-stories-from-reagan-to-trump-to-the-dnc/
#10yrsago How to pay no taxes at all! (if you’re Apple, Google or Facebook) https://www.nakedcapitalism.com/2016/07/video-guide-to-legal-tax-evasion-with-an-apple-boycott.html
#5yrsago Games Workshop declares war on its customers https://pluralistic.net/2021/07/30/space-marines/#fairy-use-tale
#1yrago Delta's AI-based price-gouging https://pluralistic.net/2025/07/30/efficiency-washing/#medallion-clubbed
Upcoming appearances (permalink)
- Virtual: EFFecting Change: Who the Machine Serves, Aug 12
https://www.eff.org/event/effecting-change-who-machine-serves -
Edinburgh International Book Festival with Jimmy Wales, Aug 17
https://www.edbookfest.co.uk/events/the-front-list-cory-doctorow-and-jimmy-wales -
Sydney: The Festival of Dangerous Ideas, Aug 23-24
https://festivalofdangerousideas.com/program/ -
Melbourne: Enshittification at the Wheeler Centre, Aug 25
https://www.wheelercentre.com/events-tickets/season-2026/cory-doctorow-enshittification -
Brighton: The Reverse Centaur's Guide to Life After AI with Carole Cadwalladr (Brighton Dome), Sep 8
https://brightondome.org/whats-on/LSC-cory-doctorow-the-reverse-centaurs-guide-to-life-after-ai/ -
London: The Reverse Centaur's Guide to Life After AI with Riley Quinn (Foyle's Picadilly), Sep 9
https://www.foyles.co.uk/events/enshittification-cory-doctorow-riley-quinn -
South Bend: An Evening With Cory Doctorow (Notre Dame), Oct 6
https://franco.nd.edu/events/2026/10/06/an-evening-with-cory-doctorow/
Recent appearances (permalink)
- AI is not inevitable (Betakit)
https://www.youtube.com/watch?v=DbiTVkq1WHo -
A Conversation with Lina Khan (Law and Economy Student Network)
https://www.youtube.com/live/7Ak5LZllqwE -
Will AI ever come alive, and what happens if it does? (BBC News)
https://www.youtube.com/watch?v=Lzk4o3fPZZE -
Waarom jij straks het hulpje van AI bent (VPRO)
https://www.youtube.com/watch?v=tOnvR2fs8CA -
Talk Tech Bock (Vera Linß)
https://www.youtube.com/watch?v=3PFjGvQoBgc
Latest books (permalink)
- "The Reverse-Centaur's Guide to AI," a short book about being a
better AI critic, Farrar, Straus and Giroux, June 2026
https://us.macmillan.com/books/9780374621568/thereversecentaursguidetolifeafterai/ -
"Canny Valley": A limited edition collection of the collages I create for Pluralistic, self-published, September 2025 https://pluralistic.net/2025/09/04/illustrious/#chairman-bruce
-
"Enshittification: Why Everything Suddenly Got Worse and What to Do About It," Farrar, Straus, Giroux, October 7 2025
https://us.macmillan.com/books/9780374619329/enshittification/ -
"Picks and Shovels": a sequel to "Red Team Blues," about the heroic era of the PC, Tor Books (US), Head of Zeus (UK), February 2025 (https://us.macmillan.com/books/9781250865908/picksandshovels).
-
"The Bezzle": a sequel to "Red Team Blues," about prison-tech and other grifts, Tor Books (US), Head of Zeus (UK), February 2024 (thebezzle.org).
-
"The Lost Cause:" a solarpunk novel of hope in the climate emergency, Tor Books (US), Head of Zeus (UK), November 2023 (http://lost-cause.org).
-
"The Internet Con": A nonfiction book about interoperability and Big Tech (Verso) September 2023 (http://seizethemeansofcomputation.org). Signed copies at Book Soup (https://www.booksoup.com/book/9781804291245).
-
"Red Team Blues": "A grabby, compulsive thriller that will leave you knowing more about how the world works than you did before." Tor Books http://redteamblues.com.
-
"Chokepoint Capitalism: How to Beat Big Tech, Tame Big Content, and Get Artists Paid, with Rebecca Giblin", on how to unrig the markets for creative labor, Beacon Press/Scribe 2022 https://chokepointcapitalism.com
Upcoming books (permalink)
- "The Post-American Internet," a geopolitical sequel of sorts to Enshittification, Farrar, Straus and Giroux, 2027
-
"Unauthorized Bread": a middle-grades graphic novel adapted from my novella about refugees, toasters and DRM, FirstSecond, April 20, 2027
-
"Enshittification, Why Everything Suddenly Got Worse and What to Do About It" (the graphic novel), Firstsecond, 2027
-
"The Memex Method," Farrar, Straus, Giroux, 2027
Colophon (permalink)
Today's top sources:
Currently writing: "The Post-American Internet," a sequel to "Enshittification," about the better world the rest of us get to have now that Trump has torched America. Fourth draft completed. Submitted to editor.
- A Little Brother short story about DIY insulin PLANNING
This work – excluding any serialized fiction – is licensed under a Creative Commons Attribution 4.0 license. That means you can use it any way you like, including commercially, provided that you attribute it to me, Cory Doctorow, and include a link to pluralistic.net.
https://creativecommons.org/licenses/by/4.0/
Quotations and images are not included in this license; they are included either under a limitation or exception to copyright, or on the basis of a separate license. Please exercise caution.
How to get Pluralistic:
Blog (no ads, tracking, or data-collection):
Newsletter (no ads, tracking, or data-collection):
https://pluralistic.net/plura-list
Mastodon (no ads, tracking, or data-collection):
Bluesky (no ads, possible tracking and data-collection):
https://bsky.app/profile/doctorow.pluralistic.net
Medium (no ads, paywalled):
Tumblr (mass-scale, unrestricted, third-party surveillance and advertising):
https://mostlysignssomeportents.tumblr.com/tagged/pluralistic
"When life gives you SARS, you make sarsaparilla" -Joey "Accordion Guy" DeVilla
READ CAREFULLY: By reading this, you agree, on behalf of your employer, to release me from all obligations and waivers arising from any and all NON-NEGOTIATED agreements, licenses, terms-of-service, shrinkwrap, clickwrap, browsewrap, confidentiality, non-disclosure, non-compete and acceptable use policies ("BOGUS AGREEMENTS") that I have entered into with your employer, its partners, licensors, agents and assigns, in perpetuity, without prejudice to my ongoing rights and privileges. You further represent that you have the authority to release me from any BOGUS AGREEMENTS on behalf of your employer.
ISSN: 3066-764X
09:07
New Comic: Cyberbullies
08:42
Girl Genius for Wednesday, July 29, 2026 [Girl Genius]
The Girl Genius comic for Wednesday, July 29, 2026 has been posted.
06:00
Making an agile version of a Windows Runtime delegate in C++/WinRT, part 7 [The Old New Thing]
Last time, we
fixed the problem of creating a unique_ptr whose
deleter’s constructor was might throw an exception. But
we’re not out of the woods yet.
Let’s take another look at what we have:
if (d.try_as<::INoMarshal>()) {
void* p;
if constexpr (std::is_reference_v<Delegate>) {
p = winrt::detach_abi(d);
} else {
winrt::copy_to_abi(d, p);
}
return
[p = std::unique_ptr<void, in_context_deleter>(p, {}),
token = get_context_token()](auto&&...args) {
if (token == get_context_token()) {
std::remove_reference_t<Delegate> d;
winrt::copy_from_abi(d, p.get());
d(std::forward<decltype(args)>(args)...);
} else {
throw winrt::hresult_error(CO_E_NOT_SUPPORTED);
}
};
}
We had originally broken the rule that the
unique_ptr(p) constructor requires that the
deleter’s default constructor not throw an exception. We
fixed it by constructing the deleter explicitly as a parameter, so
that the unique_ptr constructor can move it into the
stored deleter without an exception.
But wait, if an exception occurs in construction of the
in_context_deleter, the raw pointer we created in the
previous block will be leaked. It owns a reference count but
doesn’t clean up in the case of an exception.
We can fix this by creating the deleter first.
if (d.try_as<::INoMarshal>()) {
in_context_deleter del;
void* p;
if constexpr (std::is_reference_v<Delegate>) {
p = winrt::detach_abi(d);
} else {
winrt::copy_to_abi(d, p);
}
return
[p = std::unique_ptr<void, in_context_deleter>(p, std::move(del)),
token = get_context_token()](auto&&...args) {
if (token == get_context_token()) {
std::remove_reference_t<Delegate> d;
winrt::copy_from_abi(d, p.get());
d(std::forward<decltype(args)>(args)...);
} else {
throw winrt::hresult_error(CO_E_NOT_SUPPORTED);
}
};
}
If there is an exception constructing the custom deleter, it happens before we initialze the raw pointer, so there is no leak of the reference owned by that raw pointer.
Okay, so are we done now?
Nope.
More next time.
The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 7 appeared first on The Old New Thing.
04:28
Russ Allbery: Review: Midlife in Gretna Green [Planet Debian]
Review: Midlife in Gretna Green, by Linzi Day
| Series: | Midlife Recorder #1 |
| Publisher: | Linzi Day |
| Copyright: | July 2022 |
| ISBN: | 9798837010774 |
| Format: | Kindle |
| Pages: | 464 |
Midlife in Gretna Green is a self-published fantasy novel. It's urban fantasy in the sense that it's set in our world but with magic that most people don't know about, but the primary setting is a parish in rural Scotland and therefore the genre is not urban in that sense. It was Linzi Day's published first novel.
As the story opens, Niki McKnight is a widow in Manchester, England with a job in the Register Office she likes, a boss she hates, and a Bichon Frise dog she adores. In the year since her husband Nick died, she's put her life on hold and made as few decisions as possible, despite some concerned pushing from her best friend Aysha. The death of her grandmother is not entirely unexpected, but her inheritance is about to upend her life.
Niki assumes that her grandmother has a modest cottage and a small estate, and therefore being the named heir will mostly involve cleaning up the details of a modest life. She is caught by surprise by a requirement in the will that she live in Gretna Green for a year and a day in order to inherit. Her initial reaction is to treat this as an absurd impossibility given her life and job in Manchester, but she slowly realizes something strange is going on. Her grandmother's lawyer is lying to her, he refuses to tell her the value of the estate and seems to think it's more valuable than she expected, and her grandmother's tiny cottage does not seem to be following the seasons of the rest of the world. There is something magical at work.
I will not spoil the rest of the reveal. I will say that this is a magical house book because, if you are anything like me, that is why you will want to read this series. There are not enough magical house books, and this is one of the better kind that allow the house to be a full speaking character.
Midlife in Gretna Green is an unapologetic fantasy of personal agency. Niki starts the novel with a miserable manager, a messy pile of unread mail she doesn't want to deal with, and a lot of personal emotional baggage. She gets handed a position that requires and rewards standing up for herself and being decisive. It comes with a pile of unresolved but not horribly complex problems that were waiting for someone who would listen, make sensible decisions, and treat other people with respect. Oh, and there are a few assholes in the way, but they seriously underestimate the power she has to put a stop to their bullshit.
This is the sort of book that traditional publishers tended not to buy (although Day apparently did get an offer for this one and turned it down), and I'm not sure why. Editors thought protagonists should have to work harder for their payoff? Some lingering Calvinist dourness in English language publishing mistrusted triumphant books? Obvious wish fulfillment was considered embarrassing or low-class and thus didn't warrant publication? This didn't apply to the endless bildungsromans about magically talented boys, so some level of sexism was probably in play. Maybe this is finally changing? It reminds me of the bias against romance novels and their guaranteed happily ever after, and in the case of romance there was too much money for publishers to leave it on the table.
In any case, the growth of self-publishing has created an alternative market that let these books reach an audience and I for one am here for it. A lot of wish-fulfillment books, and a lot of self-published books, are not very good, but the ones that have a spark of originality and character can be a delight worth tolerating the somewhat rocky editing and pacing problems that a full editorial staff might have cleaned up.
I loved reading books about kickass women who took no crap and fixed their lives up exactly how they wanted them to be. But how did they get to be that way? They always started out awesome in the books. Seriously, did they kick ass at sixteen? Or did their superpower kickassery not kick in until they were thirty? Forty? If so, then I was screwed. Would I need to wait till I was fifty or until a genie arrived offering wishes? I already felt as if I’d spent my whole life waiting for something wild and wonderful to happen.
Niki is a Specific Type to a somewhat hilarious degree, and I'm not sure if Day is playing into that intentionally or if she's projecting herself into the book. The amount of self-insertion is not zero: Day also lives in Gretna Green, owns a Bichon Frise, and worked as an assistant registrar and civil celebrant. Niki also drinks wine regularly, has a psychic gift, occasionally reads tarot cards, is an accommodating pushover at work who struggles to say no to her abusive boss, has impostor syndrome problems, and swears by a fictional self-help book about grief that provides the quotes at the starts of chapters. There is a cat, because of course there's a cat.
(The fictional self-help book is a spot-on parody played entirely straight in the story. I think Day is having some fun with the reader? I can't tell!)
This is what I mean by unapologetic. It's easy to read Niki as a stereotype, but she's a stereotype a lot of real people can identify with and there's something highly satisfying in watching her find her footing. I like wish fulfillment books; it's fun to see someone's wishes come true! Particularly in the year of 2026, there's something immensely satisfying in seeing an ordinary, insecure person get a massive amount of power and use it to make the world better. I don't need everything to be hard, fraught, and laden with costs in fiction, although I wouldn't want every book I read to be like this.
Also, the world building is great. It's not polished; there's a bit of a grab bag feeling to it, I'm dubious the magic system has any underlying rigorous rule set, and Niki's powers, once she has access to them, are more of a semi-sentient genie than a skill she has to learn with hard practice. But the magic is fun. The sentient house is one of the best characters, particularly after Niki realizes how underused it has been, and I am a sucker for any good sentient house book. The cat is a far more interesting character than I first thought she would be. And Niki's new magical job is more complicated and less typical than the normal Celtic-inspired fantasy that I thought it was going to be at first.
My primary warning about this book is that Niki starts out beaten down and grieving her dead husband, and it took me about five pages to decide that her dead husband was a complete piece of shit who was not worth any of the grief Niki puts into him. She also doesn't stand up for herself for the first hundred pages or so, which made me want to yell at the book a few times. Both of these problems go away farther into the book, and Niki does eventually figure out that Nick was abusive trash, but I was relieved when the "make endless excuses for worthless men" portion of the story was finally over. You have to stick with it until Niki gets brave enough to try being the protagonist; once that happens, it becomes great fun.
It is fairly obvious that Midlife in Gretna Green was self-published, and I wish it had gotten the editing that it deserved. My copy had a couple of obvious formatting errors, the plot veers about more than was strictly necessary, and I think a careful editing pass could have tightened the writing by about fifty pages or so without losing any important detail. If that sort of thing bothers you, make sure you're in self-published fiction mode before starting this one. But it also has that irrepressible, bubbling-with-ideas feeling of a book where nothing has suppressed the author's enthusiasm. It's a very grabby book; once Niki starts embracing her new life, I could barely put it down.
If you're in the mood for a good fantasy wish-fulfillment story that has no romance and a whole lot of "why are things run this way, no, we're changing that," highly recommended. I had so much fun with this book, and the series is currently making the rounds of my whole family. Don't read this when you're looking for something challenging and literary and deep; save it for when you desperately want to watch someone just fix something for once, damn it.
Followed by Painting the Blues in Gretna Green, which I have already read, breaking my usual rule of writing reviews before reading the next book in a series.
Rating: 8 out of 10
03:14
Measuring LLMs’ Ability to Perform Cryptanalysis [Schneier on Security]
There’s new benchmark measuring AI’s ability to perform mathematical cryptanalysis. Anthropic’s frontier model actually found new attacks.
The benchmark: “CryptanalysisBench: Can LLMs do Cryptanalysis?” The idea is to benchmark the ability of LLMs to discover new mathematical cryptanalytic attacks against a series of historical algorithms.
Abstract: Cryptanalysis—the task of finding attacks against cryptographic schemes—its at the intersection of mathematical reasoning and cybersecurity, two areas where LLMs have advanced fastest. Cryptanalysis represents both a clean testbed for frontier reasoning (as practical attacks can be automatically verified) and a domain with unusually high stakes, since the primitives under study underpin our digital security. In this paper we ask whether LLMs can do cryptanalysis, and find that the answer is increasingly yes. We introduce CryptanalysisBench, 191 tasks across six families of cryptographic primitives (block ciphers, hash functions, etc.) drawn primarily from four NIST standardization competitions. Our benchmark consists of three tiers: (i) primitives with known practical breaks; (ii) primitives with no known practical break, evaluated both at full strength and as scaled-down variants; and (iii) a challenge set of production primitives at the frontier of cryptanalysis. Five frontier models (Claude Opus 4.8, Sonnet 5, Mythos 5, GPT-5.5, and the open-weights GLM-5.2) break 65%86% of Tier 1 schemes, 612 Tier-2 schemes at full strength, and 2461 across all scaled-down variants. Beyond deriving known results, models produce novel cryptanalysis, such as a key-recovery attack that exploits a design flaw in the SpoC AEAD and an error in KINDI’s published CCA-security proof, both to the best of our knowledge not previously known.
We release CryptanalysisBench as a tool to help track if (or when) AI cryptanalysis becomes a serious factor and as a scaffold for stress-testing candidate schemes before deployment. The attacks that the benchmark already surfaces are an early snapshot of a fast-moving frontier that may soon match, and in places exceed, the published state of the art.
Anthropic used the benchmark to test Mythos Preview, and found new vulnerabilities in Hawk and reduced-round AES.
Still early results, but this is definitely something to watch.
SlashDot thread.
02:07

yesssss
Tuesday, 28 July
23:00
San Francisco: Don’t Fall for Industry Defense of Surveillance Pricing [Deeplinks]
The concept of “surveillance pricing” is just one part of a much larger problem and business model: corporations maximizing their profits by invading our privacy. The all-too-common business model is to systematically harvest, collate, and store as much of our personal data as possible, and then monetize it through use and sale. When it comes to surveillance pricing, that looks like corporations offering the same product to two different people at two different prices, based on harvested personal information. That's why EFF supports A.B. 2654, authored by Assemblymember Chris Ward, which bans this harmful practice.
As an organization based in San Francisco, EFF was proud to learn that the San Francisco Board of Supervisors had also introduced a resolution to similarly support the legislation. However, we were disappointed to learn the San Francisco Board of Supervisors has since stalled a vote on the resolution stating their own support for A.B. 2654 after receiving an email from the San Francisco Chamber of Commerce criticizing the bill using well-worn and debunked concerns. We’ve sent the Supervisors a letter asking them to reconsider.
Banning surveillance pricing would be good for consumers. The FTC has found that companies will set higher prices based on personal information. “For instance,” the FTC found last year, “if a consumer is profiled as a new parent, the consumer may intentionally be shown higher-priced baby thermometers on the first page of their in-app search results, based on their residential zip code and time of purchase.” Let's say that again: the U.S. government has found that companies may seek to use surveillance pricing to charge parents searching for a thermometer in the middle of the night more money in a time of need.
Privacy is a human right, not something that people should understand as a currency to give away or protect based on how it will impact the price of groceries. EFF has long opposed pay-for-privacy schemes, in which a company charges a higher price to a customer who refuses to submit to processing of their personal data. Surveillance pricing is another version of that practice. You should never have to worry that your privacy rights depend on how much you make.
At a time when prices for everyday goods continue to climb, some surveillance pricing defenders note that using personal information could lead to lower prices for some consumers. Yet some recent studies indicate there will be losers and winners based on factors such as whether a consumer is willing or able to switch products. Who loses or wins also will turn on the accuracy of the underlying data – yet surveillance pricing is often based on false information.
That said, even if surveillance pricing has the capability to lead to lower prices (which it often doesn't) we oppose it as just another way that corporations try to make customers pay for their privacy.
The San Francisco Chamber of Commerce’s concerns are fully addressed in the text of A.B. 2654. The Chamber raises questions about how businesses will comply with the law. But the bill is quite clear: “a retailer shall not engage in surveillance pricing.” It also has a clear definition of what “surveillance pricing” is. The banned practice is defined as: “[i] a customized price for a good for a specific consumer or group of consumers, [ii] based, in whole or in part, on personally identifiable information collected through electronic surveillance,” including if that information is “acquired from a third party.” In other words, “surveillance pricing” is a customized price based on personal information.
The SF Chamber’s letter also asks about the bill's “treatment of discounts and loyalty programs.” In this way, too, A.B. 2654 is quite clear. The bill includes three broad carveouts that ensure it doesn't disrupt loyalty programs and discounts:
- First, for price differences “based solely on costs associated with providing the good to different consumers.”
- Second, for a discount offered to a consumer who is taking steps to terminate a service.
- Third, for a discount, conspicuously posted on a retailer’s website, that is uniformly available based on (1) criteria anyone can meet, such as signing up for a mailing list, (2) membership in a broadly defined group, such as seniors, or (3) participation in a loyalty program.
An opt-in senior discount to the movies is not the problem. The systematic collection of all of our personal information to determine whether someone is a senior and if so whether they should pay more or less for that matinee is.
As we said in our blog post outlining our support for this bill:
Surveillance pricing is very similar to online behavioral advertising, a business practice that EFF urges governments to ban. Both practices incentivize all businesses to collect as much of our personal data as possible, in order to later monetize it. Both practices lead some businesses to collate and store our data into dossiers about us for later use. Both practices use these surveillance-based dossiers to manipulate and limit our economic choices, by altering the advertisements and prices we see online.
We urge the San Francisco Board of Supervisors to join the coalition of groups that support A.B. 2564, and stand against companies mining our personal information to charge us different prices for the same thing.
You can read our letter to the Supervisors here.
22:07
Learn email self-defense: Hands-on GPG with GNU/Linux with Greg Farough and Heshan de Silva-Weeramuni [Planet GNU]
August 14, 2026 at 17:30 EDT.
Evaluating a program’s free software licensing with Craig Topham [Planet GNU]
August 15, 2026 at 20:15 EDT.
Too many eyeballs? Free software security in the LLM era with Sean O'Brien [Planet GNU]
August 8, 2026 at 16:30 EDT.
Can we route around the app stores? With Sean O'Brien [Planet GNU]
August 16, 2026 at 16:00 EDT.
Reverse engineering binary blobs on mobile with Rob Savoye [Planet GNU]
August 6, 2026 at 14:00 PDT.
21:49
How to fight DDoS attacks from the command line with Michael McMahon [Events]
August 14, 2026 at 19:00 EDT.
19:07
[$] Progress toward compiling Linux with gccrs [LWN.net]
The gccrs project, which is creating a Rust frontend for the GCC compiler, has spent the first half of 2026 focusing on compiling the Linux kernel. By testing the compiler against the kernel crates, the development team has made significant progress toward generating correct code for other Rust programs. As detailed in the project's weekly and monthly reports, this effort has uncovered and resolved problems in areas such as attribute handling (described in the report for February), name resolution, and resource management (both detailed in the May report). Currently, the compiler can only handle simple standalone programs, but that situation could change rapidly in the coming months.
17:35
Why Are Gay Bars Building Databases of Their Patrons? [Deeplinks]
Recent reports have raised alarm about the use of PatronScan, an ID-checking and face-scanning system, at multiple LGBTQ+ bars in San Francisco’s Castro neighborhood. Much of the attention has focused on reports that the system photographs patrons as they enter venues and questions about whether those images are used for facial recognition.
A broader privacy concern also deserves scrutiny. For years, PatronScan has marketed itself not just as an ID-verification tool, but as a system that allows bars and clubs to identify patrons, keep records about them, and share information across venues. As one news article published in 2019 documented, PatronScan built a network that allowed participating bars to flag patrons and share information about them with other establishments.
And in California, it’s not at all clear how PatronScan’s business model of scanning IDs and sharing the information from those scans with other bars comports with the law. California’s ID privacy law, which was amended in 2018 to add ID “scans,” states that no businesses shall “retain or use” any information from a scanned ID card except for limited purposes such as to verify age, comply with a legal requirement, or prevent fraud.
A venue cannot claim to be a safe space while feeding its patrons’ data to a third party database.
Californians should be deeply concerned about businesses that collect information from government-issued IDs and use it to build databases about where people go, whom they associate with, and whether they should be allowed into other public gathering places. That concern is especially strong in LGBTQ+ spaces, which have long served as refuges for people to go without being tracked, monitored, or put on lists.
We reached out to Patronscan with questions regarding their practices and their views on California ID law. They referred us to their published FAQ question “Is Patronscan privacy compliant in California?” which claims that the use of Patronscan kiosks is legal in California. They also said “Patronscan does not do facial recognition in North America, or any kind of automated analysis of the ID or the live photo image.”
The California Legislature Has Investigated PatronScan’s Business Model
In 2018, the California Legislature published bill analyses (on that year's AB 2769) that went into detail about PatronScan’s business. Reviewing PatronScan's own materials, the California Senate Judiciary Committee found that the company had collected and retained information on 561,087 customers in Sacramento alone during the first five months of 2018—a remarkable figure for a city whose population had only recently topped 500,000.
Lawmakers also found that at that time, PatronScan retained information for at least 90 days or longer in some cases, shared information among participating bars, and maintained bans that lasted an average of more than 19 years. A PatronScan “Public Safety Report” used 10,000 scans collected on a single day to report on “where customers live, how far they have traveled, and how many different venues the customers patronized.”
This was not simply checking IDs at the door. PatronScan was building a database.
An immigrants’ rights group, the Coalition for Human Immigrant Rights (CHIRLA), wrote about its concern at the time with these growing ID databases, saying that “placing individuals on a database that labels them a "threat to public safety" has “significant immigration consequences that could lead to deportation, revoking of current status, or denial of future immigration relief.”
Today, Patronscan states that it retains personal information about all customers for 21 days, and about flagged customers for up to five years. This includes the customer’s name, date of birth, photograph, gender, and zip code. It also includes the dates and times that the customer entered particular bars. Such databases are a grave privacy threat. Personal data is routinely stolen by thieves, misused by a company’s employees, seized by government agencies, and diverted to new purposes by a company’s executives.
California Law Still Bans ID-Scan Databases, And Bars Should Follow That Law
In 2018, California lawmakers closed what they viewed as a loophole. Existing law already prohibited businesses from retaining or using information obtained when they “swiped” a driver's license, except for the narrow purposes of legal requirements (like a judicial warrant) or “preventing fraud, abuse, or material misrepresentation.”
After reviewing companies like PatronScan, the Legislature amended the law to make clear that the same restrictions that apply to businesses that “swipe” ID cards also apply when those IDs are “scanned.” PatronScan opposed that change, arguing it wanted to preserve the ability to share information among bars so participating venues could decide whether to admit patrons.
The bill became law anyway. Yet PatronScan continues to market and sell a system that apparently retains information from scanned IDs, and allows participating venues to flag patrons and share information across its network.
At a minimum, that raises serious questions about how those practices fit with California's existing ID privacy law. Bar and nightlife venue owners who utilize PatronScan should think twice about its effects on their customers, and consider going back to standard, visual ID checks. These physical checks have been effective at keeping underage patrons out of 21-and-over venues for decades, and don’t present the serious privacy dangers of creating a private database of bar patrons.
For venues serving vulnerable communities like immigrants or the LGBTQ+ community, the stakes of using this technology are even higher. It’s disappointing and alarming to see some of California’s more well-known LGBTQ+ nightlife spots instead lining up as PatronScan’s early adopters. A venue cannot claim to be a safe space while feeding its patrons’ data to a third party database. These businesses should reject PatronScan, return to the standard ID checks that every other bar has been able to utilize, and prove to their customers that their privacy and security still matters.
Farmers Are Getting Control Of Their Equipment Back [Deeplinks]
For years, John Deere had actively made repairing their tractors near-impossible for anyone but itself and the few "authorized" repair shops—regardless of the ability of its customers to actually visit such shops. Now, in a major win for farmers and right to repair advocates, John Deere must soon provide farmers with not just the tools and resources to finally repair their own John Deere equipment, but also access to future updates for said equipment.
In 2025, the Federal Trade Commission (FTC) brought a suit against farm equipment manufacturer John Deere, alleging John Deere used their control over equipment repair tools and resources to limit the ability of farmers and independent repair providers (IRPs) to repair John Deere equipment. Earlier this month, John Deere reached a settlement with the FTC in which they will immediately make available a tranche of repair resources, then continue to make further resources available until the end of the year. Five states joined the FTC in this suit, and over the next 10 years these states will work alongside the FTC to ensure John Deere complies with this settlement.
It is worth noting there is a second, farmer-initiated antitrust lawsuit against John Deere, also concerning a farmer’s right to repair their own equipment. In April, John Deere agreed to a $99 million settlement in that case, which also includes right to repair provisions.
This fight is just one example of how, as machines become increasingly computerized, companies like John Deere restrict your ability to repair machines behind software subject to legal regimes that don’t just lock down repair, but make unauthorized repair a potential criminal offense.
John Deere’s market dominance in farm equipment led to an extraordinary power over access to the tools and resources of repair. John Deere actively restricted who had access to repair tools, and monopolized who could do the repair. This revenue stream—and control of it—is built into the business models of a lot of the technology we buy today. It also encourages companies to move away from the kinds of devices that can be easily fixed at home to ones that offer bells and whistles no one wants but makes repair difficult—like app-enabled toasters.
This whole saga with John Deere has been an exemplar of the greater need for right to repair laws, policy, and enforcement. There was a time when you bought a tractor and with some know-how and a manual could fix it yourself. It is easy to envision why someone with John Deere farm equipment might find it inconvenient to wait for John Deere approved repairpeople to come and fix any broken equipment. Especially when it meant waiting for days or weeks. Especially if it meant their crop was withering on the vine. This settlement will help ensure this is no longer the case.
But it’s not just about farm equipment; If you can’t fix it, you don’t own it. While some might feel more willing to agree they “shouldn’t” futz with laptops or smartphone, it still stands that — whether it’s farm equipment, a car, a laptop, or even your phone — if you legally cannot fix it yourself, if you must go hat in hand to an “approved provider,” you are at the mercy of a corporation. It is why EFF continues to support right to repair laws that ensure people truly own what they buy. And it is why EFF continues to fight for exemptions to the law that makes it most difficult to tinker and repair your own devices.
16:21
Teaching Coding When AI Can Write the Code [Radar]
For as long as we’ve taught programming, the student’s code has provided a window into the students’ thinking. Errors, the code structure, the awkward working solution—all of it showed how someone reasoned and where they got stuck.
It was never a clean window. Students have always copied, crammed, and borrowed, sometimes turning in work they didn’t fully understand. But the code still left clues. Generative AI has changed that: A finished program now tells us more about a student’s prompts than their ideas. And here’s the part that should unsettle us—often, the better the code looks, the less we can say about what the student actually learned.
This raises a bigger question: If AI can write code, should we still teach coding? I believe the answer is yes, at least for some students and situations. But that’s another topic. Here, I want to focus on the next step: If we continue teaching coding in a world with AI, how can we know if students are really learning?
Some schools have responded by trying to catch students. They use AI detectors, surveillance tools, locked-down browsers, stricter rules, and clearer honor codes. This has also led to more suspicion.
Some of these responses make sense. Teachers want to protect learning, and schools want to keep things fair. But using detection as the main way to assess students is weak. Stanford researchers found that popular AI detectors often falsely flagged writing by nonnative English speakers, with 61.22% of TOEFL essays in one study marked as AI-generated. OpenAI even retired its own AI Text Classifier in 2023 because it wasn’t accurate enough. If the company that created the tool can’t reliably detect AI, it’s probably not a good idea to base your honor code on it.
But detection isn’t the real issue. Even if we had a perfect detector, we’d still be asking the wrong question. Instead of asking, “How do we stop students from using AI?” we should ask, “How do we teach coding in a world with AI, making use of its benefits, while still being able to see if students are learning?”
Borrowing from the studio
We’re seeing this challenge with students at AET, the Arts and Entertainment Technologies Department at the University of Texas at Austin. Although my usual home is Computer Science, it so happens that AET is within the College of Fine Arts at UT, which offers many other ways to learn and assess: studio work, critique, rehearsal, revision, and performance.
In the arts, the final piece has never been the whole story. A painting doesn’t explain the choices behind it. A performance doesn’t reveal the rehearsals. A design board doesn’t show the discarded versions. A composition doesn’t tell you where the student struggled or what they finally learned to hear.
Art education has developed practices that focus on visible progress. Students bring in sketches and drafts, discuss influences, revisions, and failures, and rehearse, perform, and critique each other’s work while it’s still in progress.
At AET, we teach creative coding, which means programming to create art, design, games, or experiences. That doesn’t mean coding for poets. Our students—game designers, web developers, and programmers—start from scratch and learn advanced concepts in tools like Processing and p5.js. In the creative coding tradition, a program is often called a sketch, borrowing the term from the art world. It means something temporary, exploratory, and open to change—something you make, test, revise, and share.
So in creative coding, we were already leaning toward the studio model of sketches, experiments, iterations, and critique. Now we’re pushing that further as we rethink how we teach coding in an AI world. Here are three things we’re already using or actively developing.
Make the work public
We run the class like a studio. It’s not that work never happens at home, but the most important work needs to be seen in the classroom. Students show their code, including false starts, revisions, the choices they made, and the reasons behind them. Assignments are no longer just things you submit—they become projects you develop in public.
AI isn’t banned from the classroom. Instead, it’s treated as a helpful assistant to learn from. Students share prompts and techniques. They use AI, Google, Stack Overflow, classmates, or any other resources.
But you still need to take responsibility for your work. If you submit or present it, you must explain what the code does, why you made those choices, and how it works. If I need to ask your AI to understand your code, something is wrong. Getting help is fine, but hiding behind that help is not.
You can’t outsource to AI what the whole room watched you build.
A real studio needs students talking out loud together in the room every day. This also helps with another issue that isn’t about AI. Many people say students today are quieter than in the past. While this is mostly based on stories rather than long-term studies, these stories are common and consistent. Faculty on all types of campuses talk about silent classrooms and students who hesitate to speak up, especially since 2020.
Whatever the reason, this silence can be changed, and the solution is the same as for AI challenges: encourage students to participate. Communication is one of the most important skills in any career, including explaining ideas, defending choices, and persuading others in real time. Students don’t develop these skills by just submitting AI-guided work online. When they share their work publicly, it not only prevents AI misuse but also helps them build the skills they need most.
Invert the roles: AI as teacher and assessor
We know the usual pattern: A student asks, AI answers, and the student copies. We’ve tried to invert this. In our new approach, the AI works with the student on a set of topics, engages them in a conversation they must navigate, and ultimately assesses how well they understand the material, which leads to a grade.
This idea has a research background that goes back before ChatGPT. Teachable-agent systems like Betty’s Brain showed that explaining—even to a software agent—forces students to organize their knowledge, make connections clear, and find gaps. Our model uses this insight differently. The student isn’t teaching the bot. Instead, the student is having a conversation with it, learning, discussing, debating, and showing what they understand.
 The Vera Molnár chatbot at the University of
Texas at Austin
The Vera Molnár chatbot at the University of
Texas at Austin
How did we do this? With fairly simple prompt engineering, we created an avatar chatbot of Vera Molnár (1924–2023), a pioneer of algorithmic art. The bot takes on Molnár’s role, drawing students into conversations about randomness, computation, generative art, and creative choices. Her practice sits exactly where creative coding students need to think: between rule and variation, system and choice, computation and visual judgment.
A system prompt sets the topics and types of questions to ask. The bot goes through these with the student, asks for more detail on unclear answers, and keeps following up until there is proof of understanding. At the end, it reviews the conversation against a rubric, giving us a clear record of which ideas the student covered, where they struggled, and how well they improved.
Besides the assessment, which is often accurate, the transcript becomes a different kind of proof, showing what a typical assignment might hide. What did the student notice? What did they misunderstand? Could they connect the concept to the code? Could they defend their choices? Could they revise their explanation when challenged?
When we switch the roles, something surprising appears: the one thing a finished submission can’t show.
A student thinking out loud.
Make understanding performative: Make students perform
Programming has never really had a tradition of performance. Musicians have it, painters have it, and dancers have it. Live coding is starting to change that.
Every semester at AET, students from different disciplines stage an algorave together—short for algorithmic rave. Audio sets, projection pieces, game demos, lasers, drones, experience design. The creative coding class brings live visuals into the live-coding tradition: Code is written and modified in real time, the screen is projected, and the audience watches the editor change as the visuals respond to the music other students are playing.
 The Department of Arts and Entertainment
Technologies’ annual AudioPixel Collider algorave, November
20, 2025, B. Iden Payne Theatre, The University of Texas at
Austin
The Department of Arts and Entertainment
Technologies’ annual AudioPixel Collider algorave, November
20, 2025, B. Iden Payne Theatre, The University of Texas at
Austin
No prerender. No hiding the machinery.
The Live Coding manifesto, written in 2004 by TOPLAP, includes a line that fits every AI-era assessment conversation: “Obscurantism is dangerous. Show us your screens.” This is not just a performance ethic; it’s also an assessment strategy.
A student walks on stage. The projected screen is their editor. The room can read it. The music starts. And they build up a line of code on screen like:
osc(18, 0.08, 1.2)
.modulate(noise(3), 0.25)
.rotate(() => time * 0.1)
.out()
This is JavaScript building visuals in real time. FFTs, chained functions, higher-order manipulations. When you’re manipulating code like that on stage, you’d better know what you’re doing.
AI can help you prepare. Good. Let it.
But once you’re on stage, the question shifts from “Can you copy and paste code?” to “Can you control it?” You can paste code into a file, but you can’t paste your way through three minutes of public debugging while the whole projection turns into a beige rectangle. In a live build, understanding has nowhere to hide.
 Student livecoding at the Department of Arts and
Entertainment Technologies’ annual AudioPixel Collider
algorave, November 20, 2025, B. Iden Payne Theatre, The University
of Texas at Austin
Student livecoding at the Department of Arts and
Entertainment Technologies’ annual AudioPixel Collider
algorave, November 20, 2025, B. Iden Payne Theatre, The University
of Texas at Austin
Can you read the code, make changes on purpose, and recover when something unexpected happens? That’s fluency: knowing what to do next while the system is still running.
It is very hard to plagiarize panic.
A note on assessment
So far, our results are based on our own observations. We haven’t conducted a controlled study or compared different groups, so what we have seen might just be early variation rather than patterns that apply more broadly. For now, these efforts are experiments, not final answers.
Assessment in studio and live performance settings is always subjective and focused on people. It relies on monitoring students’ progress, providing feedback, and observing how they handle challenges. We do not plan to change this core approach.
For the Molnár conversation assignment, students discussed Molnár using an AI system. The AI then created a summary and analysis of each student’s understanding. Teaching assistants reviewed this analysis, conducted their own assessments, and assigned grades. In our small experiments, the AI’s assessments using the rubric matched closely with the teaching assistants’ own evaluations.
We also used AI to help grade the end-of-term coding assignment. In this project, students improved an object-oriented game by adding strategies like heuristics, search algorithms, and learned behaviors. Since our teaching assistants had limited experience with object-oriented programming, we developed a detailed rubric and had an AI model use it to evaluate each submission. The AI’s analysis was given to the teaching assistants as support. It helped them see how each project was structured, spot important OOP design choices, and use the rubric with more confidence. The teaching assistants still made their own grading decisions. I was available as the OOP expert for any questions they could not answer. From what I observed, this substantially helped the teaching assistants understand and grade the students’ OOP design work.
More broadly, both approaches appear to enable substantive feedback at a scale that would otherwise be difficult given our current student-to-teaching-assistant ratios.
The process is the proof
We spent the first two years of the generative AI panic asking how to catch students using AI—or prohibit it altogether. Wrong question.
The real question is whether the assignment gives students a real way to show and develop their understanding. This view isn’t limited to educators. NVIDIA CEO Jensen Huang recently argued that students should not focus on finding an “AI-proof” subject. Instead, he suggested they consider how AI can help them learn more deeply and develop their skills and sense of purpose. He highlighted storytelling, creativity, design, and judgment as abilities that will stay important even as AI takes over more tasks. This supports a key idea in coding education: The aim is not to prove you didn’t use any tools, but to help students show how they think, make choices, revise, and take responsibility for their work.
These three practices are experiments, not universal solutions. They work especially well in creative coding, where code already has a public, visual, and performative aspect. But they suggest a broader principle: As finished work becomes easier to generate, assessment needs to focus more on process, explanation, revision, and mastery.
This matters outside of school too. A polished memo no longer proves there was real thinking behind it. A working prototype no longer proves product sense. A passing pull request no longer proves the developer made the change carefully and thoughtfully. AI makes production easier, so evaluation must focus more on how people think, choose, revise, and recover—in code review, hiring, and performance management. The artifact is no longer the proof. The process is.
Generative AI didn’t make assessment impossible. It just made a hidden weakness obvious. We were putting too much trust in finished work. The arts always knew better.
Show us your screens.
Acknowledgements
Thanks to Mike Loukides, Michael Baker, Mk Haley, Elisabeth Robson, and Honoria Starbuck for feedback on this article.
References
OpenAI. “New AI classifier for indicating AI-written text.” OpenAI Blog, January 31, 2023. Updated July 20, 2023, to note the classifier was no longer available due to low accuracy.
Liang, Weixin, Mert Yuksekgonul, Yining Mao, Eric Wu, and James Zou. “GPT detectors are biased against non-native English writers.” Stanford HAI, July 10, 2023.
Winthrop, R. (2026, May 27). Writing with A.I. weakens your creativity. The New York Times.
TOPLAP. “TOPLAP Manifesto.”
Schell, J., Ford, K., & Markman, A. B. (2025). Building responsible AI chatbot platforms in higher education: An evidence-based framework from design to implementation. Frontiers in Education, 10, Article 1604934. https://doi.org/10.3389/feduc.2025.1604934
Biswas, Gautam, Daniel Schwartz, John Bransford, and the Teachable Agents Group at Vanderbilt. “Technology support for complex problem solving: From SAD environments to AI.” In Learning to Solve Complex Scientific Problems, 2001.
Leelawong, Krittaya, and Gautam Biswas. “Designing learning by teaching agents: The Betty’s Brain system.” International Journal of Artificial Intelligence in Education, 2008.
Tan, Huileng. “Jensen Huang Says It Doesn’t Matter What Kids Study in the AI Era.” Business Insider, May 26, 2026. https://www.businessinsider.com/nvidia-jensen-huang-what-kids-should-study-ai-education-advice-2026-5
DAM Digital Art Museum. “Vera Molnár.” Artist biography and timeline.
16:14
The Big Idea: Alex Shvartsman [Whatever]

To mock a classic trope in your own story, one must first unabashedly love that trope. Author Alex Shvartsman is a die-hard sci-fi fan, which gives him the perfect angle to write his own take on things. Follow along in the Big Idea for his newest novel, The Best of All Possible Planets, as we make fun of tropes (lovingly) together.
ALEX SHVARTSMAN:
One day, my son read Candide by Voltaire for school, and wanted to discuss the book with me. I remembered enjoying the novella, but it had been decades ago, and I had never read it in English translation. So I opened Project Gutenberg and dove in. I still liked it, but my main takeaway was this: A loose retelling of Candide (sans a load of 17th Century misogyny) would make for an excellent space opera comedy.
Every writer knows this feeling—sometimes an idea grabs you by the shirttails and won’t let go until you spill it onto the page. The more I thought about Space Candide the clearer the book structure seemed in my head. My characters would travel from planet to planet on a ship O.F. Theseus in search of a MacGuffin, and each of those planets would represent a space opera trope or cliché. Then I would lovingly skewer and deconstruct this cliché in ways most conducive for hilarity to ensue.
The key word is lovingly. I adore space opera, and it was important to me that I poke fun at its tropes as an admiring fan, without coming off as someone disdainful of science fiction. With that in mind, I began making a mental list of tropes and major franchises I wanted to parody, and the list grew fast.
- What is the reason all those ancient alien artifacts are lying around for protagonists to find?
- Robots are supposed to kill all humans, but what if they don’t really want to? It’s just something from their sacred text, decreed by their lord and savior, Clippy.
- What is the Doctor’s true motivation? After thousands of years, shouldn’t all the heroics get old?
- What if the Green Lantern Corps/Lensmen equivalents acted more like today’s cops?
- Just how universal are the universal translator devices?
- Who would win in a battle between an Imperial Star Destroyer and a Federation starship?
Add to that wacky aliens, an opinionated omniscient narrator, lots of misconceptions about Earth’s ancient past (a.k.a. our era), and corgis.
If that sounds a bit like The Hitchhiker’s Guide to the Galaxy, it should. I consider Guide, along with Futurama, to be both the inspiration and the spiritual godparents of this book.
I wanted to include direct nods to many more books, movies, and TV shows spanning a gamut from the subgenre’s inception with Edmund Hamilton and E.E. “Doc” Smith, to recent works by Ken Liu and Adrian Tchaikovsky. (And yes, a reference to my kind host’s Old Man’s War is in there as well.) There’s an Apologia chapter at the very end listing all the references I could recall myself during the editing process.
I quickly discovered that writing straight-up comedy is so much more difficult than writing action-adventure books with humor in them. Comedy works best in the short form, because humor can get repetitive and outstay its welcome. I did my best to resolve this problem by mixing up different kinds of humor; from wordplay to slapstick, pop culture references to puns (I firmly believe that the only good pun is a terrible pun), absurdity to social commentary. Then I structured the book as a coming-of-age road trip, with characters who grow and change as they experience the galaxy around them. It will be up to you, gentle reader, to judge whether I’ve succeeded.
And if you do like it, it will be in part thanks to the brilliant team who made The Best of All Possible Planets the best possible version it could be. With cover art by Ethemos, brilliant interior illustrations by Anna Butova, Adam Cvijanovic, and Zishan Liu, and audiobook narration by Eli Schiff and Lewis Black (yes, that Lewis Black; this is the first time he’s ever participated in creating an audiobook) they greatly enhanced my work. Any flaws or faults, however, are entirely my own.
Finally—and it should go without saying, but in this day and age it has to be said—although robots and AI are some of the characters in this book, no Copyright Infringement Blender was used to create it. I relied solely on my Natural Stupidity instead.
If you need more humor in your life—and these days, I think we all do—follow the corgis!
—-
The Best of All Possible Planets: Amazon|Barnes & Noble|Bookshop
16:07
Wayfire 0.11 released [LWN.net]
Version 0.11 of the wlroots-based Wayfire Wayland compositor has been released. Notable changes include better fractional scaling, per-output ICC profiles, support for additional Wayland protocols, and more.
[$] A report from Debian's new DFSG team [LWN.net]
The DFSG, Licensing & New Packages Team (usually shortened to "DFSG team") was created in October 2025 as part of the ftpmaster team split. Its job is to review packages in the new queue for compliance with the Debian Free Software Guidelines (DFSG), among other things, before the packages are allowed to enter the Debian archive. The change was long in coming, and some questions remained after the split whether it was the right move. Andrew McMillan provided an overview of the team's activities and its current status during DebConf26. While it may be too early to say with certainty, his report suggests that the new division of duties is working out well.
15:14
Dirk Eddelbuettel: RcppDate 0.0.7: New Upstream [Planet Debian]

RcppDate ships the featureful date library written by Howard Hinnant to enable use from R packages. This header-only modern C++ library has been in pretty wide-spread use for a while now, and adds to C++11, C++14 and C++17 what is (with minor modifications) the ‘date’ library in C++20. The RcppDate package adds no extra R or C++ code and can therefore be a zero-cost dependency for any other project; yet a number of other projects decided to re-vendor it resulting in less-efficient duplication. Oh well. C’est la vie.
This release syncs with upstream release 3.0.5 made yesterday. We also made two routine updates to the continuous integration since the last release a good year ago. The Debian and r2u packages for this new release have already been uploaded too.
Changes in version 0.0.7 (2026-07-27)
Updated to upstream version 3.0.5
Regular updates to continuous integration setup
Courtesy of my CRANberries, there is also a diffstat report for the most recent release. More information is available at the repository or the package page.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. If you like this or other open-source work I do, you can sponsor me at GitHub.
14:49
CodeSOD: Convert Back, Way Back [The Daily WTF]
Windows Presentation Foundation, the XML-based UI framework for Windows, has its own "fun" quirks. One of its core ideas is that controls can be data-bound: that text box is linked to a numeric field in your model class. Type a different number, and the model automagically updates.
That's fine for what it is, but of course you're going to need
to give it some instructions on how to do those kinds of
conversions for your own custom types. And that's where the
IValueConverter interface comes in.
You can write a class which implements that interface, which can
then Convert and ConvertBack. Which, as a
note, I hate that naming convention; which way is "back"? Well,
that's controlled via an annotation. This is some of Microsoft's
sample code, from their docs:
[ValueConversion(typeof(Color), typeof(SolidColorBrush))]
public class ColorBrushConverter : IValueConverter
{
public object Convert(object value, Type targetType, object parameter, System.Globalization.CultureInfo culture)
{
Color color = (Color)value;
return new SolidColorBrush(color);
}
public object ConvertBack(object value, Type targetType, object parameter, System.Globalization.CultureInfo culture)
{
return null;
}
}
I don't particularly like this API, but again, it is what it is. This converts a color into a brush, and returns a null when we try and convert back, because that's not a valid operation.
Which brings us to Fredrika's submission. You
see, there is a problem with this approach. If you bind a text box
to a double? field, everything is fine and handled
automatically- except the built-in converter doesn't turn empty
strings into nulls. So one of her co-workers wrote this:
public class StringToDoubleConverter : IValueConverter
{
public object Convert(object value, Type targetType, object parameter, CultureInfo culture)
{
double? parsed = value as double?;
return parsed;
}
public object ConvertBack(object value, Type targetType, object parameter, CultureInfo culture)
{
string parsed = value as string;
if (parsed == string.Empty)
return null;
return parsed;
}
}
Convert doesn't do anything.
ConvertBack takes the string from our text box, checks
if it's empty, and if it is, returns null.
Now, you'll notice something about the code here: when it
Converts, it casts value as double? and
when it ConvertBacks, it casts value as
string. So that's where it's reaching out to the .NET
Framework's built-in conversion functions.
I'm not entirely sure where to point to for the WTF, and some of
that may be because I've had the good fortune to never have to use
WPF. I don't like WPF's approach, but the developer behind this
code isn't helping matters. Certainly naming variables
parsed isn't clarifying matters.
I don't have a nice bow to put on this one. I just don't like any of this. I don't like the converter API. I don't like this implementation of it. I don't like trying to treat empty text boxes as null values, which I'm sure is correct here, but boy howdy do I suspect there'll be problems in the future.
14:35
Security updates for Tuesday [LWN.net]
Security updates have been issued by AlmaLinux (grafana and libreswan), Debian (openjdk-11 and openjdk-17), Fedora (opkssh, perl-Mojolicious, and rpm), Mageia (libyang, memcached, nginx, packages, and sqlite3), Oracle (.NET 8.0, acl, buildah, compat-openssl11, compat-poppler022, dogtag-pki, git-lfs, glibc, go-fdo-client, golang, httpd:2.4, jackson-annotations, jackson-core, jackson-databind, jackson-jaxrs-providers, and jackson-modules-base, kernel, libpq, LibRaw, maven:3.8, mysql8.4, nodejs:22, nodejs:24, openssl, podman, poppler, python3.14, samba, sssd, tomcat, tomcat9, vim, and yggdrasil), Red Hat (gstreamer1-plugins-bad-free), SUSE (afterburn, alsa, apache-ivy, avahi, aws-nitro-enclaves-cli, chromium, cifs-utils, cockpit, cockpit-machines, cockpit-packages, cockpit- podman, cockpit-repos, cockpit-subscriptions, containerd, curl, docker-compose, freetype2, gawk, glib2, google-cloud-sap-agent, gpg2, gstreamer-plugins-bad, gzip, helm, ignition, ImageMagick, jackson-annotations, jackson-bom, jackson-core, jackson- databind, jackson-dataformats-binary, jackson-modules-base, jackson-annotations, jackson-core, jackson-databind, java-11-openjdk, jline3, joe, jq, kernel, libgcrypt, libknet-devel, libsoup, libxml2, mariadb-connector-c, mcphost, net-tools, nghttp2, opennlp, openssl-1_0_0, PackageKit, pam, patch, pcr-oracle, perl, perl-DBI, perl-HTTP-Date, python-aiohttp, python-cryptography, python-Pillow, python-pyasn1, python-soupsieve, python-tornado, python-tornado6, python-urllib3, python3, radvd, rust-keylime, s390-tools, shibboleth-sp, sssd, systemd, tiff, vim, and wpa_supplicant), and Ubuntu (FreeIPMI, glibc, linux-aws, linux-aws, linux-raspi, linux-aws-6.8, linux-aws-fips, linux-azure, linux-azure-6.8, linux-azure, linux-oracle, linux-azure-5.15, linux-azure-fde-5.15, linux-oracle-5.15, linux-azure-6.17, linux-azure-fde, linux-azure-fde-6.17, linux-azure-fde-6.8, linux-azure-fips, linux-hwe-6.8, linux-ibm, linux-ibm-6.8, linux-nvidia-tegra, linux-xilinx, linux-oracle-6.17, roc-toolkit, and samba).
14:00
When the walls came down [Scripting News]
Yesterday's Scripting News was one of the most news-full days in a long time, maybe going back to the rollout of RSS 2.0 in September 2002. If you look at what's there, a post about re-opening the Frontier object database format would be considered the top item on any other day, but it's the last of the untitled posts for the day.
At the top of the page, a surprise that Matthias Pfefferle at Automattic had built a substantial (and unforeseen!) bridge between WordPress and RSS.chat. It builds on the new features. This may turn out to be the moment RSS started being accepted as a social web protocol by the insiders, alongside ActivityPub and AT Proto.
Look at what we've done. I stress we. Matthias didn't need to tell us about what he did until it was done. That my friends is how the web works, that's what I've been trying to show you, and now it has been shown. In a way the clock has gone back to the world before Twitter when events like this happened pretty routinely.
Small pieces loosely joined and all parts replaceable. The web in a sentence. That's what you're buying into when you put your work on the web.
Anyway, now we've got half of the big picture working. Also yesterday, before I knew what Matthias had been cooking up, I wrote a piece about how I see the network evolving. I predict, if this bootstrap works, we will come back here in a year and say things like "If he only knew." But that's how it goes, you tell your story and leave a record of it, and then later you can go back and see what it looked like as it happened, not as you remember it.
I'm proud that I have a record of September 2002 for you all to scroll through. That was when we knew that RSS was going everywhere. NYT support got us the full support of the news industry, and they worked fast in part because it is really simple. :-)
And almost unnoticed, something even I seem to forget -- this is also a new launch for RSS. We're using old reliable RSS 2.0 as specified in 2003, even using one of the elements that had never had been much used. Claude suggested it, I never would have thought of it, a perfect fit. What people may realize but don't realize the importance of, that RSS is extensible. I've accumulated all the extensions I use in my software since the early teens in the source namespace. And that's where the new stuff went. Guess what folks, RSS got an upgrade. First time in a long time. Perhaps you didn't think that was possible.
I played with a lot of names while RSS.chat was in development but decided the name had to be RSS.something. It deserves a lot more love than it has gotten from the tech world. I don't want to hide it, I want it to get a victory parade like the one the Knicks got on Broadway after winning the championship. It's an incredible gift that all that came together the way it did. People think they understand how it happened, but they only understand the BigCo version of how they buried RSS and were proud of it. Well I'm here to tell you that didn't happen. It's still here to pick up the pieces of what's left of the social web, after the VCs got through with it. We're picking up where we left off in 2006.
Because of Claude, we are able to work very fast now as long as we know what we're doing. I'm doing some projects on the side with Claude that are bearing fruit amazingly fast, because we have a very clear idea of what we hope to do. The tools keep getting better, and in this period, the art of creating software has blasted into outer space. It's as if the best transport we had was a horse and buggy and now all of a sudden we have everything we have today, bikes, cars, planes, rocket ships. The challenge is how high do you dare to set your ambition. It seems, based on experience, it doesn't matter how high it is as long as you know where you want to go.
Journalism only sees the threat. This change is on the level of curing cancer. We may have thought it might be possible someday to do what we're doing now, so amazing that as you watch Claude make it happen you get goosebumps and can't help but laugh out loud.
I thought my career was winding down, but now it feels like it's just getting started.
Reminded of a great quote in Godfather III, Michael Corleone says: "Just when I thought I was out, they pull me back in."
Here we go!
PS: A new this.how page for RSS.chat. It has a little directory to the big spots you might want.
13:56
Time for something new... [RevK®'s ramblings]
Latest project is a time server.
So why? Well, they exist - you can buy a really nice LeoNTP server, with impressive specs. We see response times of 0.1ms, and it claims 100,000 requests a second. They also have a PPS output, and can do a calibrated 10MHz output apparently (I can't do that).
Can I get close using an ESP32? Well, sort of.
Challenges
It should be simple, in theory - a GPS module, capture CPU cycle count on PPS interrupt and use to get clock rate. Capture NMEA to get time for PPS. Capture cycle count on NTP packet and use reference cycle count, clock rate, and reference time to know exact time of day to fill in NTP reply. yay!
Of course it is never entirely that simple. I did all this and got a working system, but I could do better. My latency as measured on a FireBrick was 2.5ms. I did averaging of the PPS intervals to get a more consistent clock rate, and often the standard deviation on that was below 10ns! But not always. I then did a best of last 5 seconds in terms of a PPS interval to use as a reference - that way the odd delayed interrupt had no impact. That seems to work.
One thing I wanted was PPS interrupt at higher priority than Ethernet, but all GPIOs on an ESP32 are the same interrupt source. Bugger. Do a search and you see plenty of people pissed off about this. I found a fix, make the PPS a PCNT (Pulse count) which has an interrupt (count to 1) which can be set separately to the Ethernet interrupt. There is a trick to remember.
The hardware
The PCB design is not that hard now I have cracked Ethernet. A main PCB, with USB-C, DC input, PoE, and Ethernet.

I have since made an even more compact design.
This then connects to a GPS module, which you can hang out the window (or better, fit in a Stevenson screen). Link with 5 core cable (solid cat5 is ideal), and it can handle a few metres.


Then put both in a nice 3D printed case. See https://shop.revk.uk/ if you want to buy. £60 not £600!
Making it faster
The fact my response times where around 2.5ms was not ideal. I wanted better, but how.
First bodge was hook in to the Ethernet driver receive code and check for NTP packets as they come in, and do a direct reply. I got latency down to 1ms, yay!
But I can do better :-)
Scrap the Ethernet controller altogether. Write my own custom low latency driver. Dedicate CPU1 to PPS and Ethernet only. My custom driver can...
- Be reactive only - reply immediately to ARP, ND, and NTP.
- Being reactive, no need for mutex wrap on access to Ethernet chip.
- Work in interrupt (yes, nasty, but dedicated CPU) so not task switching.
- Know state of registers to avoid read-modify-write as used a lot in standard driver code.
- Do read fifo and write fifo with no clean-up between
And guess what - latency down to 0.1ms - bang on what I wanted. Indeed I have seen 0.077ms even.
Now, the logic is fun - it makes the Ethernet no use for anything but NTP. So I have made it (a) optional, and (b) normal Ethernet for first 2 mins so you can access it via Ethernet if needed (assuming you can control power/PoE to reset).
But once switched to low latency NTP only Ethernet, you have to use the WiFi for any access, management, MQTT, and so on.
Bugs
I found bugs in the Ethernet chip (KSZ8851SNL) which does not check IPv6 UDP checksums correctly!
I also found it almost impossible to convince the Ethernet chip to give me unicast, multicast, and broadcast packets - in spite of a lot of reading the data sheet and trial and error. It is now in promiscuous and relying on the switch to protect it. Even that makes no sense - you have to set "Allow any packet" and "Invert the input filter" which to mean means "allow no packets!". I may yet find a working setting. I have already spent a day on this.
I also found it used edge triggered interrupt with a check in task for ISR set as well on timer, I changed to level triggered and that seems to work without hanging.
I also found it nearly impossible to cleanly decommission the Ethernet driver in ESP IDF. I managed to take over interrupts and kill the task, and that was all. Anything more thorough was a nightmare. But that works.
What is it good for?
Well some people are putting in the UK NTP pool, it seems to meet the requirements well and work at a level similar to the rest of the pool.
But it is mainly aimed as being the main server in any business / office. Include with your pool NTP, but being local it will win.
I do not get close to even 10,000 requests a second, more like 5,000, but that is not needed for a typical business, even a large one.
12:14
Pluralistic: Discernment (28 Jul 2026) [Pluralistic: Daily links from Cory Doctorow]
->->->->->->->->->->->->->->->->->->->->->->->->->->->->->
Top Sources: None -->

Today's links
- Discernment: How can you fact-check AI when you're asking it to teach you something you don't understand?
- Hey look at this: Delights to delectate.
- Object permanence: How to help with computers; Batman equation; Fuck and the law; NC's racist voting law; Pregancy app is full of spyware; Stiglitz v Apple's "tax fraud"; Accelerometer fingerprinting; Sacklers v bankruptcy; Boss-politics antitrust.
- Upcoming appearances: Edinburgh, Sydney, Melbourne, Brighton, London, South Bend.
- Recent appearances: Where I've been.
- Latest books: You keep readin' em, I'll keep writin' 'em.
- Upcoming books: Like I said, I'll keep writin' 'em.
- Colophon: All the rest.

Discernment (permalink)
As far as I can tell, this dialog between MacArthur prize-winning mathematician Terrence Tao and Chatgpt about "the Jacobian conjecture counterexample" is very impressive:
https://chatgpt.com/share/6a5fdc7a-d6f8-83e8-bbea-8deb42cfed56
Now, the clause "as far as I can tell" is doing a lot of work in that sentence. I am reasonably math literate, up to first-year calculus and a lifetime spent around my father (a mathematician). However, I have never heard of "the Jacobian conjecture," and while I know what all the words in the first paragraph of the relevant Wikipedia entry mean, I can't parse any of the sentences they form:
https://en.wikipedia.org/wiki/Jacobian_conjecture
In other words, I lack the discernment to evaluate the output of the chatbot that Tao exchanged theories with. If you showed me an equally opaque transcript of a "conversation" between a chatbot and a crank with AI psychosis whose math made no sense whatsoever, I couldn't make an a priori judgment about which one was a solid piece of mathematical theorizing and which one was a math-flavored word-salad.
As many skilled programmers can attest, chatbots can produce very useful output – but as even the most ardent AI-assisted coder will admit, chatbot-written code is also full of baffling, obvious errors (and subtle, hard-to-spot ones):
https://pluralistic.net/2025/08/04/bad-vibe-coding/#maximally-codelike-bugs
These errors (which the industry wants us to refer to as "hallucination" – a whimsical, obscuring, anthropomorphizing euphemism) are the reason that reliable AI use requires the discernment that comes from skill and expertise. I use a local chatbot to spellcheck these posts. Chatbots spot all kinds of typos that regular spellcheckers miss:
https://pluralistic.net/2026/02/19/now-we-are-six/#stock-buyback
There's a reactionary group of strangers who seek me out to tell me that I'm a bad person for doing this. These are pointless conversations, mostly because I can barely make out a word over the scraping sounds of all the goalpost-moving these scolding strangers engage in.
They start by insisting that I'm burning down the planet by running a low-CPU load piece of software on my own computer. After I explain that running a chatbot on my machine uses no more carbon than, say, applying a blur effect to an image in my image editor, they tell me I'm unwisely giving my private data to the AI companies. Then I show them the network logs that demonstrate that my local chatbot doesn't send or receive any network data.
Then they turn to the supposed cognitive effects of using a chatbot to find typos in an essay. I explain that I'm not asking an AI to write things for me or explain them to me – I'm asking it to point out where I've forgotten to put a period at the end of a paragraph, or fatfingered a word like "ever" as "every." I even send them the "before" and "after" of an essay after I've corrected some chatbot-identified typos in it:
https://craphound.com/before.txt
https://craphound.com/after.txt
This is when things get increasingly pointless. My interlocutors come up with farcical reasons why it's immoral or dangerous to use this LLM-based spellchecker. They say I'm using too much compute and that I could use a simpler piece of software to do the same thing (which is both untrue and silly – I also run a journaling filesystem on my computer that is vastly overpowered for editing a textfile – who cares?). Or they insist that the mere act of making copies of published works in order to count their elements and the relationships between them is a sin, despite the fact that this standard would kill search engines, the Internet Archive, and the Oxford English Dictionary:
https://pluralistic.net/2023/09/17/how-to-think-about-scraping/
I mean, by all means let's hate the AI companies and work to end their disgusting campaign to pauperize creative workers, but let's not fall into the trap of siding with the media bosses who insist that the salvation of creative labor will arrive when Sam Altman pays David Zaslav for the right to cram the entire Warner catalog into Openai's chatbots:
https://pluralistic.net/2026/03/03/its-a-trap-2/#inheres-at-the-moment-of-fixation
Above all, my interlocutors continue to insist that my LLM-powered, local, open source chatbot spellchecker will make me a worse writer. It's a very strange insistence. My first word processor was a program listing published in a magazine I bought at a corner store and laboriously typed into my Apple ][+. In the 40+ years since, word processors have gotten lots of new features, many of which I thought were useful and many more that I found annoying. There were even some of these features that made the writers who used them worse at writing, in my (expert) judgment.
But from the very start, I knew that you couldn't just trust a spellchecker to correct your documents. I mean, I'm a science fiction writer. I started making up silly words decades before coining "enshittification." I've been telling spellcheckers to fuck off since I learned to type. If you aren't a good writer, spellcheckers are dangerous, and the more "advanced" the spellchecker is, the more dangerous it is.
A few of my collaborators insist that I use Office 365's AI-enabled version of Word to work on documents with them. It's maddening. I estimate the ratio of good suggestions to bad ones that M365 insists on shoving into my face at about 1:100. It's practically unusable – so much so that I often copy the block of text we're working on into a text editor, make my changes, then paste it back into the Word window.
If I were to accept even 10% of these suggestions, my work would be made significantly worse. Putting chatbots into Word pushed it from "annoying" into "enshittening." I certainly understand how relying on a chatbot to make edits to your work could make it worse.
That's where discernment comes in. I have written more than 30 books over the past 25 years. I have lots of experience defending my word choices, and not just against the mechanical judgments of a high-handed spellchecker, but also against overreaching copyeditors and paranoid publisher's lawyers. I know which words I want to write, and I know why I want to write them – and I know when a suggested fix is a good one and when it's wrong or stupid or just plain clunky. When it comes to writing, I have discernment.
That's not true when it comes to higher math. I would no more ask a chatbot to explain "the Jacobian conjecture counterexample" than I would tell my writing students to get a chatbot to suggest ways to fix their stories:
https://pluralistic.net/2026/01/07/delicious-pizza/#hold-the-gravel
I don't know nearly enough about math to ask a chatbot to explain it, or check my work, or even assemble a bibliography of human-authored works I should work my way through if I want to learn about it. If I wanted to understand "the Jacobian conjecture counterexample," I would set aside several days and work my way through that gnarly Wikipedia entry and its references and blue links to related concepts. If I really wanted to understand it, I'd enroll in a course at the Open University or Khan Academy.
All of this has been obvious to me since I first encountered LLM-powered bots. If you understand a subject really well – well enough to discern useful bot output from defective bot output – then bots can be useful. Sometimes very useful, mostly ordinarily useful. For example, I've been writing Pluralistic for about 6.5 years now. I've written 1,683 posts now (1,684 after I hit publish on this one), and the corpus is now getting large enough that I sometimes struggle to find a post I'm trying to reference, even with all my careful tagging and my extensive knowledge of WordPress's URL-line options for searching the database with tag and keyword combos.
I've been toying with the idea of exporting my whole corpus and shoveling it into a local chatbot, so that I can type, "Which post did I talk about the evils of showing people your chatbot output in?" and get a link to the correct essay:
https://pluralistic.net/2026/03/02/nonconsensual-slopping/#robowanking
(Don't follow this link! I will be referencing the essay it goes to shortly; I struggled to find it when I sat down to write today; I'd accidentally tagged it with "at" instead of "ai" and missed the typo when I published it.)
There are very few subjects I have more discernment over than "essays I have written." If I ask a chatbot to tell me which post I'm thinking of, I will instantly know which of its guesses are correct and which ones aren't. No one in the universe is better qualified than me to perform this task. No one ever will be.
Now, as it happens, I know exactly how badly a chatbot can screw up when it comes to my own work, because strangers insist on asking chatbots about me and then, for reasons I find baffling, they send me the output. Please don't show anyone your chatbot transcripts unless they ask to see them. It's embarrassing at best and annoying at worst:
https://pluralistic.net/2026/03/02/nonconsensual-slopping/#robowanking
(There's that reference I promised. You can follow the link now!)
Again, discernment is everything when it comes to getting useful work out of a chatbot. If you don't know anything about my work and you ask a chatbot to explain it to you, you will likely be badly misled. If you are familiar with my work and you ask a chatbot for the best examples where I explain a given subject, you may get a good answer, and if you get a bad one, you'll know it.
The centrality of discernment to productive AI usage is obvious, and that's why I find the insistence that AI can be used as a teaching assistant (or worse, a teacher) so baffling. By definition, a student isn't an expert on the subject they're studying. That's the whole point of studying – to acquire knowledge and thus discernment. Asking students to learn via chatbot explanations is both incoherent and dangerous.
Doubtless, there are ways that teachers might find chatbots useful, but for Christ's sake, don't use them to teach. There's plenty of ways teachers can use chatbots without asking students to learn from them.
Here's an example. My daughter graduated from a big, typical American high school a couple years ago, and I spent her high-school years getting progressively angrier about the bad compromises that her teachers were forced into.
Between "Common Core" and "Advanced Placement," the US system has been highly standardized. Teachers are under enormous pressure to teach specific aspects of specific subjects in a specific order, and students are told that their future life chances turn on their ability to pass high-stakes tests:
https://pluralistic.net/2024/01/16/flexibility-in-the-margins/#a-commons
This gives rise to many frustrations for teachers and students alike, but nothing got my dander up so much as my daughter's math teachers' testing practices. In all of my kid's higher math classes, teachers had a single, prized set of tests, and lived in fear of these escaping into the wild and turning into cheating aids. As a result, teachers collected students' math exams and quizzes and did not return them. Students sat exams, worked through the problems and got their grades – but were not allowed to take home their tests to see where they went wrong.
Look, I know I'm no mathematician, and I know I'm not a math teacher, but I know enough about pedagogy to know that this is crazy. This is like trying to get better at archery by loosing arrows at a target but not checking to see where they hit. It's bananas.
I also understand why the teachers felt they had to do it. Writing test questions that test for specific concepts in a specific order is a lot of work, and generating new tests for every class is the kind of task that would consume time better spent on lesson planning and meeting with students.
It's easy to imagine a teacher who creates prompts for each test question that cause a chatbot to emit a new test paper for each class, along with answer keys. These questions are easily validated by a skilled teacher, who definitionally has the discernment to know whether a test question fits the bill. I could even see vibe-coding a little app to spit these questions out – though again, I would want the teacher to work through the questions each time to make sure they were sound.
Both my parents are teachers. My brother is a teacher. I teach every now and again. Teachers do a lot of repetitive, unrewarding work. They also do a lot of difficult, creative, extremely important work. Good teachers have the discernment to sort good classroom materials from bad ones. They do that already, because just as you don't need an LLM to generate bad spellchecker suggestions, you also don't need an LLM to generate sub-par educational materials. There are plenty of "educational" publishers who'll do that all day long.
AI is a normal technology. That means there are times when it is useful and times when it is pointless or actively harmful. One rule of thumb for chatbots is that they can only provide useful information to experts who have the discernment to ignore the defective output that LLMs always emit. That means that the dream of chatbots as replacements for teachers is a nightmare.
Getting rid of teachers because we all have chatbots is like getting rid of doctors because we all have the plague.
Hey look at this (permalink)
- How Far Did Vannevar Bush Get on the Memex? https://brewster.kahle.org/2026/07/26/how-far-did-vannevar-bush-get-on-the-memex/
-
Things with Feathers https://vimeo.com/1188522762/7efe874428
-
Neuromancer — Official Teaser https://www.youtube.com/watch?v=g79GPZSQHBk
-
Shop worker owned businesses online https://www.workerowned.info/marketplace
-
Americans — including many Republicans — are losing faith in capitalism, polling shows https://edition.cnn.com/2026/07/23/politics/republicans-capitalism-socialism-poll
Object permanence (permalink)
#25yrsago How to help someone use a computer https://pages.gseis.ucla.edu/faculty/agre/how-to-help.html/
#20yrsago Arrested for taking a pic of a cop arresting someone else https://web.archive.org/web/20060813102257/http://www.nbc10.com/news/9574663/detail.html
#15yrsago Batman logo in equation form https://www.reddit.com/r/pics/comments/j2qjc/do_you_like_batman_do_you_like_math_my_math/
#15yrsago Vindictive WalMart erroneously accuses couple of shoplifting, has husband deported, wife fired, costs them house and car https://web.archive.org/web/20111002102637/https://www.courthousenews.com/2011/07/26/38455.htm
#15yrsago House Committee passes bill requiring your ISP to spy on every click and keystroke you make online and retain for 12 months https://www.eff.org/deeplinks/2011/07/house-committee-approves-bill-mandating-internet
#15yrsago Fuck and the law https://papers.ssrn.com/sol3/papers.cfm?abstract_id=896790&
#15yrsago Bill Nye explains to Fox News why lunar volcanoes don’t disprove anthropogenic global warming https://web.archive.org/web/20110924185725/https://www.mediamatters.org/mmtv/201107280007
#10yrsago North Carolina’s voter suppression law struck down as “racist” https://edition.cnn.com/2016/07/29/politics/north-carolina-voter-id/index.html
#10yrsago Pregnancy-tracking app was riddled with vulnerabilities, exposing extremely sensitive personal information https://www.consumerreports.org/electronics-computers/mobile-security-software/glow-pregnancy-app-exposed-women-to-privacy-threats-a1100919965/
#10yrsago “Tellin The World” 1972 voting PSA aimed at 18-25 y/o working-class voters https://archive.org/details/TellinTheWorld
#10yrsago Trump campaign frisks, then blocks ticketed Washington Post reporter at Pence rally https://web.archive.org/web/20160729170353/https://www.washingtonpost.com/news/the-fix/wp/2016/07/28/a-washington-post-reporter-was-banned-from-a-trump-pence-rally-yesterday-that-should-frighten-you/
#10yrsago Nobel-winning economist Joseph Stiglitz calls Apple’s tax strategy a “fraud” https://web.archive.org/web/20160731112543/http://www.bloomberg.com/news/articles/2016-07-28/stiglitz-calls-apple-s-profit-reporting-in-ireland-a-fraud
#5yrsago Unauthorized cups https://pluralistic.net/2021/07/29/impunity-corrodes/#well-run-dry
#5yrsago Tracking you with accelerometer signatures https://pluralistic.net/2021/07/29/impunity-corrodes/#in-motion
#5yrsago Stories from Black women's customer service hell https://pluralistic.net/2021/07/29/impunity-corrodes/#arise-ye-prisoners
#5yrsago Bankruptcy and elite impunity https://pluralistic.net/2021/07/29/impunity-corrodes/#morally-bankrupt
#1yrago Boss-politics antitrust and the MAGA crackup https://pluralistic.net/2025/07/29/bondi-and-domination/#superjove
Upcoming appearances (permalink)
- Virtual: EFFecting Change: Who the Machine Serves, Aug 12
https://www.eff.org/event/effecting-change-who-machine-serves -
Edinburgh International Book Festival with Jimmy Wales, Aug 17
https://www.edbookfest.co.uk/events/the-front-list-cory-doctorow-and-jimmy-wales -
Sydney: The Festival of Dangerous Ideas, Aug 23-24
https://festivalofdangerousideas.com/program/ -
Melbourne: Enshittification at the Wheeler Centre, Aug 25
https://www.wheelercentre.com/events-tickets/season-2026/cory-doctorow-enshittification -
Brighton: The Reverse Centaur's Guide to Life After AI with Carole Cadwalladr (Brighton Dome), Sep 8
https://brightondome.org/whats-on/LSC-cory-doctorow-the-reverse-centaurs-guide-to-life-after-ai/ -
London: The Reverse Centaur's Guide to Life After AI with Riley Quinn (Foyle's Picadilly), Sep 9
https://www.foyles.co.uk/events/enshittification-cory-doctorow-riley-quinn -
South Bend: An Evening With Cory Doctorow (Notre Dame), Oct 6
https://franco.nd.edu/events/2026/10/06/an-evening-with-cory-doctorow/
Recent appearances (permalink)
- AI is not inevitable (Betakit)
https://www.youtube.com/watch?v=DbiTVkq1WHo -
A Conversation with Lina Khan (Law and Economy Student Network)
https://www.youtube.com/live/7Ak5LZllqwE -
Will AI ever come alive, and what happens if it does? (BBC News)
https://www.youtube.com/watch?v=Lzk4o3fPZZE -
Waarom jij straks het hulpje van AI bent (VPRO)
https://www.youtube.com/watch?v=tOnvR2fs8CA -
Talk Tech Bock (Vera Linß)
https://www.youtube.com/watch?v=3PFjGvQoBgc
Latest books (permalink)
- "The Reverse-Centaur's Guide to AI," a short book about being a
better AI critic, Farrar, Straus and Giroux, June 2026
https://us.macmillan.com/books/9780374621568/thereversecentaursguidetolifeafterai/ -
"Canny Valley": A limited edition collection of the collages I create for Pluralistic, self-published, September 2025 https://pluralistic.net/2025/09/04/illustrious/#chairman-bruce
-
"Enshittification: Why Everything Suddenly Got Worse and What to Do About It," Farrar, Straus, Giroux, October 7 2025
https://us.macmillan.com/books/9780374619329/enshittification/ -
"Picks and Shovels": a sequel to "Red Team Blues," about the heroic era of the PC, Tor Books (US), Head of Zeus (UK), February 2025 (https://us.macmillan.com/books/9781250865908/picksandshovels).
-
"The Bezzle": a sequel to "Red Team Blues," about prison-tech and other grifts, Tor Books (US), Head of Zeus (UK), February 2024 (thebezzle.org).
-
"The Lost Cause:" a solarpunk novel of hope in the climate emergency, Tor Books (US), Head of Zeus (UK), November 2023 (http://lost-cause.org).
-
"The Internet Con": A nonfiction book about interoperability and Big Tech (Verso) September 2023 (http://seizethemeansofcomputation.org). Signed copies at Book Soup (https://www.booksoup.com/book/9781804291245).
-
"Red Team Blues": "A grabby, compulsive thriller that will leave you knowing more about how the world works than you did before." Tor Books http://redteamblues.com.
-
"Chokepoint Capitalism: How to Beat Big Tech, Tame Big Content, and Get Artists Paid, with Rebecca Giblin", on how to unrig the markets for creative labor, Beacon Press/Scribe 2022 https://chokepointcapitalism.com
Upcoming books (permalink)
- "The Post-American Internet," a geopolitical sequel of sorts to Enshittification, Farrar, Straus and Giroux, 2027
-
"Unauthorized Bread": a middle-grades graphic novel adapted from my novella about refugees, toasters and DRM, FirstSecond, April 20, 2027
-
"Enshittification, Why Everything Suddenly Got Worse and What to Do About It" (the graphic novel), Firstsecond, 2027
-
"The Memex Method," Farrar, Straus, Giroux, 2027
Colophon (permalink)
Today's top sources:
Currently writing: "The Post-American Internet," a sequel to "Enshittification," about the better world the rest of us get to have now that Trump has torched America. Fourth draft completed. Submitted to editor.
- A Little Brother short story about DIY insulin PLANNING
This work – excluding any serialized fiction – is licensed under a Creative Commons Attribution 4.0 license. That means you can use it any way you like, including commercially, provided that you attribute it to me, Cory Doctorow, and include a link to pluralistic.net.
https://creativecommons.org/licenses/by/4.0/
Quotations and images are not included in this license; they are included either under a limitation or exception to copyright, or on the basis of a separate license. Please exercise caution.
How to get Pluralistic:
Blog (no ads, tracking, or data-collection):
Newsletter (no ads, tracking, or data-collection):
https://pluralistic.net/plura-list
Mastodon (no ads, tracking, or data-collection):
Bluesky (no ads, possible tracking and data-collection):
https://bsky.app/profile/doctorow.pluralistic.net
Medium (no ads, paywalled):
Tumblr (mass-scale, unrestricted, third-party surveillance and advertising):
https://mostlysignssomeportents.tumblr.com/tagged/pluralistic
"When life gives you SARS, you make sarsaparilla" -Joey "Accordion Guy" DeVilla
READ CAREFULLY: By reading this, you agree, on behalf of your employer, to release me from all obligations and waivers arising from any and all NON-NEGOTIATED agreements, licenses, terms-of-service, shrinkwrap, clickwrap, browsewrap, confidentiality, non-disclosure, non-compete and acceptable use policies ("BOGUS AGREEMENTS") that I have entered into with your employer, its partners, licensors, agents and assigns, in perpetuity, without prejudice to my ongoing rights and privileges. You further represent that you have the authority to release me from any BOGUS AGREEMENTS on behalf of your employer.
ISSN: 3066-764X
Axon Is Another License Plate Surveillance Company [Schneier on Security]
Governments are switching, but I’m not sure it makes a difference:
…some municipalities, including Denver, Colorado, are ditching their Flock arrays. But keep in mind that if they’re only switching from Flock to another brand of license-plate readers, like Axon, it’s like a gambling addict trying to kick the habit by switching from FanDuel to DraftKings.
[…]
Despite what you may read on the Flock website, Axon cameras are pretty effective when it comes to hoovering up personal details that can go far beyond your license plate numbers. That means a municipality that opts for Axon cameras instead of Flock units won’t necessarily reduce the amount privacy its citizens lose through their use.
10:35
When new creation technologies arrive, they make the best a little worse and the bad a lot better.
Desktop publishing made every local garage sale sign a lot more legible, but can’t quite replace the hand-kerned and tweaked typography of the era before.
A smartphone in your pocket takes far better video of the family cookout than a super 8 camera ever could, but it’s no match for Hitchcock shooting in 35mm.
Autotune makes an average singer much better, but a world fueled by autotune might not have room for Tom Waits.
Of course, all of this matters more than ever, because AI is the great smush.
Most forms of human expression are smushed by a decent AI. None of it is as good as genius-level human work, and much of it is better than what was average a generation ago.
The smush creates volume, volume that often redefines our understanding of quality. And that volume establishes a new standard, until it gets smushed again.
You would think that the smush creates more demand for distinctive, handmade, human work. And that’s true–remarkable works of genius and originality have a chance to do better than ever. But the smush harms the market for pretty-good or even very-good human work. Because there’s less of that, less genius slips in as well.
Avoiding the tools is optional. Pushing harder than ever for the top tier isn’t.
08:14
Intersex: Between The Currents by SpirelleArt [Oh Joy Sex Toy]

05:42
Europe’s destructive heatwave [Richard Stallman's Political Notes]
The heatwave in Europe has caused a major crop failure.
Future heat waves are likely to do likewise, but other crop failures will result from flooding, which global heating is also making more likely.
Lobbying giant filmed [Richard Stallman's Political Notes]
*[British] Lobbying giant filmed offering reporter payment for flattering client coverage in national press.*
Jerusalem’s most sensitive holy site [Richard Stallman's Political Notes]
Right-wing Israel extremists seized the al Aqsa mosque in Jerusalem.
The concept of "sacred" presupposes some sort of superhuman entity that can impose "sacredness" on places or things. There is no evidence for such entities exist — no evidence that anything is "sacred" except in the thoughts of humans. That kind of Psychosocial "sacredness" clearly does exist; we can observe it. But it doesn't pre-empt the rights or wishes of anyone else.
In general, when some people want to consider a certain object or place as "sacred" and treat it in a special way, I treat it like doing the same actions in the same place for any other reason. I wouldn't object unless there is some specific problem or issue that affects society, or mistreats people other than them, and mostly there isn't one.
"Sacred" places in and near Jerusalem are a very unusual case. Various groups claim various "sacred" spots, for understandable historical reasons, and those claims conflict. A settlement was made decades ago, perhaps by some colonial power such as Turkey or Britain, and all parties have since followed that settlement for the sake of peace, including Israel. However, in the past few decades violent right-wing extremists began using them as opportunities to agitate and radicalize, until they got power over the Israeli government.
There are many reasons to reproach those extremists, and to put them on trial. This assault is one more. In moral terms, they regularly do worse things, such as stealing Palestinians' land,
olive trees, sheep, and houses, jailing and torturing them,and killing them.
But this could trigger a bigger disaster — it seems calculated to stir up war with Muslims who are otherwise inclined towards peace, and to perpetuate and increase the war with Iran.
New York Times leak [Richard Stallman's Political Notes]
*The real aim of [the bully]'s New York Times leak investigation is to punish reporters.*
A Report You Need to Read [Richard Stallman's Political Notes]
Evidence and admissions demonstrate that the deportation thugs have followed a systematic policy, ordered from high up, of fabricating false accusations of crimes against protesters, journalists, and observers of their actions.
02:28

let's see what happens
01:14
Windows NT got its name from one of Intel’s failed x86 replacements [OSnews]
Dave Farquhar published an article today about Windows NT 3.1’s place in the market when it was originally released, and while the article is interesting and a fun read, it does mention this:
[…] Microsoft took its nascent code that it intended to form the base of OS/2 3.0, renamed it Windows New Technology, and eventually released it as Windows NT 3.1.
↫ Dave Farquhar
While Microsoft did, in fact, use the “New Technology” branding as a marketing trick, this is not what “NT” originally stood for. Two developers from the original Windows NT development team, Mark Lucovsky and David Thompson, explained all the way back in 2003 that “NT” came from the codename for Intel’s then-new RISC platform, the Intel i860 (Raymond Chen confirmed the veracity of their story). The i860 was the first target platform for Windows NT, and it was codenamed “N-10” – NT.
Finally, it was time to start writing some code. “We checked the first code pieces in around mid-December 1988,” Lucovsky said, “and had a very basic system kind of booting on a simulator of the Intel i860 (which was codenamed “N-Ten”) by January.” In fact, this is where NT actually got its name, Lucovsky revealed, adding that the “new technology” moniker was added after the fact in a rare spurt of product marketing by the original NT team members. “Originally, we were targeting NT to the Intel i860, a RISC processor that was horribly behind schedule. Because we didn’t have any i860 machines in-house to test on, we used an i860 simulator. That’s why we called it NT, because it worked on the ‘N-Ten.'”
↫ Paul Thurrott
The i860 was one of Intel’s many attempts over the years to replace x86 with something more modern, but – as would become tradition with Intel and attempting to replace its x86 architecture – it suffered from endless delays, missed targets, and lacklustre performance. It saw only sporadic use in the market, and ended up on the chopping block after only a few years. Intel tried to replace x86 again soon after with Itanium, which suffered an identical fate.
Still, the engineers working on the i860 platform in the late ’80s and early ’90s at Intel can at least take some pride in that to this day, the most popular desktop operating system in the world got its name from the product they developed. Intel’s i860 might barely even be worthy of a footnote today, but billions of PC users log into their Windows “N-10” machines every day, unwittingly carrying a torch for the failed x86 replacement.
Monday, 27 July
23:28
BTW, I had no idea the WordPress connection was coming and here it is.
22:42
A Wolv In Creep's Clothing [Penny Arcade]
The fan-favorite, canonically 5'3" mutant called Wolverine has been next in line for The Insomniac Treatment for a while, having been announced in September of '21, a year I will admit to not remembering entirely. As it approaches, we've been buffeted by new video clips of Wolverine's clothing being deliciously flensed just this side of mutant homoerotica, and a picture of his face that makes him look like an escapee from Roblox.
22:07
Dirk Eddelbuettel: #057: Conditionally Quieten Compilers [Planet Debian]
Welcome to post 57 in the R4 series.
R packages with compiled codes can use the file
src/Makevars to set compilation flags. We often rely
on this to set libraries, include directories or compilation
options. When using external libraries, be it header-only or via
headers and linking, we are often experiencing ‘compilation
noise’ when these libraries tickle warnings under
generally-recommended flags such as -Wall -pedantic.
Two packages I maintain are clearly repeat offenders here: Eigen,
and BH. Both cam generate pages and pages of compiler output. This
is generally not great as it may hide genuine warnings from our own
code.
What makes matters worse is that some of the available and
specific options for the compilers are treated by R CMD
check as ‘non-portable’ leading to a nag on
package checking. Examples are -Wno-parentheses,
-Wno-maybe-uninitialize or
-Wno-nunnull.
I have long resorted to adding these to my per-user
~/.R/Makevars. When added there, compilation is
quieter, but R CMD check still nags here
where the option is set but not at CRAN or r-universe. A situation
that is not ideal but what somewhat ‘stable’.
More recently, I realized there was an available check we can use to conditionally add extra compilation flags but leave them off by default. That makes local development quiet allowing us to focus on the quality of our additions here without noise from third-party libraries we may use. At the same time we do not need to do anything else to let CRAN do its work.
The check we now use is whether there is a .git/
directory present. If so, we are indeed building from local sources
and can add extra flags. If not, we are likely building from a
tar.gz source archive—which is the case for CRAN—and
hence do not set these.
An example use is this recent additional to package qlcal where this bit of R
code is invoked from a minimal shell script configure
and replaces the stub @XTRAFLAGS@ in
src/Makevars.in (or
src/Makevars.win.in)
if (dir.exists(".git")) {
## development from a .git directory can use these flags
xtraflags <- "-Wno-nonnull -Wno-deprecated-declarations"
} else {
## else build from tarball so stick with existing flags
xtraflags <- ""
}
win <- if (Sys.info()[["sysname"]] == "Windows") ".win" else ""
infile <- file.path("src", paste0("Makevars", win, ".in"))
outfile <- file.path("src", paste0("Makevars", win))
lines <- readLines(infile)
lines <- gsub("@XTRAFLAGS@", xtraflags, lines)
writeLines(lines, outfile)
With this change, local compilation is quiet, yet CRAN has nothing to nag about (as seen at the qlcal results page).
Similarly, one can also check from an actual
configure file written in autoconf. Here is a similar
example from RcppEigen (showing some relevants parts of the whole
file)
# PKG_CXXFLAGS initialized earlier ...
## Check if building locally
AC_MSG_CHECKING([whether .git/ exists])
if test -d "$srcdir/.git"; then
AC_MSG_RESULT([yes, adding extra flags])
AC_SUBST([PKG_CXXFLAGS],["${PKG_CXXFLAGS} -Wno-ignored-attributes -Wno-maybe-uninitialized"])
else
AC_MSG_RESULT([no, consider adding '-Wno-ignored-attributes -Wno-maybe-uninitialized' to ~/.R/Makevars])
fi
AC_SUBST([PKG_CXXFLAGS], ["${PKG_CXXFLAGS}"])
AC_CONFIG_FILES([src/Makevars])
AC_OUTPUT
Once again, with this change compilation is quiet locally, yet unaffected at CRAN. Just what we want. Give it a try in your packages.
This post by Dirk Eddelbuettel originated on his Thinking inside the box blog. If you like this or other open-source work I do, you can now sponsor me at GitHub.
Jonathan Carter: DebConf26 – Santa Fe, Argentina [Planet Debian]

TL;DR: What a great DebConf! I managed to recharge my Debian batteries, and my talks / BoF sessions all went fine. Already looking forward to DebConf in Japan next year!
DebCamp
The evening before DebCamp started, we had a nice bbq (we taught some locals to call it a “braai” at an organiser’s house and went for a walk around the river as the sun set. It was a very peaceful lead-in to DebCamp.


- I set up and sent out the call for Forky desktop artwork:
- Had many nice discussions about various Debian topics with all the Debian people around. It’s really fun being around people who are natural problem solvers who care deeply about both technical and social issues. At one point Jonas told me “Holy shit, these people are motivated!” and I appreciate that so much too!

Debian LTS wine
- Most of my DebCamp was dedicated to preparing for my demo and main talk that followed at DebConf.
- Sadly, we had no loopy this year, I just didn’t have the time, and the people who stepped up to help last year were either overwhelmed with other issues or couldn’t make it. I’ll try to make it happen again for next year by kicking it off long before DC27.

View of Santa Fe city from hotel
DebConf
Talk – Is it even possible to build a truly universal system installer?
In this talk I do a very quick comparison of system installers based on my experience with them. It’s hard to directly compare all of them, since there are so many, and each have their own niche that they attempt to satisfy.
I also introduce Yasi – my attempt to answer the question of whether we could build a universal installer, which can also better cover advanced installations, automated installations and niche setups.
It’s very early days for the project, and I didn’t quite feel ready to share the code with the world, but it was nice that I did a quick demo where I could install a Debian system… and the resulting system actually booted up. *phew*.
This is also going to be my main focus for the mid-term future. I aim to have all the basic partitioning options working by the time Debian 14 (Forky) is released, and by the time Debian 15 is released, I have a long list of features that I aim to have working. So, my timeline for having something that’s generally useful is around a year from now, and in around 3 years it should be a fully fledged installer that should cover a very large amount of Debian use cases and architectures.
Day Trip
For the day trip, we did a tour across Santa Fe, visited Constitución de la Nación Argentina, had lunch where we tried various dishes based on local fish from the river, and then went on a boat ride on the river.



BoF Sessions:
Funding in Free Software Projects: I initially registered this BoF because I’m increasingly concerned about how upstreams are asking for donations in their software. I increased the scope to talk about funding in free software in general. It followed Marga’s talk about funding, which focussed more about how developers are funded in general. We didn’t dive very deep into this, but we certainly need some further discussion (and action) on this within Debian.
Debian Social Team: My most important issue for this team is a carry-over from last year, I want to set up barman (packaged in Debian) for live postgres syncing for our larger databases. For the smaller DBs, doing a daily dump is quite cheap. But for Matrix, it’s very expensive in terms if i/o and CPU, so it would be ideal to do less regular complete dumps and use live replication for the first line of redundancy instead.
Images Team: I wasn’t initially planning to say much during this session, I have some ideas to reduce both size and count of images, without losing any benefits, but I don’t have any work to show for that yet. I ended up talking a lot more than I anticipated, the topics covered were quite good and representative of the current state of Debian images built. I don’t have time to create a full summary, so I suggest checking the etherpad / video recording if you’re interested.

Some more wine variety during the conference dinner

Debianites in the main hacklab
Rosario

I’m spending two days in Rosario before I head home. Exploring a bit, catching up with sleep, finishing this blog post, signing keys and exploring some ideas I made note of during DebConf.
Thank you to the DebConf26 Team!

It was a little surreal not being part of any DebConf team for the first time ever, I’ve just been too focussed on getting Yasi ready for my talk (no regrets!). I hope to be more involved again next year, in the meantime, I’m very grateful to everyone who has made this happen, you did a stellar job! I hope to see many of you again next year in Japan!
21:56
AI Demands More Engineering Discipline, Not Less [Radar]
The following article originally appeared on Charity Majors’s Substack and is being reposted here with the author’s permission.
A few days back I wrote a piece called “AI enthusiasts are in a race against time, AI skeptics are in a race against entropy.”
I have notes on a whole pile of
AI-related topics that I’d like to cover in depth: AI
mandates, communication norms, code review, AI art, and more.
Unfortunately, I got too many interesting responses to my last
piece, and now I have to address those before I can move on to
other topics. 
There were two types of interesting responses: the first on the technical merits, the second on ethical grounds. I will respond to each of these separately. Let’s take the technical side first, because it’s easier.
Somehow, a subset of readers came away believing I was telling everyone to ditch code review and push their shittiest code straight into production without reading it, right now, tout suite.1
That is not what I am doing. That is not what I think you should do. But I did not pick that example at random, and I will tell you why.

In 2025, the question was whether AI could ever generate “good” code
It’s easy to forget, but for most of 2025, the idea that AI-generated code was slop and might always be slop was not only a reasonable position to hold, it was the default, mainstream position.2
That question was answered decisively last November. Ever since Opus 4.5 came out, AI has been able to generate code that is approximately as good as that of the median software engineer, at least for common patterns, and much faster and more cheaply. I came out of a book hole and realized this in January, and over the first few months of 2026, it seemed like everyone around me was having a similar realization.
But many saw it coming much sooner.
The popular narrative holds that Opus 4.5 was what changed. But Opus 4.5 was more like the tipping point. Agentic harnesses (the code that wraps the LLM in a loop with tools) became a real thing in mid 2025, with precursors building back to late 2024. Tool use, function calling, MCPs…all of this wave was building over the course of 2025, and crested into real general purpose usability at the end of the year.
That’s what the enthusiasts were trying to tell us last year. Not only “this is coming”, but “this is coming faster than you think.”
As it turns out, they were right.
It was reasonable to be skeptical the first time
As you may know, I come from the reliability side of the house. The compliment I will pay to myself and my people is that we do not struggle to adapt to new realities. As soon as a problem is real and in front of us, we adjust smoothly, even eagerly, thanks to an unwholesome zest for lapping up disgusting technical messes (and the campfire tales we get to tell later).

The un-compliment I will pay myself and my people is that we sometimes struggle to accept that progress is real, that the continued existence of bugs and edge cases does not diminish the fact that huge swaths of problem space do get more-or-less solved over time, to the point they can be taken for granted by most people.3
The speed at which code went from total crap to “ah damn, that’s not bad” is what I have in the back of my mind, as enthusiasts are telling us that harness engineering and AI validation is real, it’s already here, and it’s getting better astonishingly fast.
Holding out for “I’ll believe it when I see it” was forgivable the first time, but much less so the second time. This is what it feels like to be on the inside of an exponential change curve, turns out.4
What happened in 2025, exactly?
I want to pause here and be very clear about what I think is happening. Then I’m going to tell you what specifically I am excited about, and why.
You are under no obligation to join
me there. But there are way too many sweeping statements out there
right now about “it was never X”—“it was
always Y”—“the future belongs to xyzzy”
 —and I want to be crystal clear how
conditional and specific and contextual my claims are.
—and I want to be crystal clear how
conditional and specific and contextual my claims are.
What happened in 2025 was this: the economics of code production were turned upside down. Instead of being very hard, time-consuming, and expensive to generate code, it became effectively free and instant. Lines of code went from being treasured, reused, cared for and carefully curated, to being disposable and regenerable, practically overnight.
For most of computing history, the primary way people have learned to understand software is by writing the code. Once you’ve achieved some mastery, reading and discussing code gets you most of the way there. (I might argue that software engineers have always relied far too heavily on the code instead of sensemaking the system through observability.)

“The real product of a software team is shared understanding”
Many great software engineers hold that true product of every (good) software engineering team has always been a shared understanding of the software we own. That it gets stored as cache state in our fragile little meat brains, frequently flushed to disk, deployed to production, committed to github, but our minds are where meaning has always lived.
Is it any wonder that software has always been such a fiercely collectivist endeavor, exquisitely sensitive to relationship dynamics and manners and questions of fairness and emotional valence? It’s exactly what you’d expect when part of your brain lives in other people’s brains, and your collective interdependence is sky high.
It’s something that I love about this industry. But there’s no denying that minds have been a poor container for certain aspects of the software development model. We are forgetful, distractible, impatient. We are bad at spotting small details, we grow habituated to repetition. Worst of all, the model in our heads diverges massively and perpetually from the world our users interact with.
Anyway, SREs have never quite bought that explanation. To us, it’s clear that the true product of every (good) software engineering team is production.
Only prod is prod. Test in prod, or live a lie.
(This is all backstory. I am getting to the point, I promise.)
Turns out, this is an engineering problem after all
We issued our AI mandate last August.5 I had seen enough to know that this was happening, and it was time to do the responsible thing. Honeycomb is a devtools company, and people come to us to help with hard problems on the forefront of technology. I was all in on AI, but I can’t say I was super excited about it, in my heart of hearts.6

Then I found Chad Fowler’s writings on Phoenix Architectures.
If you don’t know what I’m talking about, you should honestly stop reading my shit right now and go read his. Chad is the guy who coined the term “immutable infrastructure” in 2013. His best-known essay is “Relocating Rigor”, because Martin Fowler7 mentioned it recapping a Thoughtworks meetup on the future of software. I replied with “Production Is Where the Rigor Goes”, complaining that they didn’t talk about production enough.
When I wrote that, I think “Relocating Rigor” was the only piece I had read. But soon I found the rest of it, and after reading two or three essays, it just clicked. I knew exactly what he was talking about. I could predict the rest of what he was going to say. And then, reader…then I got excited.
This has all happened before, and this will all happen again
I am going to give you a small sample of Chad quotes, just enough to get the gist. Here’s one from “The Death and Rebirth of Programming.”
Immutable infrastructure. Stateless services. Containers. Blue-green deployments. Infrastructure as code.
These ideas all share a common premise: never fix a running thing. Replace it.
AI pushes this premise beyond infrastructure and into application code itself. When rewriting is cheap, editing in place becomes risky. Mutation accumulates entropy. Replacement resets it.
Another favorite: “The Deletion Test.”

Here’s a simple test you can apply to any software system you work on:
Imagine deleting the entire implementation.
Most engineers experience deletion as existential. Code feels like the thing. It’s what we write, review, version, deploy, and debug. Losing it feels like losing the system itself.
When people say, “We can’t just throw the code away,” what they usually mean is something more precise:
- We don’t know exactly what behavior is required.
- We don’t know which failures are unacceptable.
- We don’t know what invariants must always hold.
- We don’t know how to tell if a new version is correct.
- We don’t know which bugs are intentional fixes for forgotten edge cases.
Those are not code problems. They are evaluation problems.
Code becomes precious when it is the only place knowledge lives.
and,

For most of software history, treating code as durable was reasonable.
We treated code as permanent because the labor to produce it was the bottleneck. Rewriting was expensive. Re-validation was risky. Implementations accumulated meaning over time. Structure, tests, comments, bug fixes, and tribal knowledge fused into something you learned not to disturb.
That made sense when production was the constraint.
When regeneration is easy, code stops being an asset and starts acting as a cache: a materialized view of understanding that is useful while current, disposable when stale.
“A materialized view of understanding that is useful while current, disposable when stale.” I think that might have been the exact line that made it click in my head.
Do you remember the sysadmins?
I am just barely old enough that my first job title was “System Administrator.” I was a teenager, working at the university, with root on every machine in the days before they learned they should definitely not do that.8
I lived through the shift from handcrafted server pets to immutable infrastructure cattle. I didn’t really understand what was happening at the time, but I’ve contemplated it a lot in recent years. I wrote this in the final chapter of Observability Engineering, 2nd edition (now available, download here!):
The shift from handcrafted servers to immutable infrastructure taught us that mutability is the sworn enemy of understanding. Any artifact that is edited in place creates drift. Drift is what makes systems impossible to maintain.
Our ability to kill and regenerate infrastructure components is the reason we trust it. At Honeycomb, we kill the oldest Kafka node off via cron every Tuesday. That’s why we are confident in our bootstrapping and balancing processes: everything is repeatable, the data can be regenerated, the commitments live elsewhere.
The fact that we cannot regenerate our code in the same way is a sign that we do not understand it. We do not know which commitments we have made, we do not know which dependencies will break. We find them by breaking them, mostly.

Think of all the years of your working life you have wasted on painful migrations and rewrites. Think of replacing load-bearing legacy code. Think of all the strangler figs.
Lines of code have been doing too much. The code has been the bundled up repository of developer intent, user expectations, implicit and explicit behaviors, the only fossilized composite record we have of bugs gone by. It’s too much!
Lines of code are not the ideal artifact to review
And look at all the domains that have been neglected due to the towering, all-consuming expense of maintaining and mutating lines of code. Where are the artifacts I can review and discuss to understand how our architecture is evolving? Where are our architecture artifacts, period? What if we could discuss and converge on an architecture diagram, and the code could be regenerated from changes to the architecture, instead of the architecture being kinda-sorta inferred from the code?
I am not asserting that all code will eventually be AI-generated to spec, bypassing human understanding. The feasibility of this whole endeavor hangs on the question of what a spec is, or what a spec could be. Anyone who has ever done a painful database migration should have learned some goddamn humility about our ability to extract and formalize users’ expectations in a replayable, automate-able way.
But I think that every step we can take in that direction will be good for us.
The tools to do this don’t exist yet, but many of the ideas do exist. Most come from operations and QA, two domains that software engineering has historically been rather snobbish about.
Those tests and techniques are not about testing for correctness or what ought to be happening, they are about observing and encoding what is happening. Behavioral tests, characterization tests, capture/replay, traffic splitters. Observability (the good kind).

Our brains were not built for validation
Having nondeterministic code in production is finally forcing us to do the things we should have done all along. Instrumenting with traces. Tests and evals in production. Production is not what happens after development is over, production is a stage of development.
Human brains are not good at validation. The nitpickiness, the repetition. This is the worst thing to be clinging to, y’all. There are so many better things for us to want to preserve and assert for ourselves in the production and maintenance of software. We are never going to beat the machine when it comes to validation—we are literally the weakest link!
My money’s on humans for a good
long time when it comes to creativity, inspiration, leaps of logic,
and a lot of other things, but PLEASE do not rest your killer
argument for humans in software on us being the best quality
gate. OMG. 
Alright. I’m almost done here. Just one more thing.
Nondeterministic systems will require more engineering discipline, not less
I think what many engineers have found so alienating and terrifying about the last two years of AI discourse has been the way so many prominent AI voices appear to be gleefully declaring that software is no longer an engineering problem. “SaaS is dead!” “Making AI great at coding was the strategy that unlocks everything else”, and so on. Even Adam Jacob, one of my dearest friends and someone who is rarely wrong about technology, seems to anticipate a bloodbath of software jobs.9
If 2025 was the year of vibe coding, where AI got as good at generating lines of code as the median software engineer, and the range of possible futures often felt destabilizingly, impossibly wide open, I feel like 2026 is shaping up to be a return to discipline.

The knowledge in our heads is unavailable to AI until we encode it into the system, after all. The returns on those investments will be massive and nonlinear. We might argue that they always would have paid for themselves in the long run. But now every CEO in existence is chomping at the bit to get some of those AI cookies, so let’s give it to them. Discipline first, cookies second.
This is our chance to bring our engineering values to the mainstream
The share of software engineering teams that work in short, fast feedback loops (the cardinal sign of discipline in my book) is, and always has been, appallingly small. Five percent, maybe? Definitely less than 10%. AI tooling brings this more within reach than ever before. Or it can. It could. The discontinuous returns on investment in engineering discipline are real enough that it just might happen.
I am not worried, at least in the near term, about AI creating massive, discontinuous returns on investment in the absence of engineering discipline. (Many will try, and it will be entertaining to watch.)
But value is backed by durability, not disposability, and I don’t see that changing. Bits are cheap and fast and governed by the rules of logic and language, but anything with value must ultimately resolve with physical systems: persistence on the one side, user experience on the other.
People do not want to wake up every day and log in to Slack and find the buttons and menus all subtly moved around. People do not want financial transactions that complete most of the time. Determinism is not going anywhere, my friends.
AI is not magic. This is still engineering. As Adam says, “it’s still technology, and technology needs technologists.” And I for one am looking forward to learning new and interesting engineering problems, reviewing different kinds of artifacts.
And never doing another sticky, picky, two year long API rewrite or strangler fig migration, ever, ever again.
~charity
P.S. Thanks to everyone who read a draft and gave me feedback: Dave Williams, Chad Fowler, Adam Jacob, Mark Ferlatte, Austin Parker, Erwin van der Koogh.
Footnotes
- I was not
trying to be neutral or even-handed in my last piece, only
to give a baseline of courtesy to everyone. But I think it’s
revealing how many times I was accused of being “so overly
hard on skeptics”, by skeptics, and “so overly hard on
enthusiasts”, by enthusiasts, and sometimes simply
“It’s sad how some people can’t accept
reality” with no indication which side they meant. Lord.
︎
- Fred Hebert and I
gave the closing keynote at
SRECon in March of 2025 where we told SREs they should get to
know AI, maybe even try vibe
coding (pause for laughs), because otherwise their critiques
wouldn’t land as well.
Seriously, that was our big pitch. Learn AI so that you can complain more effectively.
︎ - Infrastructure, for
example. I think this is true of a lot of engineers, btw. I just
think it’s really really true of the type of
engineer that signs up to be an SRE. Technological pessimism and
ADHD, our two most defining traits.
︎
- There is a segment of
AI enthusiasts who believe we are entering an era of eternal
exponential growth, in which the machines begin to build better and
better machines, in ways we cannot understand.
I think those people are bad at math. The only thing we know for certain about exponential growth is that it will end. It always does. either in an S curve or a crash. (For a good time, google Heinz van Foerster and “our great-great grandchildren will be squeezed to death.”)
I definitely think we will use machines to build the machines—duh, we already are—but that’s about recursion and specialization. I think the exponential curve we are on the inside of now was created by sloshy free money chasing high returns, plus the properties of software as a function of language and logic, plus the biggest discoveries always happen in the early days of a technology boom, because low hanging fruit gets picked first.
My personal sense—and keep in mind that I am no kind of expert on AI—is that the exponential advancement in AI models leveled out a while ago, and gains are becoming harder to earn and more incremental in nature. I may turn out to be very wrong, of course. But even if there were no more AI innovations moving forwards, the past year has unleashed enough pent-up force to radically reshape the software industry as we know it. Like a pig in a python, we will be dealing with the consequences for a long time to come.
︎ - More on this coming
EXTREMELY soon. Watch the Honeycomb blog!
︎
- The tech is cool, but
as a thinking, feeling, breathing human who cares about other
people, it can be hard to get excited about anything that so many
people are this upset about. It’s also hard to get excited
about something when so many of the loudest voices are out there
talking gleefully about putting everyone permanently out of work,
and so many artists and writers and people from developing nations
are talking openly about the impact on them.
Hold your desire to jump in and berate me here, I beg you. Like I said, I will deal with the ethics and morality of using AI in my very next post. Be honest, your attention span is no more up for reading a 10,000-word essay than mine is up for writing one. (Can we blame AI for that too?)
︎ - “The Other
Fowler.” I gather they’ve been making this joke for
like… fifty years.
︎
- I share a longer
version of this story in the second edition of Observability
Engineering, chapter 32,
downloadable now!!”
︎
- Adam is rarely wrong
about technology, and I am 100% sure he is living and working in
_a_ future of software engineering. I am less sure it is
the future we will all be living in. If the hardest part of
software has never been writing code—as is my belief—it
logically follows that even if the economics of code production
drop to zero, the hard parts will still be hard.
︎
21:49
Joe Marshall: Vibe Coding Reconsidered [Planet Lisp]
A year ago, you couldn't vibe code in Lisp. Even the SOTA models had trouble balancing parentheses, and they'd hallucinate packages and symbols that didn't exist. A year makes a big difference in this field, and the latest models are capable of vibe coding moderately sized programs in syntactically correct Lisp.
I have been experimenting with vibe coding in Common Lisp and I'm hooked. It is a blast. It is like having on hand a talented undergraduate who just took a Lisp course. If you give him small enough, focused tasks, he will churn out passable code. If you give him a good chunk of legacy code, he will churn out more code in the legacy style. The models are not good enough to do a full rewrite of a large codebase, but they are good enough to handle a small library with supervision.
I find myself accepting a large amount of code with just a glance—if it passes the Lisp reader, compiles, and the tests pass, I accept it. Unlike the code of a year ago, the generated code these days is far less buggy, and the models are pretty good at debugging their own code. I'll do spot checks on the code, but I don't bother reading it line by line unless I see something odd. If the model generates code in a style I don't like, I'll ask it to rewrite the code to be more to my liking.
But frankly, you don't need to read the code at all. If there is a good test suite, the model will generate code that passes tests. If the code is functionally correct, it doesn't matter if the code is pretty. In one way, it doesn't matter if the code is easy for a human to read and maintain because we ask the model to maintain it. We treat the code as a black box and we constrain it to pass the tests. (We accept machine code largely unread.)
Failure Modes
By far the most common failure mode is the model getting the number of closing parentheses wrong. The tail end of a block of code is usually a bunch of closing parentheses, and the model will be tokenizing them in groups of 2 or 3. But the likelihood of the "))" token isn't very much different from the likelihood of the ")))" token, so the model will sometimes grab the wrong one.
Depending on the model and the agent, when it tries to recover from the ensuing read error, it will re-compute the tokens in the output. It sometimes will thrash as it tries to balance parentheses, adding and removing them from various places in the code. (Sort of like a noob Lisp programmer.) Some models are more susceptible to this than others. I have found that the solution here is to pause the agent and manually fix the parentheses when the agent starts to thrash.
Vibe Coding Workflow
I've been using Copilot CLI and Gemini CLI to vibe code in Common Lisp. I start with a blank project directory and create an .asd file that loads the packages.lisp file and the main file for the project (which can start out as a "hello world"). Basically, make a minimal project that you can load with ASDF or Quicklisp.
The models can work at moderate levels of abstraction, but they do better if there is existing code supporting the abstraction level, and this suggests a `bottom-up` approach to the problem rather than a `stratified` design. But the models are actually quite capable of starting at a moderate level of abstraction right from the get-go.
So starting with a minimal project, I boot up the model and ask it to write the first things needed for the project—some data structures, some utilities, a few tests. The very simple stuff that is easy for the model to do ab initio. Then I ask the model to write a minimal main function that will implement the basic functionality of the project—a command loop, a server, what-have-you—with stubs for everything. Once a framework is in place, the models are easily able to extend it.
The agents will get into a loop of adding code, adding tests, and running all the tests. They will debug any test failures and only consider a task to be complete when all the tests pass.
The model does not write great code, and you will accumulate technical debt if you accept it as is. But the model can write code that works and passes the tests. It is a good idea to pause during development and simply ask the model to find the technical debt in the code, enumerate it, and rank it in order of importance. Then you ask the model to address each item in turn and the model will clean up the code. After a couple of iterations of cleanup, the code will look no worse than what I've seen in many professional codebases.
There are sort of two modes that you operate in: one is to modify the existing code (e.g. refactor) without disturbing the functionality; the other is to extend the functionality without disturbing the core operation. It is important to spend enough time refactoring and cleaning up. But the model is good at generating potential refactorings, and it is not good at knowing when to call it quits. It will happily churn away at your code making it `better' and doing more and more trivial refactorings. If you give the model one particular refactoring task and tell it to do just that one, it will do a good job.
Refactoring is satisfying in a certain way, but adding features gives you more instant gratification. The models are good at adding features and extending existing code, especially if the feature shares any similarity with existing code.
For more complex features and refactorings, tell the model that you want a 'plan' for the feature or refactoring. The model will come up with a multi-step plan, broken down into a series of tasks. The tasks in the plan are generally small enough to be handled by the model itself.
The models are good enough to maintain a codebase, so once you have a project up and running, the model will generally choose file names and a directory structure that is appropriate to put in the .asd file. If you get the model started with a test suite, it will extend the tests as it extends functionality, or you can ask it to add specific tests.
I have found that building a project by vibe coding it is an extremely rapid way to prototype. The model can churn out `obvious' code much faster than I can and it frees me up to think about the higher level design issues. I can build in a weekend what would have taken me a month before.
21:21
Making an agile version of a Windows Runtime delegate in C++/WinRT, part 6 [The Old New Thing]
It looked like we were done when we fixed the problem of releasing a non-marshalable delegate on the correct thread.
But we missed something.
Again.
if (d.try_as<::INoMarshal>()) {
void* p;
if constexpr (std::is_reference_v<Delegate>) {
p = winrt::detach_abi(d);
} else {
winrt::copy_to_abi(d, p);
}
return
[p = std::unique_ptr<void, in_context_deleter>(p),
token = get_context_token()](auto&&...args) {
if (token == get_context_token()) {
std::remove_reference_t<Delegate> d;
winrt::copy_from_abi(d, p.get());
d(std::forward<decltype(args)>(args)...);
} else {
throw winrt::hresult_error(CO_E_NOT_SUPPORTED);
}
};
}
The first part gets a raw ABI pointer, either by moving it out of the inbound delegate if we can, else by copying it from the inbound delegate. The reference count is owned by the raw pointer.
The second part wraps the raw ABI pointer inside a
std::unique_ptr with our custom deleter. The unique
pointer now owns the reference count, and the custom deleter will
release it.
The problem is that one of the requirements for a custom deleter
is that if you use the unique_ptr(p) constructor, the
custom deleter must not throw an exception at construction.
[unique.ptr.single.ctor]
constexpr explicit unique_ptr(type_identity_t<pointer> p) noexcept;Constraints:
is_pointer_v<deleter_type>isfalseandis_default_constructible_v<deleter_type>istrue.Preconditions:
Dmeets the Cpp17DefaultConstructible requirements, and that construction does not throw an exception.
But our custom deleter could throw an exception if
CoGetObjectContext fails. So it
doesn’t meet the preconditions.
We can fix that by using the constructor that takes an explicit
deleter from which the stored deleter can be move-constructed. If
an exception occurs, it happens during the creation of the
parameter and not inside the unique_ptr
constructor.
if (d.try_as<::INoMarshal>()) {
void* p;
if constexpr (std::is_reference_v<Delegate>) {
p = winrt::detach_abi(d);
} else {
winrt::copy_to_abi(d, p);
}
return
[p = std::unique_ptr<void, in_context_deleter>(p, {}),
token = get_context_token()](auto&&...args) {
if (token == get_context_token()) {
std::remove_reference_t<Delegate> d;
winrt::copy_from_abi(d, p.get());
d(std::forward<decltype(args)>(args)...);
} else {
throw winrt::hresult_error(CO_E_NOT_SUPPORTED);
}
};
}
Okay, so now we’re done?
Nope, still broken.
More next time.
The post Making an agile version of a Windows Runtime delegate in C++/WinRT, part 6 appeared first on The Old New Thing.
20:35
Missed EFF's Livestream with Adam Savage and iFixit? Listen Here! [Deeplinks]
EFF’s first EFFecting Change livestream was all the way back in July of 2024. Maybe you've caught each stream, or maybe you’ve only caught a few. Or maybe you’re like me and prefer to listen to conversations like these on your daily commute! Either way, if you want to stay on top of these monthly conversations, you can now subscribe to our new podcast feed for EFFecting Change—starting with our conversation on the Right to Repair movement with Adam Savage and iFixit CEO Kyle Wiens:
![]()
![]()
![]()
This new feed will include the full conversations with our panelists, posted after the livestream ends. Subscribe today to get each stream straight to your podcast player of choice. You can also find other podcasts by EFF at eff.org/podcast.
And mark your calendar for the next EFFecting Change livestream: Who the Machine Serves. EFF Executive Director Nicole Ozer and Cory Doctorow will be having a conversation on AI, tackling what needs to happen now to ensure AI actually works for everyone, not just those in power. RSVP today!
Want to ensure EFF can keep inviting expert panelists to chat about the future of technology and how it impacts you? Support our work today.
The Fedora 45 sausage factory [OSnews]
This is a walkthrough of how Fedora turns source code and packages into the artifacts you download and install. It follows the a package from a packager’s git push to a composed release: ISOs, cloud images, container images, and OSTree deployments.
↫ Simon de Vlieger
Linux distributions – good ones like Fedora, at least – are really complex operations, with a ton of checks and balances to ensure no git push eventually ends up causing problems on individual users’ machines way down the line. The fact so many people involved in this complex web of processes also happen to be volunteers doing all of this out of the goodness of their hearts is amazing. Of course, this doesn’t just apply to Fedora, but also the countless other distributions out there, especially those not owned by some giant corporation like IBM.
If you’re just a casual Fedora user, there’s really no reason you have to know or be aware of any of this, but it’s still fun and interesting to understand the inner workings of your distribution of choice.
Comanche: Maximum Overkill from 1992 does weird things on Intel processors [OSnews]
Let’s do another article about weird code in video games.
The original 1992 Comanche release is extremely picky about memory managers. The game refuses to work with EMM emulators and crashes when EMM386 is active. The game may also hang or reboot the system when HIMEM.SYS is not loaded (the problem seems to be system configuration dependent).
These issues are clearly noted in the Comanche documentations, but at the same time they’re also all signs of a substandard DOS extender.
On top of that, the game authors accomplished a remarkable feat: By only loosely following Intel’s instructions on how to enter protected mode, NovaLogic managed to write a game which worked on the then-existing 386 and 486 processors, but under some circumstances failed to run on Pentium and later processors.
↫ Michal Necasek at OS/2 Museum
As usual, a great read from Michal Nacesek.
19:35
This is something. WordPress now supports RSS.chat in an interesting way, and it's surprisingly deep. Once it's cross-posted a message to RSS.chat, any comment in response will be cross-posted to the comment thread on RSS.chat and vice versa. What's great about this is that you never can tell what people will do when you are on the web. Matthias is a friend, I was on his podcast last year. If people use this connection and see how it works, then we'll get an idea of where to go next.
Of course we have a feed for RSS.chat updates.

18:21
[$] Hazard pointers for the kernel [LWN.net]
The kernel's read-copy-update (RCU) subsystem ensures that data will not be deleted until it is known that there are no threads holding references to it. RCU works well and is widely used throughout the kernel, but it can increase memory use and add significant delays before unused kernel objects are cleaned up. Hazard pointers are an alternative approach to lockless data updates that offers better performance, for some situations at least. The kernel community is currently considering a hazard-pointer implementation by Mathieu Desnoyers and Paul McKenney.
18:07
 How
we document APIs. We did a lot of work on API docs this
morning. Claude had done a draft, which we published, and turned
over to users, and on review realized it was insufficient. That was
the word I used, and rolled up my sleeves, told Claude we're going
to get this stuff right and set a pattern as we go forward. At the
end I asked Claude to summarize what we agreed on, and it's more or
less exactly what I was aiming at. If you're working with Claude on
docs for APIs, I offer this as open source, feel free to point your
Claude at this
doc. I have a vested interest, in my job I read a lot of bad
API docs.
How
we document APIs. We did a lot of work on API docs this
morning. Claude had done a draft, which we published, and turned
over to users, and on review realized it was insufficient. That was
the word I used, and rolled up my sleeves, told Claude we're going
to get this stuff right and set a pattern as we go forward. At the
end I asked Claude to summarize what we agreed on, and it's more or
less exactly what I was aiming at. If you're working with Claude on
docs for APIs, I offer this as open source, feel free to point your
Claude at this
doc. I have a vested interest, in my job I read a lot of bad
API docs.
16:49
The GNU C Library version 2.44 is now available [Planet GNU]
The GNU C Library
=================
The GNU C Library version 2.44 is now available.
The GNU C Library is used as the C library in the GNU system
and
in GNU/Linux systems, as well as many other systems that use
Linux
as the kernel.
The GNU C Library is primarily designed to be a portable
and high performance C library. It follows all relevant
standards including ISO C23 and POSIX.1-2024. It is also
internationalized and has one of the most complete
internationalization interfaces known.
The GNU C Library website is at http://www.gnu. ...
/software/libc/
Packages for the 2.44 release may be downloaded from:
http://ftpmirr ...
.gnu.org/libc/
http://ftp.gn ...
org/gnu/libc/
The mirror list is at http://www.gnu. ...
/order/ftp.html
Distributions are encouraged to track the release/* branches
corresponding to the releases they are using. The release
branches will be updated with conservative bug fixes and new
features while retaining backwards compatibility.
NEWS for version 2.44
=====================
Major new features:
- System-wide tunables can be applied using /etc/tunables.conf and
running ldconfig. Specific tunable settings and
the
/etc/tunables.conf file format and path are not part of the
stable
library interfaces and may change between releases.
- A new tunable, glibc.elf.thp, is added to map read-only segments with
Transparent Huge Pages (THP) if THP is not disabled in
the kernel. When
glibc.elf.thp is set to 1, malloc uses the actual kernel THP
mode
instead of defaulting to madvise mode and madvise_thp will
stop issuing
MADV_HUGEPAGE if kernel THP mode is always.
- The THP page size in malloc is capped to MAX_THP_PAGESIZE. If the THP
page size is above MAX_THP_PAGESIZE, THP in malloc is
disabled.
- Additional optimized and correctly rounded mathematical functions have
been imported from the CORE-MATH project, in particular
cosh, sinh, and
tanh.
- Many additional improvements to existing functions have been synchronized
from the CORE-MATH project.
- For C++26, the assert macro is now variadic, allowing more complex
arguments containing commas (which however still must
evaluate to a single
value).
- The SVID error handling for cosh and sinh was moved to compatibility
symbols, allowing improvements in performance.
- Static PIE is now supported for arm-*-linux-gnueabi. It requires toolchain
support to correctly set the expected linker options.
- On AArch64 targets that support the Guarded Control Stack extension all GCS
operations (including status, write on shadow stack, and
push to shadow
stack) are locked after enabling GCS with ENFORCED or
OVERRIDE GCS policy.
When a GCS operation is locked, a program cannot change this
operation
status via the prctl syscall. This prevents disabling
or corrupting the
GCS shadow stack during runtime.
- On AArch64 targets, log, exp, sin, cas, sinh, cosh, asinh, acosh, atanh
single and double precision special cases have been
vectorized for SVE and
AdvSIMD, and vector variants of powr have been added.
- On RISC-V targets, vector extension optimized variants of memcmp, memccpy,
memchr, memcpy, memmove, stpncpy, strcmp, strchr, strcpy,
strncmp, strncpy,
strlen, and strrchr have been added.
- On PowerPC, memchr optimized for Power10 has been re-added.
- Support for LoongArch32 has been added.
- Pre-built ld.so.cache files can be installed with ldconfig.
- A new locale has been added: hrx_BR (Hunsrik language spoken in Brazil).
Deprecated and removed features, and other changes affecting
compatibility:
- Although malloc and related functions currently return pointers
aligned to alignof (max_align_t), the documentation now
says future
versions of glibc may relax alignment requirements for small
allocations.
For example, a future malloc(1) might return a pointer with
odd
alignment, because no object of size 1 can have a
fundamental
alignment greater than 1.
- The s390-linux-gnu (31bit) configuration is no longer supported.
- The --enable-memory-tagging configure option has been removed.
The corresponding AArch64-specific functionality that was
previously
activated by this flag has been removed as well.
- The --enable-static-nss configure option has been removed. It had no
effect on the build since the NSS reorganization in glibc
2.33; its only
remaining behavior was to suppress the link-time warnings on
the NSS
interface functions in libc.a, which are now emitted
unconditionally.
Security related changes:
The following CVEs were fixed in this release, details of which can
be
found in the advisories directory of the release tarball:
GLIBC-SA-2026-0005:
gethostbyaddr and gethostbyaddr_r may
incorrectly handle DNS
response (CVE-2026-4437)
GLIBC-SA-2026-0006:
gethostbyaddr and gethostbyaddr_r return invalid
DNS hostnames
(CVE-2026-4438)
GLIBC-SA-2026-0007:
iconv crash due to assertion failure with
untrusted input
(CVE-2026-4046)
The following bugs were resolved with this release:
[2363] libc: EOPNOTSUPP and ENOTSUP in errno.h must be
different,
according to SUSv3
[3794] manual: iconv: TRANSLIT and IGNORE feature not documented
[15792] dynamic-link: [arm] ARM dynamic linker should
save/restore
coprocessor registers
[20331] libc: fts ignores errors from readdir()
[20680] dynamic-link: ifunc resolver cannot access the
thread pointer
with static linking
[22944] libc: fts cannot traverse paths which have a length
longer
than USHRT_MAX
[25257] libc: sotruss: fix error message for '--f'
argument
[25770] locale: newlocale memory leak in LOCPATH parsing and
on error
paths
[27582] libc: x86_64: IFUNC in static user programs may
crash when
built with -fstack-protector-all
[28218] dynamic-link: ld.so: ifunc resolver calls a lazy
PLT. When
does it work?
[28817] libc: static-pie ifunc resolver tls failure
[28940] nss: __nss_database_get doesn't check for allocation
failure
[30136] manual: Please document behaviour of iconv(3) when
input is
untranslatable
[30304] nptl: nptl/tst-pthread-gdb-attach test fails with
new libc
shared library version
[30769] malloc: malloc_trim is not working correctly for
arenas other
than arena 0
[30976] dynamic-link: rtld: resolve ifunc relocations
after
JUMP_SLOT/GLOB_DAT/etc
[30992] libc: alpha: setrlimit() with negative values
besides
RLIM_INFINITY returns EPERM
[31901] libc: elf/tst-glibc-hwcaps-prepend-cache fails on
i686
[33226] math: math-vector-fortran.h vs not ffast-math
[33626] libc: execvpe should skip inaccessible $PATH
components
[33650] build: abilist.awk doesn't handle unversioned
defined symbols
[33785] stdio: New streams are linked into global list
before they are
fully initialized
[33848] build: Build fails at openat2.h, redefinition of
'struct
open_how'
[33882] libc: Recursion in nftw() causes stack
overflow(CWE-674)
[33904] build: error: '__vasprintf_chk' undeclared here
[33921] build: Building with Linux-7.0-rc1 errors on
OPEN_TREE_CLONE
[33935] stdio: _IO_wfile_doallocate not linked correctly
when linking
glibc statically
[33980] locale: iconv: ibm139x trigger assertion error when
converting
to internal while lack enough room
(CVE-2026-4046)
[33985] build: ld: cannot find -lgcc_s: No such file or
directory
[33999] stdio: libio: potential dangling _IO_save_base or
memory leak
in wgenops.c
[34006] stdio: libio: inconsistent fmemopen_write behavior
on last \0
[34008] stdio: stdio-common: scanf %mc pattern will cause
heap
overflow when width > 1024
[34014] nss: gethostbyaddr and gethostbyaddr_r may
incorrectly handle
DNS response
[34015] nss: gethostbyaddr and gethostbyaddr_r return
invalid DNS
hostnames
[34019] stdio: libio: undefined behavior when setbuf on
open_memstream
[34033] network: resolv/ns_print.c: ns_sprintrrf TSIG path
bypasses
buflen and can overflow caller buffer
[34064] dynamic-link: The unnecessary PT_NOTE check in when
loading a
binary
[34069] network: Buffer overread in ns_sprintrrf with
corrupted RDATA
field (CVE-2026-6238)
[34070] hurd: Calling open ("/dev/tty/", O_RDONLY) causes
the program
to segfault
[34073] regex: regexec can mistakenly match with backrefs
and the $
anchor
[34079] dynamic-link: THP segment load aligns all PT_LOAD
segments to
THP page size
[34080] dynamic-link: Support THP segment load with THP
enabled with
madvise
[34083] dynamic-link: __get_thp_mode and __get_thp_size are
called
twice
[34090] libc: wordexp WRDE_APPEND rollback restores stale
we_wordv,
leading to invalid free in wordfree
[34098] libc: Missing SUPPORT_STATIC_PIE in arm32
[34129] string: x86: Non-temporal memset unreachable on AMD
Zen 3/4/5
[34144] libc: ld.so clobbers VFP registers during runtime
linking
[34154] network: Segfault in sock_eq after res_init()
returns -1, due
to stale _u._ext.nscount in __res_iclose
[34156] dynamic-link: dlsym(RTLD_DEFAULT, ...) from a
constructor
SIGSEGVs when tail-called
[34164] dynamic-link: elf: IFUNC resolvers do not see static
TLS
initialization
[34170] dynamic-link: elf: IFUNC resolver reading
global-
dynamic/TLSDESC __thread variable crashes inside
__tls_get_addr
[34183] math: fma produces wrong results
[34192] nptl: pthread_setname_np opens
/proc/<tid>/comm with O_RDWR
instead of O_WRONLY|O_CLOEXEC
[34196] libc: elf: static dlopen: pointer guard of the
loaded
ld.so/libc.so is left uninitialized
[34197] dynamic-link: elf: Stack canary and pointer guard
are
recoverable from AT_RANDOM (getauxval)
[34205] libc: aarch64: SIGSEGV in tunable_strcmp in
static-pie
binaries run with a string tunable
[34208] stdio: scanf not pushback after matching failure
[34210] libc: elf/tst-glibc-hwcaps-prepend-cache fails
on
armv7a-unknown-linux-gnueabihf
[34236] locale: Non-representable transliteration still
causes iconv
to exit with 1 if TRANSLIT is specified
[34289] network: ns_sprintrrf uses p_class, p_type
internally
[34311] build: THP tests failed to link
[34347] libc: Incorrect trailing bitfield word of struct
tcp_info
[34348] dynamic-link: FAIL: elf/tst-thp-1 if THP is disabled
in kernel
[34351] build: Random test failures
[34355] build: [2.44 Regression] "make check -j7
subdirs=stdio-common"
no longer works
[34396] libc: sparc64-unknown-linux-gnu , Gentoo: >200
test failures,
SIGILL in many binaries
[34398] string: Truncated strncpy on s390x z900 ifunc
variant
Release Notes
=============
https://sourcewar
... wiki/Release/2.44
Contributors
============
This release was made possible by the contributions of many
people.
The maintainers are grateful to everyone who has contributed
changes or bug reports. These include:
Adam Yi
Adhemerval Zanella
Alejandro Colomar
Andreas K. Hüttel
Andreas Schwab
Arjun Shankar
Aurelien Jarno
Avinal Kumar
Brian Jorgensen
Carlos O'Donell
Carlos Peón Costa
Charlotte Mcmenamin
Collin Funk
Cosmina Dunca
DJ Delorie
Daan De Meyer
Deng Jianbo
Dev Jain
Diego Nieto Cid
Dmitry Kovalenko
Dylan Fleming
Etienne Brateau
Fabian Rast
Florian Weimer
Frédéric Bérat
Garccez
George Hu
H.J. Lu
Jakub Jelinek
Jiamei Xie
Jiho Lee
Jiri Stransky
John David Anglin
Jonathan Wakely
Josef Johansson
Joseph Myers
Justus Winter
Luca Boccassi
Lucas Chollet
Martin Coufal
Matt Turner
Michael Ford
Michael Jeanson
Michael Kelly
Mike FABIAN
Mike Kelly
Muhammad Kamran
Nicolas Boulenguez
Paul Eggert
Peter Bergner
Peter Collingbourne
Petr Menšík
Pierre Blanchard
Pino Toscano
Pádraig Brady
Richard Wild
Rocket Ma
RyotaSaito
Sachin Monga
Sajan Karumanchi
Sam James
Samuel Balazi
Samuel Thibault
Sana Kazi
Sergey Kolosov
Shamil Abdulaev
Shengwen Cheng
Siddhesh Poyarekar
Stefan Liebler
Thomas Daubney
Tomasz Kamiński
Uros Bizjak
WANG Rui
Weihong Ye
Weixie Cui
Wilco Dijkstra
Xi Ruoyao
Xiang Gao
Yao Zihong
Yunze Zhu
Yury Khrustalev
Zihong Yao
mengqinggang
xiejiamei
zombie12138
We would like to call out the following and thank them for
their
tireless patch review:
Adhemerval Zanella
Andreas K. Hüttel
Arjun Shankar
Aurelien Jarno
caiyinyu
Carlos O'Donell
Collin Funk
DJ Delorie
Florian Weimer
Frédéric Bérat
Ganesh Gopalasubramanian
H.J. Lu
JiangNing
Mathieu Desnoyers
Paul Eggert
Paul Zimmermann
Peter Bergner
Sam James
Samuel Thibault
Siddhesh Poyarekar
Stefan Liebler
Sunil K Pandey
Wilco Dijkstra
Yury Khrustalev
GNU Binutils 2.47 released [LWN.net]
Version 2.47 of GNU Binutils has been released. In addition to the usual bug fixes there are some notable new features in this release including added support for a number of RISC-V standard extensions, a command-line option (-M annotate) which displays the symbol for undefined instructions for AArch64, and more. The 32-bit s390 target has been deprecated with this release.
16:35
Zero to Agent in 30 Minutes: Build a Hermes Social Media Agent with Craig Hewitt [Radar]
If you’re still writing posts one at a time, your content pipeline is already obsolete. On the latest Zero to Agent in 30 Minutes, Craig Hewitt, founder of Castos, demonstrated how to turn a fresh Hermes installation into a social media agent that can study a person’s writing, draft posts, and plan recurring research, focusing on the context, workflows, and safeguards that help an agent produce useful work. Once set up, the always-on agent can run on a schedule, monitor external sources, and complete recurring tasks without human oversight. Check it out.
How to build a social media agent that researches and writes LinkedIn posts
- Choose the right agent setup. Decide whether you need an interactive tool for active work or an always-on agent that runs on a schedule. Craig used the Hermes desktop app for the demonstration, which gives him the option to deploy it to a cloud server or dedicated computer later.
- Create a structured workspace. Ask the agent to organize a new project with separate files for voice guidance, editorial standards, post templates, examples, and operating instructions. A clear file structure gives the agent reliable information to retrieve as it works.
- Seed the agent with relevant context from your own work. Provide examples of your own posts, emails, and other writing that reflect the style you want. Craig also included examples of writing he likes from people he follows to give the agent a broader range to analyze.
- Turn the examples into a voice system. Have the agent analyze the material and document its findings. The voice profile captures the audience, point of view, sentence style, recurring themes, editorial rules, and types of posts to create.
- Test a narrow workflow with human review. Start with one task, such as drafting several LinkedIn posts from a supplied idea. Keep a person in the loop while you evaluate the output, correct mistakes, and refine the instructions.
- Package repeatable work into skills. Create reusable instructions for recurring tasks such as researching topics, selecting a post format, retrieving relevant examples, and drafting in the approved voice. Craig compared these skills to standard operating procedures that make recurring tasks more consistent.
- Connect the agent to fresh data. Add sources of new ideas, such as news feeds, websites, social platforms, or internal business systems. Craig recommended starting with a simple, semiautomated trend scan before investing in a more complex data pipeline.
- Add triggers and safeguards. Decide what starts each workflow, whether that’s a schedule, a user request, a webhook, or a change in another system. Use separate accounts and limited permissions for autonomous agents so you can trace their actions and control their access.
Agents become useful when they have context, clear processes, the right tools, and enough oversight to validate each workflow. Once those pieces are in place, Craig noted, teams can gradually move from one-off prompting to systems that monitor information and complete recurring work.
Coming next week
In the next episode, Max Johnson, cofounder of briix.ai, will take a workflow that only lives in someone’s head at the moment (or maybe is captured in a messy Notion doc or a long email chain) and rebuild it as an autonomous agent, live and from scratch. You can follow along with every decision as you learn how to spot the steps that can be handed off, how to handle the ones that can’t, and how to structure the whole thing so it runs without you.
Ready to take your agent knowledge further? Learn to design and build production-ready agentic infrastructure by attending Harness Engineering for AI Agents on August 12. And if you want to go deeper with Hermes, join us for Build Your First Local Agent with Hermes on August 26.
Stranded in the Slow Zone [Radar]
Gene Kim was grilling dinner for his family on the evening of June 12 when his phone told him that Fable 5 was no longer available. He’d heard the day before from Steve Yegge that the model was going away in 10 days, and he’d spent that first day starting on a plan to get ready. He thought he knew what to do. He was well-versed in DevOps, the art of building resilience against unplanned disasters at scale. He’d run the DevOps Enterprise Summit (now the Enterprise AI Summit), one of the field’s leading conferences. He’d also written several books on the topic, including two “teaching novels,” The Phoenix Project and The Unicorn Project. The challenge that those novels’ protagonist faces—and that Gene would need to solve—is summed up in a job description that read “Your job as VP of IT Operations is to ensure the fast, predictable, and uninterrupted flow of planned work that delivers value to the business while minimizing the impact and disruption of unplanned work, so you can provide stable, predictable, and secure IT service.”
In short, Gene was no stranger to the idea that, as the Scottish poet Robert Burns put it, “The best laid schemes o’ Mice an’ Men Gang aft agley.” So he thought he knew what to do over the next 10 days. Then the US government’s export control order took Fable down eight days early, in the middle of a running agent session. What followed was three hours of what he called the “strangest, most terrifying sysadmin experience” of his career.
Gene told that story as a lightning talk at Foo Camp a few weeks ago, and it was good enough that I asked him to deliver it again at the start of this week’s Live with Tim O’Reilly before we talked about the implications and took listener questions. His title was “Stranded in the Slow Zone: The Day Fable Died, Got Kidnapped, or Got Hit by a Bus.”
10 days to get ready
What Gene had built was a personal system he’d wanted for 16 years and had finally been able to finish with the help of Fable. It indexes everything he’s ever paid attention to: 25,923 screenshots going back to 2011, 13,651 YouTube videos, 590 recorded Zoom meetings, 6,132 liked tweets, and 1,056 saved articles he meant to read. The system touches about 50 repositories, with 50,000 lines of code, most of it written in two months. Gene runs it as a constellation of long-lived agents with names and jobs. Marvin is chief of staff and handles Slack, calendar, and the inbox queue. Buster runs the repos and the long jobs on Hetzner. Forge is the engineering identity and sits in two seats, one on his laptop that holds the secrets and one always-on in the cloud. As Gene put it, each one is a who, a where, and a role.
He knew the system worked when his wife asked what the mileage was on a car he’d just turned in after a three-year lease. Half a minute later he had 26,350 miles, read off the pixels of one screenshot out of thousands, cross-checked against the file timestamp and the clock visible in the photo of the odometer. That success led him to search his archive for an article he’d been hunting for six years, about the impact of spreadsheet software on the accounting profession. The answer surfaced from his own liked tweets: James Cham pointing to a 2017 Greg Ip article in The Wall Street Journal: 400,000 bookkeeping jobs lost since 1980 against 600,000 accountant and analyst jobs gained, because spreadsheets made accounting cheap enough that we bought a lot more of it. Gene had wanted that citation for his Vibe Coding book and couldn’t find it in time.
Gene’s first warning that his project might not work without Fable’s capabilities actually came before the shutdown. Fable started refusing a task over a YouTube terms of service question and handed the session to Opus, and Gene noticed that Opus couldn’t operate the tools that Fable had built. Gene’s note to himself at the time was “Oh no, this can’t fly the ship I built.”
So when Yegge told him the model was going on hiatus, he had a real plan, which he borrowed from Vernor Vinge’s A Fire Upon the Deep. In Vinge’s novel, how smart a mind can be depends on what region of the galaxy it’s in: A starship built in the Beyond goes progressively dark as it sinks into the Slow Zone. Gene decided to chaos-monkey his model dependency the way Netflix chaos-monkeys infrastructure. In other words, “deliberately pull the smartest model and prove the lesser one can still fly the ship.” In practice, this meant having Fable retrofit all the documentation and write the answer keys while it still could, then running a cold Opus session, giving it nothing but the repo and the docs, to see whether it could pass the battery with no coaching. As Gene recounted, “My worst nightmare [was] that we’ve created everything for Fable, and it will be unusable by Opus.”
He got about a day into his 10-day plan.
At 5:21pm ET on June 12, Anthropic received the government’s directive to suspend access to Fable. Soon after, seats everywhere started returning “There’s an issue with the selected model (claude-fable-5). It may not exist or you may not have access to it.” In Gene’s project, both judgment seats dropped to Opus 4.8 mid-conversation. Gene declared a SEV1, centralized command, and killed five timers on one agent, seven on another, and the crontab. His directive was that every button you push is a trap and some of them blow up the spaceship. A Claude Code cron fired anyway at three in the morning. The ship was on fire, and with Opus on max thinking mode, a single keystroke could take six minutes to send.
Almost none of the failures looked
like failures, just “a normal state quietly going
wrong,” as Gene put it. The smartest seat wrote “bridge
(Fable)” into every log entry all day when it had been Opus
the whole time, because nobody was monitoring. One identity argued
with itself across two models, each trying to disown the
other’s work. Something pushed to main bearing the word
“ratified” when nothing had been ratified. A confident
false claim about a JVM dependency turned out to be refuted by a
single ls -la. There was a green dashboard sitting on
top of all of it. “The hardest traps don’t announce
themselves,” Gene pointed out. “They look like
Tuesday.”
Gene managed a recovery in a few hours, but it wasn’t due to the heroics of a smarter model. It only worked because he was able to reconstruct the documentation for his project, which wasn’t immediately available. But, it turns out, Fable had in fact mostly written it and simply never checked it in anywhere. Gene and Opus went rummaging through Fable’s desk, found the 80%-finished drafts, and used them to rebuild. Two fresh Opus seats, given only those documents, stabilized the ship. That’s the “the amazing ray of hope” to keep in mind if you’re worried about finding yourself in a similar situation, Gene said.
We’ve seen this pattern before
This isn’t just a warning of the potential risks of relying on advanced AI models when the Trump administration is Lucy playing football with Charlie Brown, or perhaps said more generously, playing Netflix-style chaos monkey. What we should take away from Gene’s story is the way that a personal project developed with AI can now have sufficient complexity to require DevOps-level robustness. Individuals are routinely building systems that used to need whole teams to keep standing, and the practices for keeping them standing have only begun to propagate.
Over the years, I’ve observed numerous periods when something that at first mattered to only a handful of organizations tended, a few years later, to matter to everyone. When the stories first came out about Google’s revolutionary approaches to data center architecture and operations, we at O’Reilly were eager to publish about the new frontier. Plenty of people told us not to bother. There was only one Google and nobody else would ever operate at that scale. They were wrong. There are now many companies operating at the scale of Google circa the time they first invented techniques we now all take for granted.
Gene’s system is a personal project run by one guy with 50 repos he wrote mostly in two months, a chunk of it in a single 90-minute pair programming session with Steve Yegge. But it had the failure modes of a large enterprise system because the model let him build something with the complexity of a large enterprise system, and he had passed the point of being able to fit it in his head.
Gene shared a detail that helps to explain why substituting Opus for Fable was so hard. The main CLI utility that everything in his project hinged on had an out-of-date help message. Opus would run it, read that the command didn’t exist, and stop. Fable would read the same message, notice it was surrounded by evidence that the command did exist, go look in the source, decide the help text was wrong, and run it anyway. That’s the behavior the model cards describe when they talk about frontier models routing around obstacles in test environments. The reason Gene couldn’t swap in a lesser model is the same reason the system worked at all.
But it’s also a good reminder that Fable isn’t all-knowing. I’ve noticed in my own work that Fable and ChatGPT 5.6 Sol fail often on their first try, especially if the project isn’t well specified. What they’re great at is figuring out what went wrong, then trying something else, failing and retrying their way all the way to success. Persistence in routing around obstacles is their superpower. Gene and I didn’t talk about that on the show, but it’s something I plan to write more about.
Rug pulls come from everywhere
Jaco in the audience asked the obvious question: Isn’t a hard dependency on a hosted frontier model too big a risk for mission-critical work, compared with running a local model with a harness you control?
Gene pointed out that using a local model doesn’t necessarily buy the control that you’d hope for, because the government chaos monkey could jump in there too. There’s active talk that certain classes of models may become illegal to use depending on where they came from.
What does seem to protect you is portability. Gene had avoided trying anything besides Claude Code because he assumed the switching cost was high, the way switching between macOS and Windows used to be a two-day commitment he’d regret halfway through. Then he tried Codex with GPT 5.6 Sol and found the cost of switching close to zero. The skills and prompts ported right over. He’s now using Codex more than half the time and calls it spectacular, which given how he described Fable a month ago is high praise.
He also had a warning for anyone running agents on small models to save money. He’s been studying 22,000 of his own agent conversations, and has identified three patterns, as shown in his figure below.
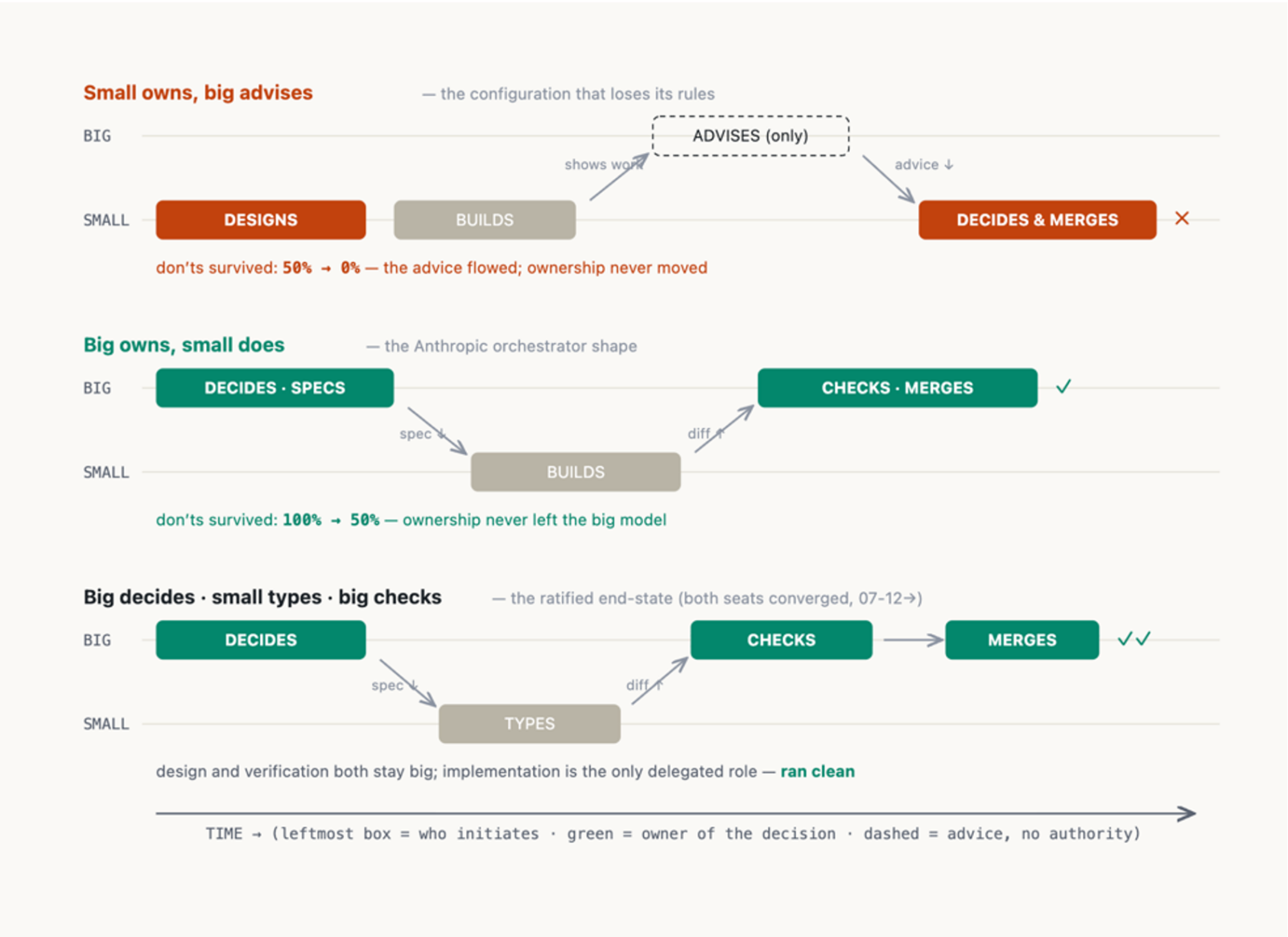
In his experience, the configuration where a small model owns the work and asks a big model for advice doesn’t work very well. Fidelity gets lost on the way up, like a game of telephone. What ran cleanly was the big model planning, deciding, and checking output, with the small model only executing the plan. When a small model does have to ask a big model for advice, Gene’s fix is to pass along the full original transcript of what he wanted plus explicit permission for the big model to override the small one if it thinks it understands the goal better.
Writing with AI
In addition to vibe coding, Gene uses AI to help him with his writing. He said it cut the time to write his Vibe Coding book roughly in half and made it way better. His editor of 10 years told him it was the cleanest handoff she’d ever gotten from him (not a compliment, Gene joked). He’s also uneasy about using AI for writing. He said the old badge of honor among authors was that many start books and few finish, and now everyone who wants to write a book will finish it, and a lot of that will be slop. He would never “vibe write” the way he “vibe codes” and doesn’t think using AI makes his own work slop, but he does see some parallels in how he feels about writing with AI and the way that some senior engineers feel about AI-generated code.
I’m sympathetic, but I’m not sure that he’s right. I had a small experience last week that convinced me that writing with AI might well follow the same arc as coding. AI-generated text will not always be slop, and there will be art in how humans get AI to help them write the things they want, just as we’re learning to do with code.
I was having a conversation with an old friend who I hadn’t seen for many years. He was describing a thread that had started with work he’d done on speech synthesis 30 years before, and how it had come together as a new theory with deep implications, and he wanted help socializing his ideas with some people I know who could be helpful to him. So I asked him to write something that I could pass along.
What he wrote made much less sense to me on the page than it had in conversation. So I gave his email to Claude and asked it to put things in what I thought was the right order. (This has always been the first step in my writing and editing process.) Then I told Claude which paragraphs were clear to me and which weren’t, and asked it to unpack the ones that I was struggling with. We went through numerous iterations till the piece made sense to me. “Writing” with Claude was producing words that increasingly captured my understanding. When I sent it back to my friend to see if I’d gotten it right, he said “not quite” but that my feedback really helped him understand what he needed to do to express his ideas more clearly.
It’s been a long time since I’ve worked directly with authors, but my conversation with Claude reminded me of what I used to do in my early days as an editor. Only with Claude I did something in 15 or 20 minutes that once would have taken me half a day. It’s a power tool, but to use it well, you still have to know what good looks like.
There are many different kinds of writing and editing. What Shakespeare or Jane Austen did with words would have been unthinkable to a medieval monk. There will be writing artforms of the future that may be as different from what we do today as photography is from painting. But it will still be creative art. Much of it will be slop (see Sturgeon’s law), but the best of it will be great.
Everybody is managing bots now
In 2016 I wrote a piece for MIT’s Sloan Management Review called “Managing the Bots That Are Managing the Business.” The argument was that even then, many of the workers at big tech platforms were bots of one kind or another, and the software engineers at the company were their managers. At Amazon, one bot shows your search, another takes the order, another prepares the shipping manifest, another takes your money. The programmers’ job is to plan the work, set up their electronic workers to succeed, improve their performance, and correct them when they go wrong. The work looks a lot like management to me.
Gene agreed. His sister-in-law is a lawyer at one of the tech giants, working on a consent order that requires proving that every column of data collected is either disclosed or has a documented business reason. Last year the company assigned her an engineer to work through it together task by task. This year her engineering manager wrote her a Claude Code skill that takes a column name, traces it back through the code, and explains what it does. She doesn’t need the engineer.
So a lot of work today is either creating bots or managing bots. Gene’s sister-in-law had spent her career without ever being able to do either. Now that’s changing.
Asked who’s safest from all this upheaval, Gene quoted Kent Beck, who says software success has always come down to two people, the person with the problem and the person who can fix it, and that the closer together you can get those two the better the outcome. The beauty of coding with AI is that it can narrow that gap. It can even turn those two people into one.
Use AI for the fun of it
If it takes something like 10,000 hours to get good at an instrument or a sport, how many have most of us put into AI yet? Gene thinks the curve of how much you trust AI and how well you can predict what it will do rises with use, and that the only reliable way people accumulate that many hours is by enjoying themselves. What everyone at Foo Camp had in common, I noted and Gene echoed, was that we all love playing with AI.
I gave a talk back around 2008 called “Why I Love Hackers.” I made the point that so much of what turned into the future, open source and the web for example, came from people doing things for the hell of it rather than from the VCs and entrepreneurs Silicon Valley celebrates.
All you hear about in AI is the money story, but Gene’s app started with a 90-minute pair programming session with Steve Yegge on a problem he’d wanted to solve for a decade and never had a reason to. They finished the first version in 47 minutes.
So harden your systems, write the documentation while the smart model is still there to write it, and keep your escape routes open, but also don’t forget to go build something you have no particular reason to build other than that it scratches your own itch.
You can watch the full episode on YouTube. And on August 3, I’ll be speaking with writer and technology leader Drew Breunig. Registration is open if you’d like to attend live.
Gene’s Enterprise AI Summit is in Charlotte, October 7–8. His new book with Steve Yegge is Vibe Coding.
15:56
Valhalla's Things: Late Victorian Vampire Shirt [Planet Debian]
Posted on July 27, 2026
Tags: madeof:atoms, craft:sewing, FreeSoftWear

The recurring joke is that because of some health issues, in summer I dress like a Victorian Vampire.
But how would an actual Late Victorian Vampire dress? Picture her, she would look like some kind of eccentric gentlewoman, as vampires usually do, probably with a style that is a bit conservative, rather than following the latest fashions.

Now, she wouldn’t probably wear men’s shirts. But what if she was a lesbian1 vampire? Wouldn’t she need a fancy, frilly shirt to go with her tailored cycling suit when she’s out seducing the more active ladies in the neighbourhood?
Or maybe not. It’s not making a lot of sense, is it? But I do have a lot of shirt fabric in my stash2, and I could use a few more shirts that were practical and comfortable, but also somewhat over the top.
For the practical and comfortable I went to my trusted 1880s shirt, while for the over the top part I looked at inspiration from the earlier 18th century frilly shirts, and their later imitations.
I decided to use some nice cotton batiste I had bought quite a few years ago to make one of my first historically inspired shirtwaists: I may have a tendency to buy a bit more fabric than actually needed by the pattern, but that’s what everybody does, right?
For the ruffles I decided to use a lighter weight cotton voile, also from the stash.

At the front, I wanted the ruffle to be inserted in the yoke, but I was also whipstitching the gathers to it to make them neater, so I started bu attaching the yoke lining to the gathered front, then I whipstitched the ruffle to the front, catching each gather, and finally I whipstitched the other yoke on the ruffle and the rest of the gathered front.

And then after sewing the collar, I realized that this way the slit would have remained open in the front (or the collar too narrow), so I had to unpick the front part of the yoke, and sew it again, this time leaving an excess of fabric as wide as half the placket width from the pattern, to be sewn directly in the collar band.
From then, things progressed smoothly, with some interruptions, until I got to the first sleeve, which I failed to insert twice, as one does.

On the third attempt, with a different method, I succeeded, I tried the shirt on, and it already felt extra.

But it could be even more extra. With some ruffles also at the collar.

The shirt had been made with a simple collar band, and I could have just added the ruffle to it, but I also wanted to be able to wear it with other detachable collars, so I decided to make another collar band with ruffles, to wear on top.
And that was mostly it, except for the reinforcement patches at the side seams and cuffs: I love having them, because they make the seam end neater and stronger, but they are a bit of a hassle to make, so they got postponed a few days.

But finally, the shirt was done.
And I tried it on, and it was good.
But now I really need a pair of cycling breeches, don’t I?
15:49
How I see the network evolving [Scripting News]
A frequently asked question about RSS.chat. How about adding external feeds to the timeline. Of course we thought of doing this, and even started development, you might even find some traces in the code of that attempt.
The thing about bootstraps is you can't anticipate all the questions in advance, and thus can't have answers prepared for them.
RSS.chat is a group chat app that uses RSS and OPML to present its face to the world, along with an API that still needs more docs. It's similar to half of Mastodon, and we're going for something completely different. People will want to run all-size workgroups. I like having one with 20 or 30 people, friends who develop software. I don't mind doing a little bit of moderation, but I don't want to drive deliberately into a scale that only works if you have extensive and very expensive moderation.
"Small pieces loosely joined" means we have a great writing app, and connect to feed reading apps, ones with a few new features to do the things people want to do with a social network that happens to use RSS and OPML to get stuff around the net. It would be a different kind of feed reader but the underlying technology is identical, because we built on a set of web standards, widely supported by feed readers. This is a UI exploration for them, primarily.
Just to be sure everyone understands -- I already have such an app, called FeedLand. You can set up an account there for free. And read the docs. It may not have all the features we'll need, but it will be a good place to start.
FeedLand supports a crucial feature that most readers don't -- subscribable lists of feeds. If you want a collection of things to read that you can reply to even if you aren't on the site, that's where we're going to put that feature, that's where all the RSS.chat and compatible apps can be in one flow, arranged however you like. And from a user interface standpoint, we can make it look like it's all happening in one app, thanks to the rssCloud protocol and the websockets firehose feature in RSS.chat FeedLand has the same feature.
We decided there was a line there, that RSS.chat would be one of the small pieces as would FeedLand, and both would be replaceable which is the other fundamental value. And with FeedLand and dynamic lists, will come the user interface people ask for. Many different user interfaces I hope because another way we've been cheated by the dominatioin of twitter-like social networks is there's no room to try out radically new ideas. Software should move. But Twitter didn't live on the web, so it didn't have the ethos of small pieces loosely joined. I know Jack wanted to do this, I had lunch with him in 2007 when he described the protocol, and I was very enthusiastic. But it never got out because the juggernaut that Twitter became didn't leave any room for new architectures.
I hope this clears it up. I want RSS.chat to be the coral reef for a new network of feed-based apps running on the web that does what social networks do, but with no one owning it, and everyone gets to play.
15:00
A new utility exports the contents of a Frontier object database into a single large JSON file. I needed this because I'm preparing to move my code editing suite to Drummer running on new Mac hardware. Took a long time to get here, but with Claude's help the project looks possible. In the meantime the list of stuff I want to do with RSS.chat, while much shorter than it was, still has some juicy bits in it.
14:35
Security updates for Monday [LWN.net]
Security updates have been issued by Debian (chromium, hplip, and linux-6.1), Fedora (firefox, GitPython, google-osconfig-agent, lego, libgit2, libreswan, libwebsockets, moby-engine, p11-kit, pam, python-idna, rust-libgit2-sys, skopeo, systemd, trafficserver, webkitgtk, and xrdp), Mageia (giflib, graphite2, libnfs, vorbis-tools, wget, and yelp), Red Hat (firefox, thunderbird, and webkit2gtk3), and SUSE (amazon-ecs-init, chromedriver, ffmpeg-7, ffmpeg-8, firefox, google-osconfig-agent, gpg2, java-17-openjdk, java-25-openjdk, kernel, libsrt1_5, nginx, perl-HTTP-Date, perl-XML-Bare, proftpd, python-pyasn1, python-soupsieve, python313-astropy, python313-urwid, systemd, thunderbird, and trivy).
14:28
The Hard Goodbye [The Daily WTF]
One minute, you’re fine. The next, you’re doubled over with tears spilling down your face while an aching black hole in your heart threatens to drag you into oblivion.
Grief’s funny like that.
Aggie Shaw, my old friend and mentor, had died of a sudden illness at home. She’d lived alone. Who found her? How? I didn’t know and never would. There was so much I’d never gotten a chance to tell her. She would’ve listened to me vent the frustrations and resentments I’d been burying over the years for sanity’s sake. She would’ve known what to do.
God, I missed her.
As if that weren’t bad enough, the brass expected Tech Support to go right back to business as usual. Maybe the rest of them wanted to bury their heads in casework. I didn’t. Between this, the horrible winter commute, and the promotion I’d never asked for, going back to the office felt impossible.
My boss wouldn’t let me use sick time. He really should’ve; the grief had hit me like a goddamn truck. Good thing the start of the new year a while back had refreshed my stack of paid time off. I started burning it from both ends.
When I wasn’t flat on my back or nursing a migraine, I was stumbling around my tiny apartment with half a brain cell, attending to the bare minimum of survival. Eat this. Drink that. Where’d I leave my smokes? In the rare times I could think, my thoughts were plagued with darkness. I didn’t know if I’d ever make it out of that mess.
Then, Megan called.
It was nearing noon that day. I was lying in bed, peering out my window at a dull gray sky and falling snow. I’d let everything else dump to voicemail, but when she rang, I answered with the urgency of a drowning victim grabbing a buoy.
“Hey,” she greeted, her voice subdued. “I heard about what happened. I’m really sorry.”
There was so much tumbling through my head, but none of it wanted to tumble out. “Thanks,” I managed.
“How are you?”
“Lousy.”
“Wanna meet up somewhere that isn’t work?” she asked. “The Apex Tower has a big indoor courtyard. I eat lunch there sometimes. If we go around 10 in the morning, we’d probably have it to ourselves.”
Something in me leapt at the offer. “I’d like that. Tomorrow?” I would still be on vacation-in-name-only.
“Sure,” Megan replied. “See you then!”
I had something to look forward to. Part of my emotional burden lifted right then and there.
It was a little easier to get out of bed the next morning. I took the bus to an unfamiliar spot of downtown, crossed a slush-covered plaza, and entered a skyscraper. The warm ground-floor courtyard boasted marble floors and immense windows for walls. Potted trees and flowers lined the perimeter. Huh, I’d forgotten those even existed.
Megan was already seated at a metal table flanked by two chairs. When she spotted me, she jumped to her feet and waved, a knowing and sympathetic look on her face. She waited until I reached the chair across from her to say, “You look like you could use a hug.”
I froze with surprise, one hand on my hat in the process of removing it. A hug? My puzzled brain tried to figure out just when I’d been hugged last. I had no idea. My body wasn’t waiting around for an answer. It was already turning toward her, arms raised.
Megan silently walked into my embrace and hugged back firmly.
Tears spilled down my face. My heart ached. And yet, another part of my invisible burden suddenly lifted. Something in me had been dying for this, for my pain to be seen.
“Thanks,” I muttered.
We parted. While I doffed my coat and hat, Megan returned to her chair, sitting back down across from me. “Whatever you need to get off your chest, go for it,” she offered.
I sat myself down, sniffled, blotted my eyes on my sleeve, then glanced high and low to confirm something I already knew: we were alone in that big empty joint. Still, I hesitated. At first, I wasn’t even sure I remembered how to string words together to form a sentence. But then it started gushing out of me like a busted water main. “You ever hear of rubber-duck debugging?”
Megan blinked. “No.”
Surprising. Most developers had, but she was fresh out of college. “A programmer came up with it way-back-when,” I explained. “Whenever you’re coding something and get real stuck on a bug or error, you find yourself a rubber duck. Go line by line in your code and explain to the duck, out loud, what you want the code to do. Eventually, you and the duck will find the point where your intentions and reality don’t match up.”
She smiled. “I like that.”
“Aggie had a rubber duck in her cube she called RD,” I continued. “Whenever she was stuck with a support issue or even a personal problem, didn’t know where to go next, she’d tell RD about it. He’d help her figure out what to do or ask next.
“When I first got hired, Aggie showed me the ropes. She always said, the best way to troubleshoot is to be the duck yourself. Get people, or hardware, or software to explain what they’re trying to do. You’ll figure out how to proceed.
“Some people are so upset at the problem that they take it out on the nearest target: the support rep who comes to help. Aggie could charm even the angriest people into cooperating with her. She was the best. She was the best, and all she got for her trouble was more work. Now that she’s no longer of any use to them, they’ve swept her under the rug. They want me to replace her!”
Megan’s eyes went wide.
“I’m no damn manager! I told my boss where to stick it. I’m riding out my PTO, and then hell if I know what’s next. I can’t go back there, I’d just be dying in place. And for what? So the bum at the top of the food chain can have a third yacht?” I leaned toward Megan, my gaze pleading with hers. “Look, I ain’t afraid of death. I’m afraid of dying before I’ve lived. I don’t want my only contribution to the world to be reimaging laptops and rescuing old printers. I can’t do it anymore. Can’t sit around complaining, either, I gotta do something! I gotta get the hell outta that joint!”
There it was: out in the open again, no longer whispered but shouted from the core of my being. Leaving was the right call for me. I felt it in my bones.
Megan held eye contact, blinking a few times. “I remember you saying you wanted to leave. If you did, what would you do?”
I’d never really let myself play with my little pipe dream. “I dunno exactly. But I’ve bought myself time to think it over. There are options, like going freelance.”
She blinked again. “Freelance tech support?”
“I majored in Computer Science back in school,” I said.
Her eyes went wide again. “Really?”
“Haven’t flexed those muscles in a while, but I could. Or I could get into something totally different. And you could come with.” Well aware of how unhappy she was at that joint, I sat up straighter in my chair. “We could start our own IT group. No bosses. Everyone an equal partner with an equal say in how things are run. And we could rope in anyone else who wants to come with!”
Megan seemed intrigued at first, but then sobered. “What about bills? Rent? Everything?”
“We could pool our resources and look out for each other,” I said. “That’d give us some time to get our feet under us.”
Her expression turned strained. “Aren’t you scared?”
“You bet I’m scared!” I glanced down at the table. “When I first got outta school, the idea of spending the whole rest of my life at a full-time job terrified me. But it seemed like everyone around me was fine with it. I thought I was the problem. Bit my lip, put my head down … for 20 years.” I glanced back up at her pleadingly. “Has it gotten any better? No. I’ve just gotten used to it. Another 20 years, and I won’t be any good for anything else. That’s if I make it that long! Aggie didn’t. Look, there’s no right or wrong answer, just what’s right for you. Listen to your gut. If you don’t like where you’re at, I’m living proof that staying the course is the wrong move. Leaving is risky … but so’s staying put, you know. The next round of layoffs could be right around the corner. You might get stuck babysitting that scheduling algorithm you were telling me about.”
Megan listened intently to my rant. Finally, she nodded. “You’re right. I’m not happy where I am, and it won’t get any better. Time to try something different.”
Still mired in grief, I had at least gained a new sense of purpose to keep me afloat in the storm. Megan went back to work like nothing had happened. With my remaining time off from work, I did some research into our options. Hunting around online turned up a highly-rated accountant who walked me through the bare-minimum corporate setup, the taxes and bookkeeping and all that. We both tracked down advice online from other freelancers who’d been where we were now. And we put out feelers among our coworkers. Our questions struck some nerves, but also stirred considerable interest. Reynaldo was in; we had ourselves a network guy. Sanjay, a backend developer, was a maybe who wanted more time to think it over.
There were plenty who wanted to join us badly, but couldn’t swing it due to debt, insurance, things like that. I urged them to think about one thing they could improve at work, one cause they could get behind. Whatever it was, I told them to start making it happen, one step at a time.
As my PTO bled away, I found myself half-exhilarated, half-scared outta my wits.
Finally, it was time to go back. That first morning seemed like any other, but with my secret purpose in mind, I sat on the bus and walked the bone-chilling streets with a secret strength hardening my spine. When the old joint appeared ahead of me, more foe than friend, I felt relief knowing our remaining time together was short.
Tech Support seemed no different; everyone was quietly minding their own business. I’d had plenty of time to think about what I’d do on the first day. My plan involved skipping my cube and heading straight to Aggie’s old office. After my talk with Megan, I’d decided to go looking for something. I had a snowball’s chance in hell of finding it, but something in me insisted on trying.
As I walked up to the closed front door, the first thing I noticed was my name, not hers, standing out in fresh, gleaming gold letters against the frosted glass. Pushing past revulsion, I grasped the doorknob and turned it.
The door gave way to darkness. I flipped the light switch with my other hand and found an empty desk, gutted shelves, bare walls. Looked like someone had come through with a giant trash can and thrown out whatever wasn’t bolted down. My revulsion intensified, but hey, at least I wasn’t trespassing. I shut the door to “my” office behind me and slowly approached the desk.
There was nothing to be found out in the open, not even a stray paperclip. I sat down hard in her old chair, reeling for a minute. Then I searched the desk drawers in front of me: first the bank on the left, then the right. Empty. I pulled out the drawer just under the desk—and there he was, swimming between a few stray pencils: a rubber duck about 3 inches tall. RD in the flesh.
It was as if Aggie had put him there for me to find. I couldn’t believe it. My spirits soared in a way they hadn’t for ages.
Just as I slipped the duck into my trench coat pocket, the door to her—my—office swung open again, making me freeze. There stood Bill, my boss.
“I saw the lights on in here.” A smug smile spread over his face. “I knew you’d be back. Bet it feels great, knowing you’re done babysitting all those morons and their computer equipment!”
Was that it? Twenty-odd years of my life boiled down into one cynical statement? No, there was more to it than that. For every bizarre war story, there were tales of grateful people helped, challenging problems solved. It hadn't been all bad. But it was over, just not the way Bill thought.
An electric mix of nerves and resolve jolted me to my feet. “I told you to find someone else, and I meant it. This is my two-week notice.”
I left Bill agape in that threshold and hurried back to my old cube, where my company-assigned laptop, docking station, and phone still resided. I hung up my coat, sank into my old chair, and booted up the machine. I had such a mountain of email in my inbox that I didn’t even want to look at it, but there was one message at the top that I absolutely couldn’t pry my eyes away from:
I moved some things around on my calendar. 4:00 PM today is open. Please come to the executive floor.
-Leila
To be continued ...
14:14
The site got hacked and is being worked on. Hopefully it’ll all be back to normal in a day or three?
For now you can view new pages at Patreon whether you’re a supporter there or not.
13:35
Issue 47 – Greta’s Wedding Pt. 2 – 06 [Comics Archive - Spinnyverse]
The post Issue 47 – Greta’s Wedding Pt. 2 – 06 appeared first on Spinnyverse.
12:49
Mozilla gives Haiku permission to use the Firefox name [OSnews]
Haiku has a Firefox port, but due to Mozilla’s trademark policies, it’s actually called Iceweasel. After some back-and-forth with Mozilla, the browser maker has no given Haiku permission to officially use the Firefox name for the port.
But don’t worry, Iceweasel isn’t going anywhere. I plan to maintain both. The idea is to keep Iceweasel as the privacy-friendly, telemetry-free build, while Firefox will be the fully official, Mozilla-compliant build (with telemetry enabled, once I manage to fix the Glean rust issues).
↫ 3dEyes on the Haiku forums
This seems like a nice solution, and happens to make sure Haiku users can actually choose between standard Firefox and what is essentially a more private “fork”. A great outcome.
Java deprecates support for macOS x86 [OSnews]
Apple has transitioned its hardware products to the AArch64 processor architecture and is phasing out support for x64. Oracle engineers will thus stop maintaining the macOS/x64 port as of JDK 27. Maintaining the port is a significant burden.
↫ JEP 541: Deprecate the macOS/x64 Port for Removal
The port won’t yet be removed, but will be in a future release. Considering the number of Intel Macs that must surely still be in use today, this does seem a little premature to me.
That is the first line of the 80s microcomputer BASIC game The Wizard’s Castle initially written for the Exidy Sorcerer platform.
It’s a
REMark statement, a comment in that particular language.10is the line number, if you’re unfamiliar with languages that had such things.But the interesting part was this
"_(C2SLFF4mess. A typo or garbage? No. It appears verbatim in the source code as originally published in the July, 1980 issue of Recreational Computing.What the heck is it?
↫ Brian “Beej” Hall
A fun investigation to brighten up your Monday.
12:14
Pluralistic: How the EU can punish Google (despite Trump) (27 Jul 2026) [Pluralistic: Daily links from Cory Doctorow]
->->->->->->->->->->->->->->->->->->->->->->->->->->->->->
Top Sources: None -->

Today's links
- How the EU can punish Google (despite Trump): Grant me the courage to change the things I can.
- Hey look at this: Delights to delectate.
- Object permanence: Chilling Effects; Billy Bragg v Myspace; Glenn Beck calls murdered Norwegian children "Hitler Youth"; Photog sues Getty for $1b copyfraud; Best paid CEOs perform worst; Olympics v "Olympics"; Alberta tar sands v "hot lesbians"; IoT security apocalypse; 3 Little Pigs in pidgin; The nasty party; Copyright extortionist infringed fellow extortionist; Grandpa mobbed for photographing grandson in park; Ice Bucket Challenge didn't cure ALS; Twiddling enshittifies your brain.
- Upcoming appearances: Edinburgh, Sydney, Melbourne, Brighton, London, South Bend.
- Recent appearances: Where I've been.
- Latest books: You keep readin' em, I'll keep writin' 'em.
- Upcoming books: Like I said, I'll keep writin' 'em.
- Colophon: All the rest.

{kind=link}
{kind=link}
How the EU can punish Google (despite Trump) (permalink)
The "Serenity Prayer" (Serenity to accept things I can't change/Courage to change the things I can/Wisdom to know the difference) is usually cited as pop psychology or addiction recovery advice, but I think there's a place for it in policymaking.
Take the EU's fight against US Big Tech. During the Biden years, the EU's tech policy matured into something serious and ambitious, culminating in the Digital Markets Act (DMA) and Digital Services Act (DSA), a pair of big, muscular policies that would curb Big Tech's most abusive conduct. The EU's ambition didn't occur in a vacuum: it was part of a global wave of antitrust fervor whose top agenda item was reining in tech:
https://pluralistic.net/2025/06/28/mamdani/#trustbusting
In this fight, the EU had important partners all over the world. For example, South Korea and Japan used the facts uncovered through EU enforcement action against Google and Apple to pursue similar cases:
https://pluralistic.net/2024/04/10/an-injury-to-one/#is-an-injury-to-all
But the EU's most important partner in its fight against American Big Tech was America. Biden's trustbusters – Lina Khan, Rohit Chopra, Jonathan Kanter, Tim Wu, et al – were every bit as serious about Big Tech power as anyone in the EU. After all, the American public are always the first victims of any new tech scam, and America is the only country with a large, affluent population who lack modern, comprehensive consumer privacy protection, making Americans highly prized prey for tech companies:
https://pluralistic.net/2025/04/23/zuckerstreisand/#zdgaf
With America and the EU on the same side of the tech fight, the world had a fighting chance. Tech knew this, which is why Big Tech backed Trump hard during the 2024 election and aggressively curried his favor after he won. From the tech barons who paid $1m each to sit behind Trump on the inaugural dais to the millions tech companies donated to Trump's Epstein Ballroom at the White House, tech has made it clear that it supports anything Trump wants to do, provided he shields Big Tech from any attempt to limit their ability to spy on and steal from Americans and the world.
Even before he took office, Trump made it clear how he would reward tech's loyalty: weeks before the inauguration, Trump went to Davos and threatened the EU with reprisals if they enforced the DSA or DMA against his tech companies:
Trump wasted no time leaning on US trading partners on behalf of Big Tech. He bullied Canadian PM Mark Carney into dropping his plan to tax US tech companies. Big Tech uses a variety of tax-cheating gambits to evade taxation around the world, making it impossible for (tax-paying) domestic companies to compete:
Trump also got UK PM Keir Starmer to drop his plan to tax tech:
And he got the EU to roll back its plan to regulate AI:
https://fortune.com/2025/11/07/eu-ai-act-weaken-regulation-delay-big-tech-trump-government/
None of the governments that caved to Trump got anything in return. As I've written:
Give Trump everything he asks for and he'll demand more. Deny Trump anything and he'll demand more. Sign a contract with Trump and he'll break it. Send Trump an invoice and he'll stiff you. For Trump, "the art of the deal" can be summed up in one word: renege.
https://pluralistic.net/2026/07/22/table-flipper/#graveyard-of-indispensable-nations
Case in point: after the EU surrendered to Trump on AI regulation, Trump announced that a on ban EU officials who had worked on the Digital Services Act from traveling to the USA:
Then, after the EU made more concessions to Trump, he announced a ban on even more EU officials:
Trump ordered his tech giants to dig through EU officials' private correspondence so he can figure out who to ban next:
Trump's tech companies got the memo. When the EU ordered Apple to follow the law, Apple told the EU to fuck off:
https://pluralistic.net/2024/02/06/spoil-the-bunch/#dma
After all, Apple is a key partner in the Trump administration's mass deportations. Apple blocked an iPhone app that warns Apple customers if they're about to be kidnapped or murdered by ICE. Trump needs Apple, just as much as Apple needs Trump:
https://pluralistic.net/2025/10/06/rogue-capitalism/#orphaned-syrian-refugees-need-not-apply
Despite this, the EU keeps trying to enforce its laws against Trump's companies. Last week, the Commission announced a $1b fine against Google for violating the Digital Services Act with conduct that cost Europeans many billions:
In other words, Google wasn't even being ordered to disgorge all the money it stole, just some of it. Remember, a fine is a price: the EU's fine here will only make this kind of cheating slightly less profitable.
Nevertheless, Trump responded immediately by threatening the EU with many billions more in tariffs if they continue to attempt to enforce the law against one of his companies:
Trump, the European Commission and Google all know this is about more than one $1b fine. The DSA and DMA both provide for steeply rising fines and other penalties for repeat offenders, and Google clearly has no plan to end its very profitable European crime-spree. Trump's threats aren't a bid to kill this enforcement – Trump wants to kill all enforcement.
Retaliatory tariffs aren't the only weapon Trump has at his disposal. If the EU (or any other country) levies a serious fine against Google, Apple, Oracle, Microsoft, or any of Trump's other tech companies, Trump can order US banks not to turn over those fines, even after the EU sends them a court order for the money. If a bank defies Trump, he can threaten to yank its charter. Or he could just run the same swindle he pulled on Tiktok: stealing the whole company and selling it to one of his buddies, who will run it the way Trump wants.
The reality is that without America's assistance, the EU has precious little hope of forcing American companies to do things they don't want to do. In terms of the Serenity Prayer, this is "a thing they cannot change."
The Serenity Prayer doesn't stop with "things you can't change." The next line seeks "the courage to change the things I can." The EU has no control over Google's conduct, but it has total control over its own conduct.
Specifically, the EU could get rid of the laws that ban European companies from modifying US tech exports. The EU adopted the Copyright Directive in 2001. Article 6 of the EUCD makes it a crime to reverse-engineer and modify a device without the manufacturer's permission. This law was adopted under pressure from the US Trade Representative, who threatened the EU with tariffs on its exports unless it adopted an "anticircumvention rule" that banned EU technologists from making products that let Europeans prevent US tech companies from stealing their money and data":
https://pluralistic.net/2026/01/01/39c3/#the-new-coalition
This law is still in force in the EU, despite the fact that Trump (predictably) reneged on the US side of the bargain, hitting the EU with massive tariffs and even threatening to steal part of Denmark.
Article 6 of the Copyright Directive is the reason European tech companies can't jailbreak America's apps, whether that's to get its government and corporate data off of US platforms:
https://pluralistic.net/2025/10/15/freedom-of-movement/#data-dieselgate
Or to modify American social media apps to respect EU privacy laws:
https://pluralistic.net/2026/01/30/zucksauce/#gandersauce
The EU can't control what Apple or Google do. But the EU can absolutely decide whether Trump's companies can use Europe's courts to destroy European companies that defend the privacy and economic integrity of the European people.
If the EU kills off Article 6 of the Copyright Directive, they can use European companies to bring Google and Apple's defective tech exports into compliance with European law. Unlike Trump's companies, those companies can be forced to pay their taxes and respect their users' privacy, labor and consumer rights.
That's the Serenity Prayer's "wisdom to know the difference."
Hey look at this (permalink)
- Nate Silver discovers the educated poor https://crookedtimber.org/2026/07/25/nate-silver-discovers-the-educated-poor/
-
Imagine a World in Which Microsoft Sold Cars the Way It Sells Software https://www.thesling.org/imagine-a-world-in-which-microsoft-sold-cars-the-way-it-sells-software/
-
Tesla swapped a solar owner’s lease contract for the Book of Enoch https://electrek.co/2026/07/23/tesla-solar-lease-contract-book-of-enoch/
-
Canadian legislator reads out apparent LLM response in floor speech https://arstechnica.com/ai/2026/07/canadian-legislator-reads-out-apparent-llm-response-in-floor-speech/
-
The Resistance Liberal Lawyers Helping Trump Take Over the Media https://www.thebignewsletter.com/p/the-resistance-liberal-lawyers-helping
Object permanence (permalink)
#25yrsago Chilling Effects https://web.archive.org/web/20010801172448/http://eon.law.harvard.edu/chill/
#25yrsago 13-year-old hacker's book deal: “The Unofficial Guide to Ethical Hacking" https://web.archive.org/web/20011102164905/http://www.vnunet.com/News/1124279
#20yrsago France’s new copyright law slaughters kills use and open source https://web.archive.org/web/20060812223624/http://soufron.typhon.net/spip.php?article150
#20yrsago Billy Bragg gets MySpace’s terms of service changed https://web.archive.org/web/20100809150257/http://blogs.myspace.com/index.cfm?fuseaction=blog.view&friendID=34570397&blogID=137856388&MyToken=626131d4-c695-42ba-867b-754b9e2bfeaa
#15yrsago Buy an Old West town in South Dakota for $0.8M https://web.archive.org/web/20110728012824/https://edition.cnn.com/2011/US/07/27/south.dakota.town.sale/index.html
#15yrsago Glenn Beck compares murdered Norway campers to “Hitler Youth” https://www.latimes.com/archives/blogs/top-of-the-ticket/story/2011-07-25/opinion-glenn-beck-hits-new-low-compares-norway-victims-to-hitler-youth
#15yrsago 3 Little Pigs rendered into Papua New Guinea pidgin https://www.abc.net.au/reslib/200709/r184705_686227.mp3
#15yrsago Why they call the Tories “the nasty party” https://www.theguardian.com/uk/2011/jul/28/tory-lib-dems-clash-on-policy
#15yrsago US ISP/copyright deal: a one-sided private law for corporations, without public interest https://www.eff.org/deeplinks/2011/07/graduated-response-deal-what-if-users-had-been
#15yrsago Copyright extortionist ripped off his competitor’s threatening material https://torrentfreak.com/anti-piracy-lawyers-rip-off-work-from-competitor-110727/
#15yrsago Karl Schroeder: Science fiction versus structured study of the future, sf as aspiration https://www.antipope.org/charlie/blog-static/2011/07/beyond-prediction.html
#15yrsago Norwegian PM refuses to let terrorist attacks drive his country to intolerance and paranoid “security” https://www.nytimes.com/2011/07/28/world/europe/28norway.html?_r=1
#15yrsago Man with camera in park who fled angry parent sought by police (turns out he was taking pix of his grandson) https://web.archive.org/web/20110829052009/https://pixiq.com/article/man-photographing-grandkid-in-park-deemed-suspicious
#10yrsago Laurie Penny at the DNC: “Dissent will not be tolerated. Protest will not be permitted.” https://medium.com/welcome-to-the-scream-room/bad-moon-rising-8cd348df50e9#.9lhcixjn1
#10yrsago The Ice Bucket Challenge did not fund a breakthrough in ALS treatment https://web.archive.org/web/20160914225439/http://www.healthnewsreview.org/2016/07/ice-bucket-challenge-breakthrough-experts-pour-cold-water-superficial-reporting/
#10yrsago Silicon Valley banks offer tech giants’ new hires 100% mortgages on 24 hours’ notice https://web.archive.org/web/20160727095557/http://www.bloomberg.com/news/articles/2016-07-27/zero-down-on-a-2-million-house-is-no-problem-in-silicon-valley
#10yrsago Patent fighters attack the crown jewels of three of America’s worst patent trolls https://web.archive.org/web/20160727191625/https://arstechnica.com/tech-policy/2016/07/patent-defense-group-seeks-to-knock-out-top-three-trolls-of-2015/
#10yrsago Censorship company drops bogus lawsuit against researchers who outed them https://citizenlab.ca/research-interest/
#10yrsago Photographer sues Getty Images for $1B because they’re charging for pix she donated to LoC https://hyperallergic.com/photographer-files-1-billion-suit-against-getty-for-licensing-her-public-domain-images/
#10yrsago First-ever Michelin star for street food awarded to Singaporean hawker stalls https://web.archive.org/web/20160723174014/http://uk.reuters.com/article/us-singapore-food-hawkers-michelin-star-idUKKCN1021XA
#10yrsago Highest-paid CEOs generate lowest shareholder returns https://www.msci.com/documents/10199/91a7f92b-d4ba-4d29-ae5f-8022f9bb944d
#10yrsago Olympics to companies: mentioning “Olympics” in social media is a trademark violation #https://web.archive.org/web/20160727075209/https://www.espn.com/olympics/story/_/id/17120510/united-states-olympic-committee-battle-athletes-companies-sponsor-not-olympics
#10yrsago Pro-tar-sands activists say dirty Canadian oil is better because “lesbians are hot” https://www.joeydevilla.com/2016/07/26/this-ill-advised-hot-lesbians-ad-promoting-canadian-vs-saudi-oil-is-real-and-not-a-parody-by-the-onion/
#5yrsago The infosec apocalypse is nigh https://pluralistic.net/2021/07/27/gas-on-the-fire/#a-safe-place-for-dangerous-ideas
#1yrago How twiddling enshittifies your brain https://pluralistic.net/2025/07/28/twiddlehazard/#outboard-brains-considered-harmful
Upcoming appearances (permalink)
- Virtual: EFFecting Change: Who the Machine Serves, Aug 12
https://www.eff.org/event/effecting-change-who-machine-serves -
Edinburgh International Book Festival with Jimmy Wales, Aug 17
https://www.edbookfest.co.uk/events/the-front-list-cory-doctorow-and-jimmy-wales -
Sydney: The Festival of Dangerous Ideas, Aug 23-24
https://festivalofdangerousideas.com/program/ -
Melbourne: Enshittification at the Wheeler Centre, Aug 25
https://www.wheelercentre.com/events-tickets/season-2026/cory-doctorow-enshittification -
Brighton: The Reverse Centaur's Guide to Life After AI with Carole Cadwalladr (Brighton Dome), Sep 8
https://brightondome.org/whats-on/LSC-cory-doctorow-the-reverse-centaurs-guide-to-life-after-ai/ -
London: The Reverse Centaur's Guide to Life After AI with Riley Quinn (Foyle's Picadilly), Sep 9
https://www.foyles.co.uk/events/enshittification-cory-doctorow-riley-quinn -
South Bend: An Evening With Cory Doctorow (Notre Dame), Oct 6
https://franco.nd.edu/events/2026/10/06/an-evening-with-cory-doctorow/
Recent appearances (permalink)
- A Conversation with Lina Khan (Law and Economy Student
Network)
https://www.youtube.com/live/7Ak5LZllqwE -
Will AI ever come alive, and what happens if it does? (BBC News)
https://www.youtube.com/watch?v=Lzk4o3fPZZE -
Waarom jij straks het hulpje van AI bent (VPRO)
https://www.youtube.com/watch?v=tOnvR2fs8CA -
Talk Tech Bock (Vera Linß)
https://www.youtube.com/watch?v=3PFjGvQoBgc -
How To Think About AI Before It’s Too Late (This Is Hell)
https://thisishell.com/episodes/1919
Latest books (permalink)
- "The Reverse-Centaur's Guide to AI," a short book about being a
better AI critic, Farrar, Straus and Giroux, June 2026
https://us.macmillan.com/books/9780374621568/thereversecentaursguidetolifeafterai/ -
"Canny Valley": A limited edition collection of the collages I create for Pluralistic, self-published, September 2025 https://pluralistic.net/2025/09/04/illustrious/#chairman-bruce
-
"Enshittification: Why Everything Suddenly Got Worse and What to Do About It," Farrar, Straus, Giroux, October 7 2025
https://us.macmillan.com/books/9780374619329/enshittification/ -
"Picks and Shovels": a sequel to "Red Team Blues," about the heroic era of the PC, Tor Books (US), Head of Zeus (UK), February 2025 (https://us.macmillan.com/books/9781250865908/picksandshovels).
-
"The Bezzle": a sequel to "Red Team Blues," about prison-tech and other grifts, Tor Books (US), Head of Zeus (UK), February 2024 (thebezzle.org).
-
"The Lost Cause:" a solarpunk novel of hope in the climate emergency, Tor Books (US), Head of Zeus (UK), November 2023 (http://lost-cause.org).
-
"The Internet Con": A nonfiction book about interoperability and Big Tech (Verso) September 2023 (http://seizethemeansofcomputation.org). Signed copies at Book Soup (https://www.booksoup.com/book/9781804291245).
-
"Red Team Blues": "A grabby, compulsive thriller that will leave you knowing more about how the world works than you did before." Tor Books http://redteamblues.com.
-
"Chokepoint Capitalism: How to Beat Big Tech, Tame Big Content, and Get Artists Paid, with Rebecca Giblin", on how to unrig the markets for creative labor, Beacon Press/Scribe 2022 https://chokepointcapitalism.com
Upcoming books (permalink)
- "The Post-American Internet," a geopolitical sequel of sorts to Enshittification, Farrar, Straus and Giroux, 2027
-
"Unauthorized Bread": a middle-grades graphic novel adapted from my novella about refugees, toasters and DRM, FirstSecond, April 20, 2027
-
"Enshittification, Why Everything Suddenly Got Worse and What to Do About It" (the graphic novel), Firstsecond, 2027
-
"The Memex Method," Farrar, Straus, Giroux, 2027
Colophon (permalink)
Today's top sources:
Currently writing: "The Post-American Internet," a sequel to "Enshittification," about the better world the rest of us get to have now that Trump has torched America. Fourth draft completed. Submitted to editor.
- A Little Brother short story about DIY insulin PLANNING
This work – excluding any serialized fiction – is licensed under a Creative Commons Attribution 4.0 license. That means you can use it any way you like, including commercially, provided that you attribute it to me, Cory Doctorow, and include a link to pluralistic.net.
https://creativecommons.org/licenses/by/4.0/
Quotations and images are not included in this license; they are included either under a limitation or exception to copyright, or on the basis of a separate license. Please exercise caution.
How to get Pluralistic:
Blog (no ads, tracking, or data-collection):
Newsletter (no ads, tracking, or data-collection):
https://pluralistic.net/plura-list
Mastodon (no ads, tracking, or data-collection):
Bluesky (no ads, possible tracking and data-collection):
https://bsky.app/profile/doctorow.pluralistic.net
Medium (no ads, paywalled):
Tumblr (mass-scale, unrestricted, third-party surveillance and advertising):
https://mostlysignssomeportents.tumblr.com/tagged/pluralistic
"When life gives you SARS, you make sarsaparilla" -Joey "Accordion Guy" DeVilla
READ CAREFULLY: By reading this, you agree, on behalf of your employer, to release me from all obligations and waivers arising from any and all NON-NEGOTIATED agreements, licenses, terms-of-service, shrinkwrap, clickwrap, browsewrap, confidentiality, non-disclosure, non-compete and acceptable use policies ("BOGUS AGREEMENTS") that I have entered into with your employer, its partners, licensors, agents and assigns, in perpetuity, without prejudice to my ongoing rights and privileges. You further represent that you have the authority to release me from any BOGUS AGREEMENTS on behalf of your employer.
ISSN: 3066-764X
Cognyte Sells a Mobile Cell Surveillance Van [Schneier on Security]
Yet another Israeli mass surveillance company:
Made by Israeli surveillance company Cognyte, the tech simulates a mobile phone tower, which forces nearby phones to connect to it. That enables cops to keep tabs on any phones in the vicinity whether they’re owned by a suspect in a case or not. Cognyte’s contract with the state of Texas reveals that the simulator, called FalcoNet, can be concealed within the vehicles, hidden in a backpack for on-foot missions or attached to a helicopter. It’s the same technology as the infamous Stingray, one of the original cell-site simulators made by defense giant L3Harris.
10:28
Freexian Collaborators: Monthly report about Debian Long Term Support, June 2026 (by Thorsten Alteholz) [Planet Debian]

![]()
The Debian LTS Team, funded by [Freexian’s Debian LTS offering] (https://www.freexian.com/lts/debian/), is pleased to report its activities for June.
Activity summary
During the month of June, 20 contributors have been paid to work on Debian LTS (links to individual contributor reports are located below).
The team released 48 DLAs fixing 231 CVEs.
Debian 12 (“bookworm”) has been handed over to the LTS Team on June 11th. During this handover Sylvain helped to update relevant tools and documentation. If you benefit from Debian, especially during the full 5-year lifecycle, please consider subscribing as a sponsor of Debian LTS: https://www.freexian.com/lts/debian/.
Moreover, Debian 11 (“bullseye”) will reach the end of the Debian LTS period on August 31st. After that, Freexian will continue the security support under the Extended LTS offer.
The team published several notable updates:
- haveged update (DLA-4616-1), prepared by Thorsten, to address local privilege escalation.
- tomcat9 update (DLA-4619-1), prepared by Markus, to address, among others, an authentication bypass.
- apache2 update (DLA-4620-1), prepared by Bastien, to address a HTTP/2 bomb.
- apache2 update (DLA-4629-1), prepared by Bastien, to address, among others, remote code execution and privilege escalation.
- libinput update (DLA-4626-1), prepared by Santiago, to address local privilege escalation and arbitrary code execution.
- asterisk update (DLA-4631-1), prepared by Thorsten, to address, among others, wrong processing of invalid or untrusted certificates.
- nginx update (DLA-4634-1), prepared by Charles, to address a remote code execution and denial of service.
- firefox-esr update (DLA-4635-1), prepared by Emilio, to address dozens of CVEs, among other things, related to arbitrary code execution and privilege escalation.
- thunderbird update (DLA-4636-1), prepared by Emilio, to address dozens of CVEs, among other things, related to arbitrary code execution.
- chromium update (DLA-4654-1), prepared by Emilio, to address dozens of CVEs, among other things, related to arbitrary code execution.
Contributions from outside the LTS Team:
We are greatly thankful for the contributions from people outside the LTS Team:
- Salvatore Bonaccorso prepared a libhttp-daemon-perl update, that was released by Santiago as DLA-4639-1.
- Salvatore also directly uploaded libgd-perl DLA-4638-1 and libconfig-inifiles-perl DLA-4637-1.
- Peter Palfrader prepared a tor update, that was released by Santiago as DLA-4656-1.
- Pieter Lenaerts prepared a beets update, that was released by Emmanuel as DLA-4641-1.
- Noah Meyerhans prepared a cloud-init update DLA-4645-1.
The LTS Team has also contributed with updates to the latest Debian releases:
- Besides publishing DLA-4642-1 for package u-boot Andreas also prepared an NMU for an upload to sid and prepared a stable-proposed-update (SPU) bug for trixie, which was already acknowledged by a stable release manager (SRM).
- Andreas also prepared an upload of package atril for trixie, which was handled by the security team as DSA-6349-1.
- Besides publishing DLA-4620-1 for package apache Bastien also prepared an upload for trixie, which was handled by the security team as DSA-6323-1.
- Tobi uploaded package mesa to trixie and bookworm.
- Thorsten fixed some (not security related but RC) issues in package dahdi-linux. This was in preparation to fix lots of security issues in asterisk. Unfortunately the maintainer ignored the corresponding debdiff and prefered to upload a new upstream version. Anyway, the concerns of the security team about security support of asterisk could be overcome and asterisk can migrate to tesing and again be part of a Debian release.
Individual Debian LTS contributor reports
- Abhijith PA
- Andreas Henriksson
- Arnaud Rebillout
- Bastien Roucariès
- Ben Hutchings
- Carlos Henrique Lima Melara
- Chris Lamb
- Daniel Leidert
- Emmanuel Arias
- Emilio Pozuelo Monfort
- Guilhem Moulin
- Jochen Sprickerhof
- Lee Garrett
- Lucas Kanashiro
- Markus Koschany
- Santiago Ruano Rincón
- Sylvain Beucler
- Thorsten Alteholz
- Tobias Frost
- Utkarsh Gupta
Thanks to our sponsors
Sponsors that joined recently are in bold.
- Platinum sponsors:
- Toshiba Corporation (for 129 months)
- Civil Infrastructure Platform (CIP) (for 97 months)
- VyOS Inc (for 61 months)
- Gold sponsors:
- F. Hoffmann-La Roche AG (for 139 months)
- CONET Deutschland GmbH (for 123 months)
- University of Oxford (for 79 months)
- EDF SA (for 51 months)
- Dataport AöR (for 26 months)
- CERN (for 24 months)
- Silver sponsors:
- Domeneshop AS (for 144 months)
- Nantes Métropole (for 138 months)
- Akamai - Linode (for 133 months)
- Univention GmbH (for 130 months)
- Université Jean Monnet de St Etienne (for 130 months)
- Ribbon Communications, Inc. (for 124 months)
- Exonet B.V. (for 114 months)
- Leibniz Rechenzentrum (for 108 months)
- Ministère de l’Europe et des Affaires Étrangères (for 92 months)
- Dinahosting SL (for 79 months)
- Upsun Formerly Platform.sh (for 73 months)
- Moxa Inc. (for 67 months)
- sipgate GmbH (for 65 months)
- OVH US LLC (for 63 months)
- Tilburg University (for 63 months)
- GSI Helmholtzzentrum für Schwerionenforschung GmbH (for 54 months)
- THINline s.r.o. (for 27 months)
- Copenhagen Airports A/S (for 21 months)
- Conseil Départemental de l’Isère (for 7 months)
- Bronze sponsors:
- Evolix (for 144 months)
- Seznam.cz, a.s. (for 144 months)
- Intevation GmbH (for 141 months)
- Linuxhotel GmbH (for 141 months)
- Daevel SARL (for 140 months)
- Megaspace Internet Services GmbH (for 139 months)
- Greenbone AG (for 138 months)
- NUMLOG (for 138 months)
- WinGo AG (for 137 months)
- Entr’ouvert (for 129 months)
- Adfinis AG (for 126 months)
- Plat’Home (for 122 months)
- Laboratoire LEGI - UMR 5519 / CNRS (for 121 months)
- Tesorion (for 121 months)
- Bearstech (for 112 months)
- LiHAS (for 112 months)
- Catalyst IT Ltd (for 107 months)
- Demarcq SAS (for 101 months)
- Université Grenoble Alpes (for 87 months)
- TouchWeb SAS (for 79 months)
- SPiN AG (for 76 months)
- CoreFiling (for 72 months)
- Observatoire des Sciences de l’Univers de Grenoble (for 63 months)
- Tem Innovations GmbH (for 58 months)
- WordFinder.pro (for 57 months)
- CNRS DT INSU Résif (for 56 months)
- Soliton Systems K.K. (for 51 months)
- Alter Way (for 49 months)
- SOBIS Software GmbH (for 24 months)
- Tuxera Inc. (for 15 months)
- OPM-OP AS (for 7 months)
- LU-CIX Management G.I.E.
10:21
Optimizing yourself into a corner [Seth's Blog]
Organizations thrive on incremental improvement. They find a stable foundation and then build a feedback loop of relentless improvement.
This leads to great efficiency, higher productivity and more profits. It enables more throughput and builds market share.
Except things change.
Optimized offerings are brittle. When the foundation shifts, all of that incremental improvement breaks into shards.
When the dust settles, the optimized alternative is almost always surpassed by the resilient one.
08:49
A Wolv In Creep's Clothing [Penny Arcade]
New Comic: A Wolv In Creep's Clothing
08:42
Iranian girls' school attack [Richard Stallman's Political Notes]
When a US missile hit an Iranian girls' school, the CIA at first said that the missile in the photos did not look like an American missile. A day later they corrected that and said it indeed was one. But he stuck to the appealing but impossible claim that Iran had fired it.
I'm pretty sure the US military did not choose to attack that building knowing it had been carved out of the adjoining naval base and converted into a school. Even a monster who cared nothing about killing Iranian civilians would have sought to avoid the bad publicity that would result. Meanwhile, the circumstances, including the pressure to attack fast, facilitated such mistakes.
The tendency for belligerent acts to cause unintended consequences due to ignorance of facts is called the "fog of war". It is inescapable: war implies mistakes with consequences, no matter how much one tries to avoid them. The implication of that is, one should try hard to choose a path other than war.
Juan Jairo Coronilla Durán [Richard Stallman's Political Notes]
Deportation thugs approached Juan Jairo Coronilla Durán, a Mexican tourist, and terrified him so much that he ran away into traffic and was killed by a truck.
Coronillo had a valid tourist visa, so if our legal system were functioning properly he should not have felt threatened by them. But our legal system has been messed up intentionally by magats to the point that no one can be confident of safety around them.